

{kind=link}
Enterprises that want to migrate from a SQL Server database engine to Amazon Aurora PostgreSQL-Compatible Edition typically convert the database schema from one database to another, then take data from the first database and load it into the target database. This process tends to be error-prone and requires quite a bit of work after the migration. Developers still need to change the application to use the target database’s drivers, rewrite stored procedures and rewrite internal application code to make it all work.
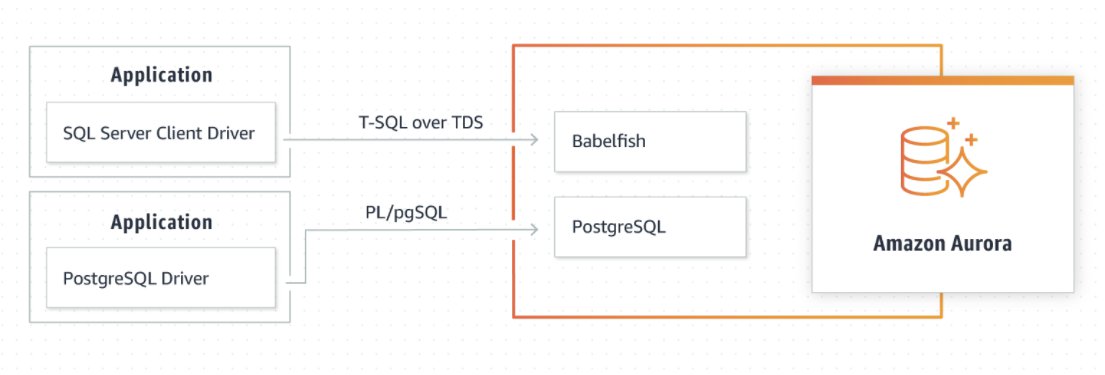
Babelfish for Aurora PostgreSQL understands T-SQL, Microsoft SQL Server’s proprietary SQL dialect, and supports the same communications protocol, so your apps that were originally written for SQL Server can now work with Aurora PostgreSQL with fewer code changes.
In technical terms, Babelfish provides native, semantically correct execution of T-SQL over the TDS wire protocol, by default on port 1433, plus native SQL Server data types and runtime library support.
Babelfish is an optional capability and doesn’t have an additional cost. You can enable Babelfish on your Aurora cluster via the AWS Management Console. In this post, we show you how to create a Babelfish cluster and connect to the database.
Solution overview
Babelfish implements support for commonly used SQL Server features, which enables your legacy applications to communicate with Aurora without extensive code rewrites. The following diagram illustrates this architecture.
{kind=link}
In this post, we walk you through the following high-level steps:
Create a Babelfish cluster.
Connect to a Babelfish-enabled database.
Choose which SQL client to use to connect to the database.
Query Babelfish to find various information.
Use a PostgreSQL application to connect to the cluster.
Create a Babelfish cluster
To create a Babelfish cluster, we use the Amazon Relational Database Service (Amazon RDS) console. Complete the following steps:
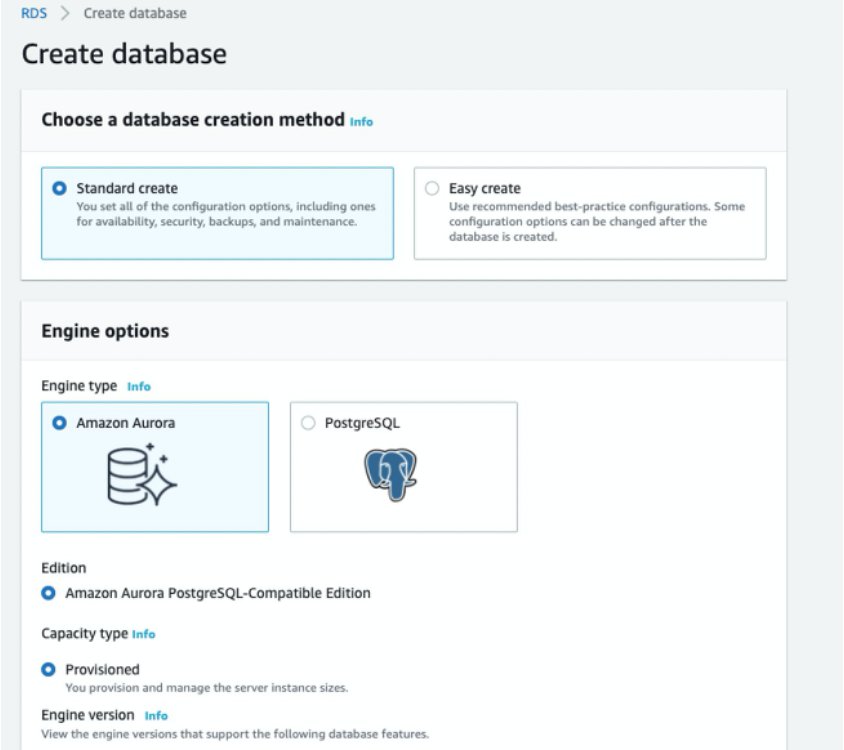
On the Amazon RDS console, choose Create database.
Select Standard create.
For Engine type, select Amazon Aurora.
For Edition, select Amazon Aurora with PostgreSQL compatibility.
For Engine version, choose Show versions that support the Babelfish for Aurora PostgreSQL feature.
{kind=link}
{kind=link}
This filters the list for engine types that support Babelfish.
For Available versions, choose the most recent version.
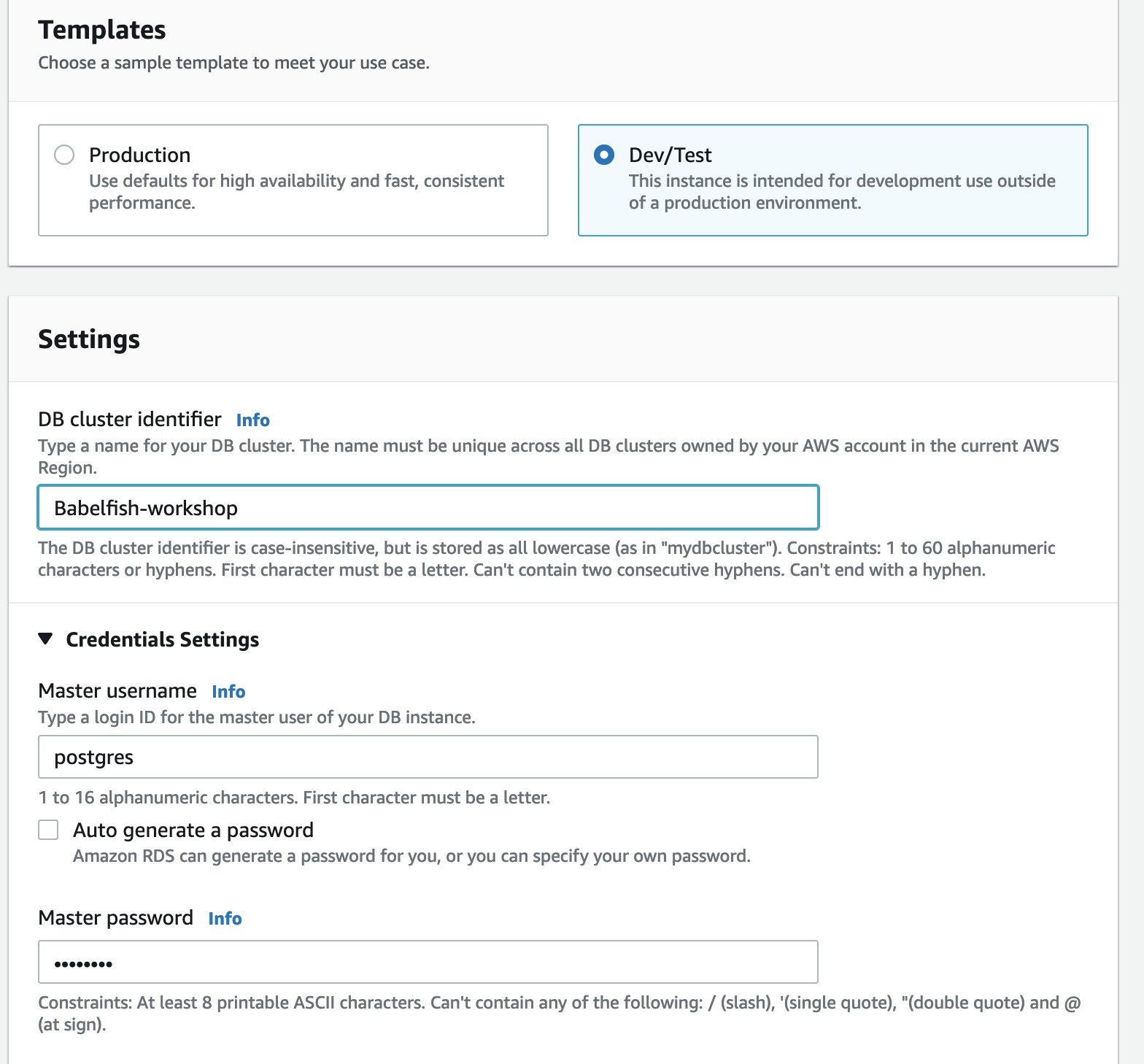
For DB cluster identifier, enter your DB cluster name.
Under Credential Settings, enter an administrator user name and password.
{kind=link}
In SQL Server, the sa login is the only login in a new instance. If you want sa in Babelfish as well, specify sa here.
{kind=link}
For the fields that follow, until the Babelfish settings section, specify your DB cluster settings or you can leave it with defaults.
For more information about cluster creation, see Creating an Amazon Aurora DB cluster.
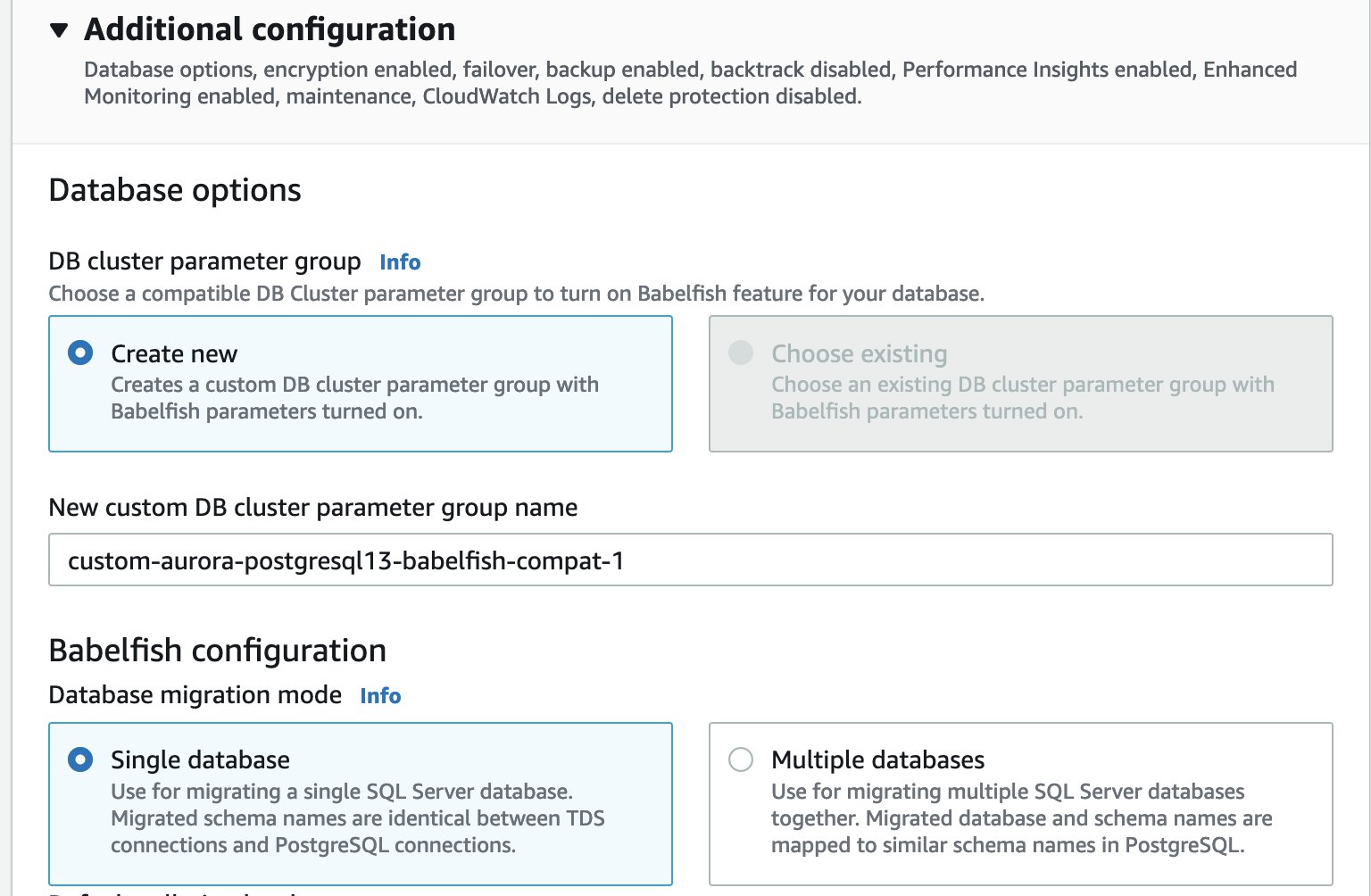
Select Turn on Babelfish.
For Database migration mode, select your preferred mode (for this post, we select Single database).
{kind=link}
For considerations about each mode, check out Working with Babelfish for Aurora PostgreSQL.
{kind=link}
Provide the port number that Babelfish monitors for T-SQL commands in the Babelfish TDS port field. The default port is 1433.
To have public access to your Babelfish cluster from outside your VPC, enable the option Turn on Public Access.
Remember to select the correct Security Group.
Optionally, choose Enable Performance Insights to turn on Amazon RDS Performance Insights.
Choose Enable Enhanced monitoring to start gathering metrics in real time for the operating system that your DB cluster runs on.
Choose PostgreSQL log to publish the log files to Amazon CloudWatch Logs.
Choose Create database.
Note: Performance Insights and Enhanced Monitoring are useful for collecting usage data. However, some AWS users may not have security permissions set to access these features. If you get an error when creating your database, try disabling Enable Performance Insights and disabling Enable Enhanced Monitoring.
The database creation takes a few minutes to complete.
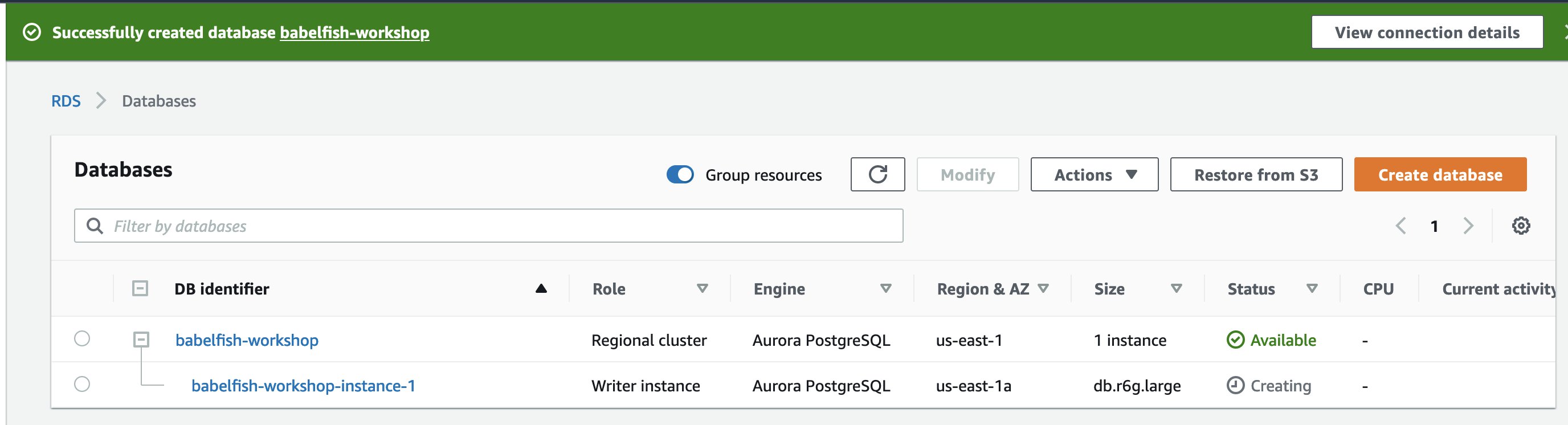
You can find your new database set up for Babelfish on the Databases page. The Status column displays Available when the deployment is complete. The status updates automatically without requiring you to refresh the page.
{kind=link}
You must allow the new Babelfish port in this security group in order to connect.
Connect to a Babelfish enabled database
SQL Server-compatible traffic connects to the Babelfish-enabled database on port 1433. This allows your existing code to run as is. For more information about connecting to an Aurora PostgreSQL database, see Creating a DB cluster and connecting to a database on an Aurora PostgreSQL DB cluster.
To find your database endpoint, complete the following steps:
Open the Amazon RDS console for Babelfish.
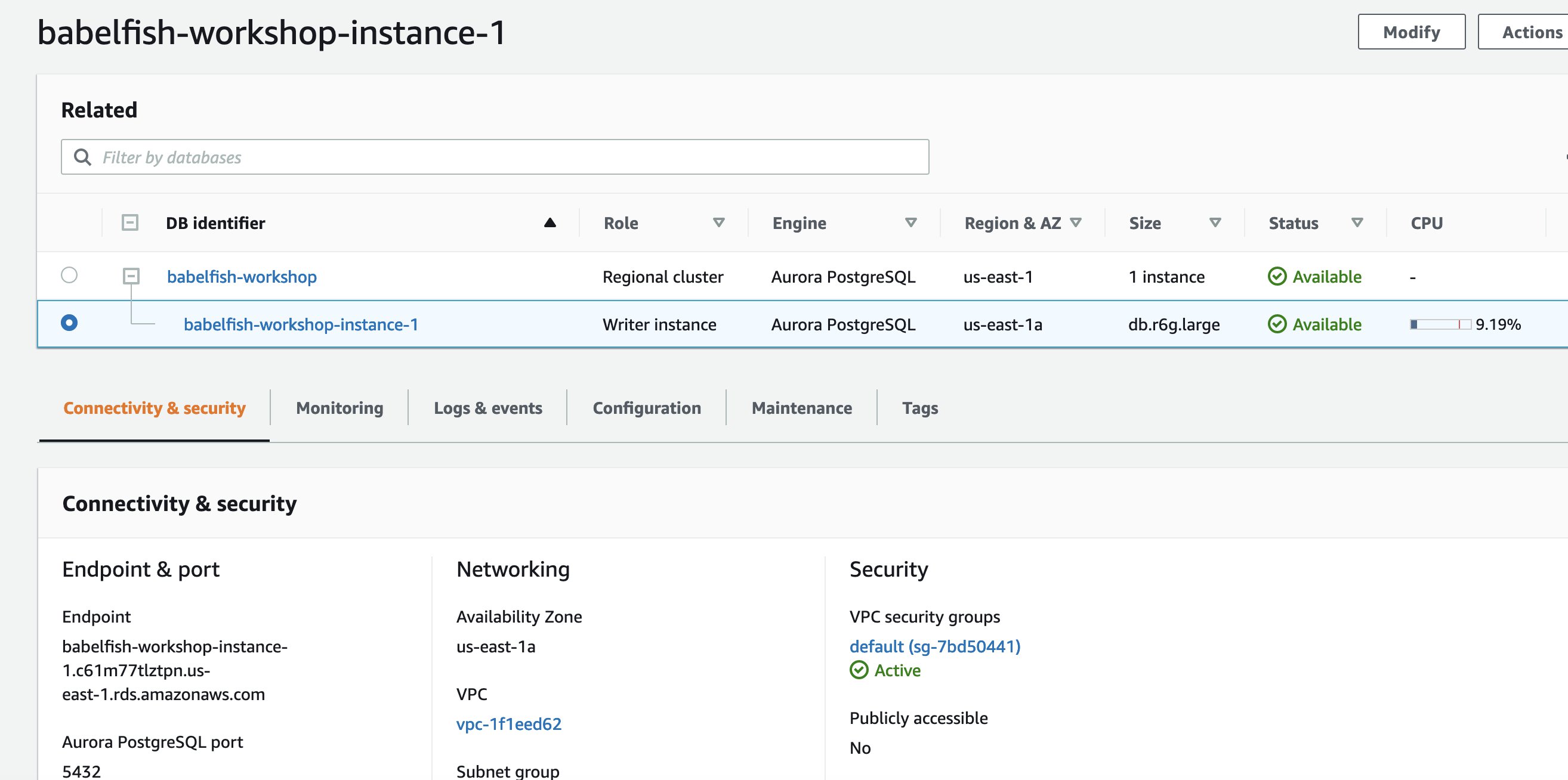
Choose your Babelfish-enabled database cluster to show the DB cluster details.
On the Connectivity & security tab, note the instance endpoint.
Use this instance endpoint in your JDBC and ODBC connection strings for applications that perform database write or read operations.
{kind=link}
Choose your SQL client to connect to the Babelfish database
It’s now time to choose what software you want to use to connect to the Babelfish database. There are many options, but the following are two of the most common clients used to connect to Babelfish:
sqlcmd – The command-line connection tool.
The Query Editor in SSMS – SSMS is a GUI-based client tool to connect to SQL Server. In SSMS, you can currently only connect with the Query Editor and not the Object Explorer.
Use sqlcmd to connect to the DB cluster
You can connect to and interact with an Aurora PostgreSQL DB cluster that supports Babelfish with the SQL Server sqlcmd command line client. The following code shows a connection example:
The value for the -S argument is the endpoint port (optional) of the DB instance.
{kind=link}
Use SSMS to connect to the DB cluster
You can connect to your Aurora PostgreSQL database by using SSMS, and then use the Query Editor to connect to a Babelfish database.
Warning
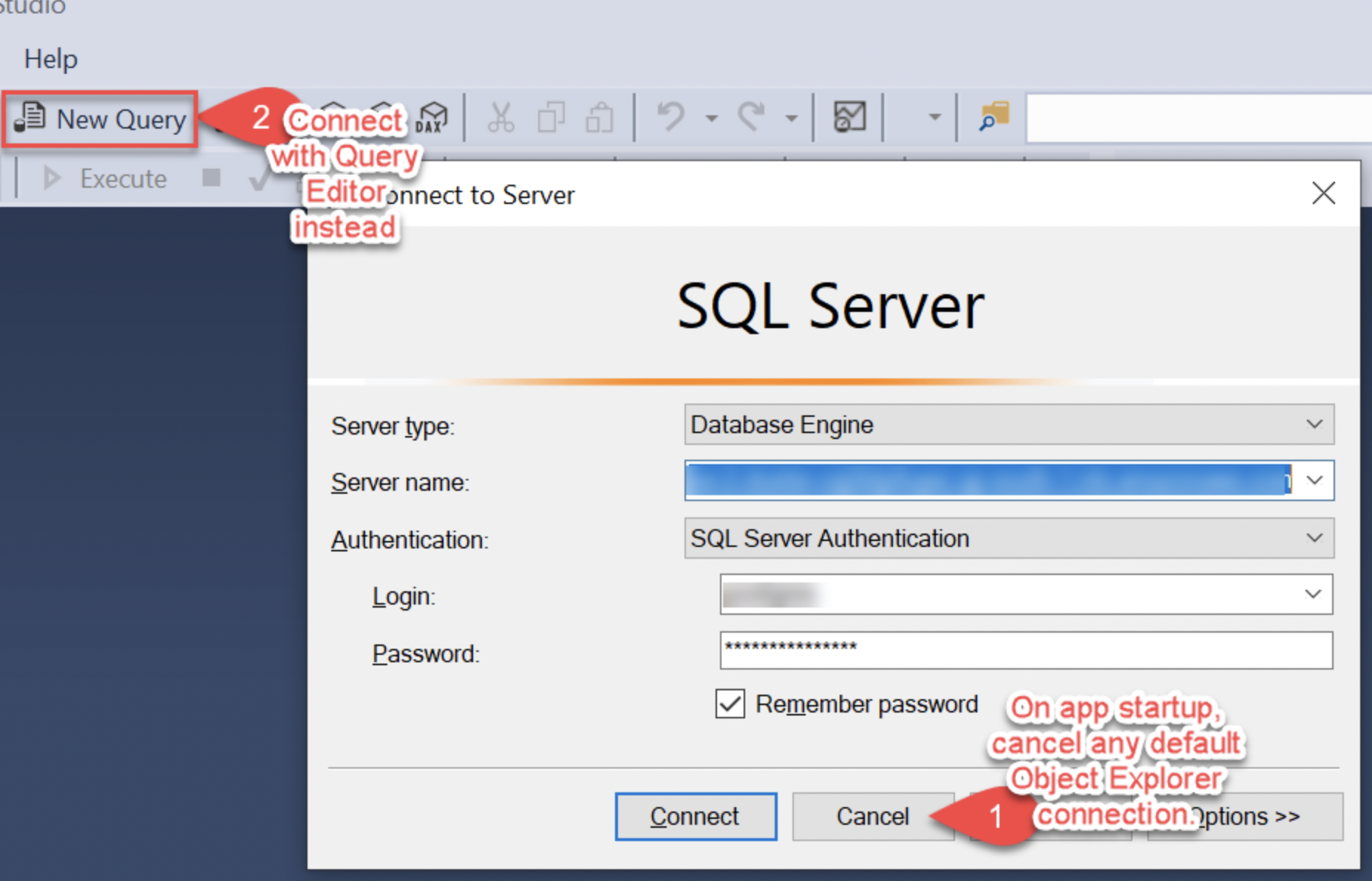
Babelfish supports connecting to SSMS via the New Query option and not via Object Explorer. When you launch SSMS, make sure to close the default Connect window and then connect via the Query Editor by choosing New Query. If you don’t connect via the Query Editor, you will run into an error.
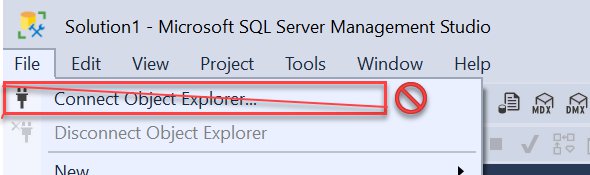
After starting SSMS, if you see a Connect dialog box by default, choose Cancel. This is because the startup Connect dialog connects via Object Explorer, which generates a login error.
{kind=link}
Do not try to connect with Object Explorer.
{kind=link}
Choose New Query (the only option supported as of this writing). You will then find the correct Connect to Server dialog.
If the Query Editor is open, choose Query, Connection, and Disconnect, and then Connect.
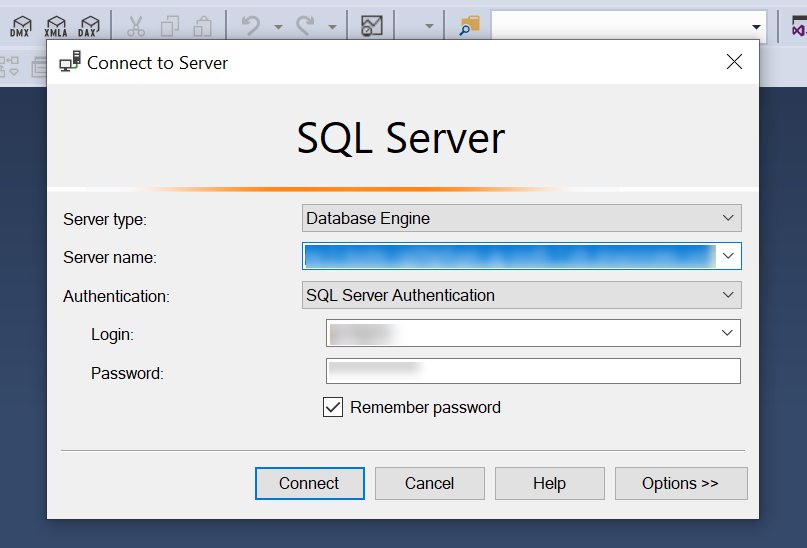
For Server type, choose Database Engine.
For Server name, enter the DNS name. For example, your server name should look similar to the following:
{kind=link}
{kind=link}
For Authentication, choose SQL Server Authentication.
For Login, enter the user name that you used when you created your database.
For Password, enter the password that you used when you created your database.
Click Connect to connect to your Babelfish instance.
{kind=link}
Query Babelfish
After connecting to the server, you can connect to Babelfish to find various information.
Query the TDS listener port (by default, port 1433) to identify the Babelfish version that you’re connected to.
Enter SELECT SERVERPROPERTY(‘Babelfish’) to find out if an application is running on Babelfish.
{kind=link}
The function returns 1 if running on Babelfish, and NULL if running on SQL Server.
Enter SELECT SERVERPROPERTY(‘BabelfishVersion’) to find the Babelfish version number.
Enter SELECT AURORA_VERSION() to return the Aurora PostgreSQL version.
You can also connect to the Aurora PostgreSQL listener port (by default, port 5432) to find out information about Babelfish.
Connect to the babelfish_db database.
Enter SHOW rds.babelfish_status to find out if Babelfish is turned on.
Enter SELECT sys.SERVERPROPERTY(‘BabelfishVersion’) to find the Babelfish version number.
Use a PostgreSQL application to connect to the DB cluster
You can also access the database tables and data created by Babelfish from a native PostgreSQL connection. You can access your database simultaneously using a Babelfish connection in one application and a native PostgreSQL connection in the same or another application. You connect to the Babelfish_db database from PostgreSQL by using the Aurora PostgreSQL endpoint on port 5432. For details about connecting to a DB cluster using Aurora PostgreSQL, read Connecting to an Amazon Aurora PostgreSQL DB cluster. For an example of connecting using psql, visit Connecting to an Aurora PostgreSQL cluster using psql.
In addition, Babelfish for PostgreSQL is open-source, so you have the freedom to use it on-premises, outside of AWS. Babelfish is open-sourced under the Apache 2.0 License and the PostgreSQL license.
Summary
In this post, we showed you the steps involved in creating Babelfish for Aurora PostgreSQL and how to connect to the Babelfish database to query the server properties and its version information using different clients like sqlcmd and the SSMS Query Editor. Babelfish accelerates the migration from legacy SQL Server databases because you don’t have to convert database schemas and database objects, or rewrite parts of the application code or SQL dialect conversion—Babelfish does most of that for you.
Now that you know how to get started with Babelfish, you’re ready to migrate your data from SQL Server to Aurora using Babelfish.
About the Author
Neha Gupta is a Solutions Architect at AWS and have 16 years of experience as a Database architect/ DBA. Apart from work, she’s outdoorsy and loves to dance.
{kind=link}
Ramesh Kumar Venkatraman is a Solutions Architect at AWS who is passionate about containers and databases. He works with AWS customers to design, deploy and manage their AWS workloads and architectures. In his spare time, he loves to play with his two kids and follows cricket.
{kind=link}
Read MoreAWS Database Blog