

{kind=link}
Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications with highly connected datasets. You can use Neptune to build fraud detection, entity resolution, product recommendation, and knowledge graph applications. Built on open standards, Neptune enables developers to use three popular open-source graph query languages with millisecond latency: Apache TinkerPop Gremlin, RDF/SPARQL, and openCypher.
A Neptune cluster consists of a primary writer instance and up to 15 read replicas (each replica is an instance). Neptune read replicas are used to distribute workloads across multiple servers to increase database throughput, and when replicas are located in different Availability Zones, they increase database availability. Customers have asked us for an auto scaling capability in Neptune to manage and reduce operational overhead when dealing with unpredictable, demanding workloads.
You can now use auto scaling in Neptune to automatically add or remove read replicas in response to changes in performance metrics. Neptune auto scaling works with Amazon CloudWatch to continuously monitor performance metrics of read replicas. In this post, we outline how to configure Neptune clusters to automatically scale in or out to manage workloads by using CloudWatch metrics such as CPUUtilization. There is no additional cost to use Neptune auto scaling beyond what you already pay for Neptune read replicas and CloudWatch alarms.
Solution overview
Previously, you had to configure Neptune clusters for peak capacity by deploying a fixed number of read replicas to manage incoming queries. When demand changed, you had to manually adjust the number of replicas to meet demand. This requires you to either anticipate workload demand and manually add and remove read replicas, or build a custom solution using CloudWatch metrics and AWS Lambda triggers to scale read replicas. In either case, over-provisioning capacity leads to spending more money than necessary, and under-provisioning capacity risks low performance for your peak workloads. With the introduction of auto scaling in Neptune, you can now automate this process and scale read replicas based on workload demands without the need to anticipate demand or build self-managed solutions.
With auto scaling, you can scale read replicas seamlessly. You can now configure the auto scaling feature in Neptune within minutes, eliminating the need to monitor or manually scale read replicas in or out.
Register your Neptune cluster
To configure auto scaling, your Neptune cluster should have at least one reader instance and one writer instance already deployed. After they’re deployed, you need to register the cluster with Neptune auto scaling using the following AWS Command Line Interface (AWS CLI) command:
Your capacity should be between 1–15. If min-capacity is larger than the current number of readers, the command triggers the scaling activity to add replicas to your cluster.
After you register the cluster, check the registered scalable targets by using the following command:
The following screenshot shows our output.
{kind=link}
Define a scaling policy
Next, you define a scaling policy through the auto scaling APIs. The policy specifies the threshold (TargetValue) for the CloudWatch metric, which auto scaling monitors in order to scale the cluster.
The system detects whether the threshold for the CloudWatch metric has been reached. When that occurs, the system calls a Neptune API to increase or decrease the number of replicas. When the workload decreases, Neptune auto scaling removes read replicas so that you don’t pay for over-provisioned database instances. Auto scaling only removes read replicas that it creates. It doesn’t delete preexisting read replicas.
The following is a sample policy document using predefined metrics:
After you create an auto scaling policy, you attach the policy to the scalable target (your cluster) using the following command:
The following screenshot shows our output.
{kind=link}
This sets up two CloudWatch alarms to track the CPUUtilization Neptune metric for auto scaling:
AlarmHigh to trigger scaling out
AlarmLow to trigger scaling in
You can review the details about these alarms on the CloudWatch console.
{kind=link}
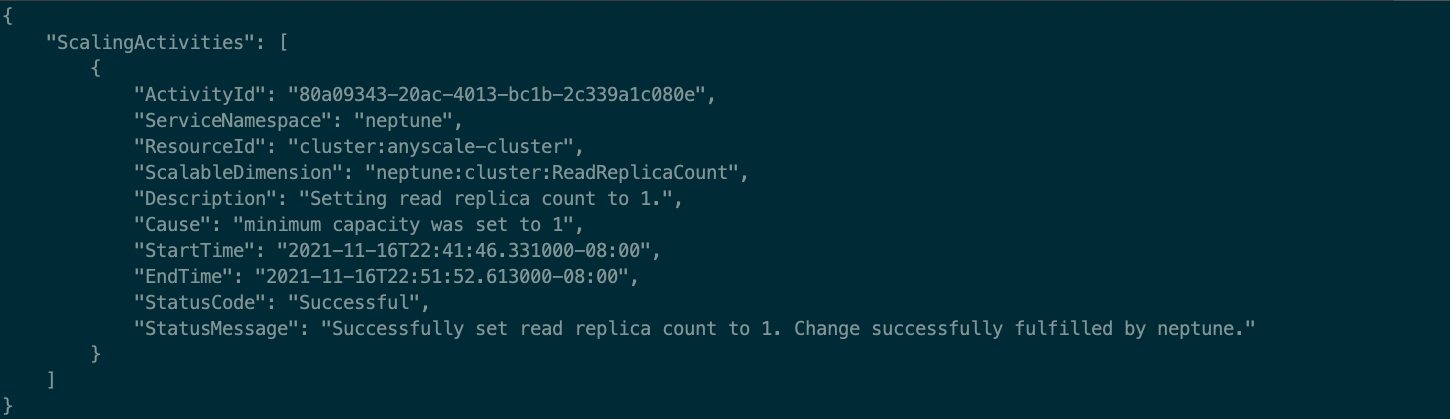
You can check the scaling activities triggered on your cluster with the following code:
The following screenshot shows our output.
{kind=link}
Update parameters
You can also customize your read replicas that are added through a scaling activity. You can control one or all of the following configurations for the auto scaled read replicas:
DB instance type
Maintenance window
Tags by updating the neptune_autoscaling_config parameter
All read replicas added after the parameter update use these configurations. If the parameter is not set, the readers pick their configurations from the primary writer instance. For more information about updating cluster parameter groups, see Amazon Neptune parameter groups.
If using the console, you can update the parameter to the following:
If updating through the AWS CLI, use the following code:
You can also trigger a scaling activity at a predefined time to handle predictable workloads using scheduled scaling.
If you want to update the CloudWatch metric’s threshold value, you can attach a new policy document to the Neptune cluster using the put-scaling-policy API, as described earlier. If you no longer want your cluster to be tracked through CloudWatch triggers, you can remove the scaling policy with the following command:
You can also remove the Neptune cluster as a scalable target if you no longer need to maintain minimum or maximum capacity limits on your Neptune cluster through the auto scaling feature:
Conclusion
The auto scaling feature in Neptune enables you to reduce operational overhead and save costs by deploying the right amount of read replicas needed for handling demanding workloads. For more information about this feature, see Auto-scaling the number of replicas in an Amazon Neptune DB cluster.
If you have any questions, comments, or other feedback, share your thoughts on the Amazon Neptune Discussion Forum.
About the Authors
Navtanay Sinha is a Senior Product Manager at AWS. He works with graph technologies to help Amazon Neptune customers fully realize the potential of their graph database.
Sudhanshu Gupta is a Software Development Engineer with Neptune at AWS. He works on the Control Plane orchestrating complete lifecycle for Neptune clusters and implementing enterprise-grade solutions.
{kind=link}
Read MoreAWS Database Blog