

{kind=link}
In this post, I demonstrate how to optimize querying a large amount of data in Amazon DynamoDB by using parallelism – splitting the original query into multiple parallel subqueries – to meet these strict performance SLAs for large DynamoDB database queries.
During our engagements with customers, we often need to retrieve a large number of records from DynamoDB databases. I’ve worked with a number of projects where we needed to process data for the purpose of key performance indicator (KPI) calculations or to make business decisions based on the data insights. In most cases, those processes are the backend for the APIs, therefore the processing times are usually subsecond. DynamoDB delivers single-digit millisecond read/write performance by default, but some use cases require the same fast response time even when querying a very large number of records.
DynamoDB is a key-value and document database that offers several methods for retrieving a large number of records using Scan and Query operations. The Scan operation inspects every item in a table or secondary index, and the Query operation retrieves data within an item collection. This difference means that Query operations are faster than Scan operations when evaluating large blocks of data.
In addition to discussing how to optimize DynamoDB queries for large amounts of data, I’m going to show you how to use some of the new Java 8 features to make this approach work even better. I discuss a few modern Java concepts, like Java streams (regular, parallel, and reactive), parallelism, multithreading, and the reactive programming paradigm. I analyze the pros and cons of various approaches, and share code samples for both the AWS SDK for Java and AWS SDK for Java 2.x. The walkthrough is intended for Java developers of all experience levels.
Note: You can use the parallel Scan method to optimize the Scan operation. This approach can improve scan performance, but requires additional table throughput capacity. For more information comparing the performance and cost between Query and Scan retrieval operations, see Best Practices for Querying and Scanning Data.
Solution overview
One approach to optimizing a Query operation involves splitting a large query task into multiple smaller tasks that can each be completed in significantly less time. In this solution, I achieve overall faster performance by running parallel subqueries in multiple threads. Using this approach, the total duration of the query operation is close to the duration of the slowest subquery.
The approach is based on well-known paradigms like MapReduce, divide and conquer, and split-apply-combine.
Create subqueries
To create efficient subqueries, you start by splitting large single queries into several subqueries. This post shares some helpful tips that use both partition keys and sort keys.
To illustrate the approach, I use an orders table that uses id as a primary key. Some of the main attributes are product ID (sku), product category (category), order date (order-date), quantity sold (qty), and price per unit (unit-price), as shown in the Figure 1 that follows.
{kind=link}
To prepare the solution, I used the DynamoDB console to create the table and assign a name and primary key.
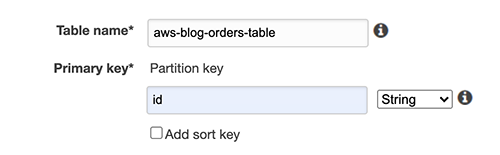{kind=link}
I then added a global secondary index with category as the partition key and order-date as a sort key.
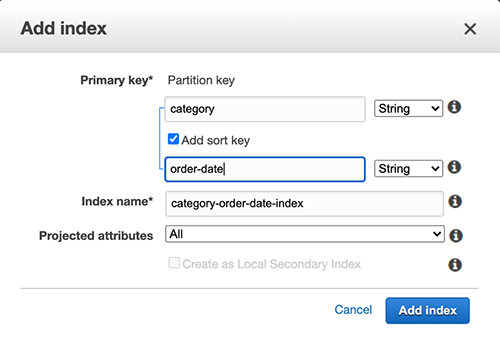{kind=link}
The last step was to add some test data into the table.
{kind=link}
As an example, let’s say you want to query all the data for the year 2020 (order-date needs to match the year that you’re searching for) and with the category value equal to SPORT. My approach is to split this query into several uniformly sized subqueries, such as per month. In this case, I have 12 subqueries that can be run in parallel. The assumption is that orders were somewhat uniformly distributed throughout the year, although this doesn’t need to be exact, order of magnitude is fine.
The preceding example uses the following query, which has syntax similar to that of the AWS Command Line Interface (AWS CLI):
For this case, I use order-date prefixes – denoted as the :v2 value placeholder in the preceding code – such as 2020-01, 2020-02, and so on. Similarly, :v1 holds, as an example, SPORT as a category to include in the query.
In addition to those 12 subqueries, I experimented with the following:
48 parallel subqueries, such as 2020-01-0, 2020-01-1, 2020-01-2, and so on, which added four more subqueries per month.
365 (or 366) subqueries, one per day.
If there isn’t a suitable sort key that can be used to evenly split the subqueries, an option is to generate a new column that contains the modulo value of some numeric sequence (I had a sequence value incremented as I generated the test data). Another idea is to use nano-time when data is inserted in the database. The value that you use the mod (modulo) function for should be equal to the number of the intended subqueries. For this case, I have 64 query slots. Depending on your situation, you can create several query-slot attributes, for example 32, 64, and 128 slots, depending on your use case. Just mod your numeric sequence or nano-time value with your required slot size. Depending on the data, this method could more uniformly split the data than the using the order date (this should be validated on your actual data and the query pattern).
For brevity, the remainder of this post discusses order-date implementation. You can download the code for implementing either the order-date or mod approach from GitHub.
Parallelize your subqueries
There’s more than one way to parallelize subqueries. It can be done within the same process using multithreading, or you can use multiple processes, either on the same host or across a distributed environment. In the solution that follows, I focus on a single process with a compute environment that has multiple cores (found in most computing environments). Having multiple cores allows for truly parallel queries, where each core can run a task without interruption.
Note: For more about concurrency compared to parallelism, see From concurrent to parallel: Understanding the factors influencing parallel performance.
As per the previous section, the solution uses tasks that are independent of each other and can run simultaneously. This type of workload is commonly referred to as an embarrassingly parallel problem and can be solved using the approach discussed in this post.
Before I discuss the multithreading mechanics of this solution, it’s important to discuss the type of tasks related to the CPU and I/O use. A compute process that relies on a high degree of CPU utilization is referred to as a CPU-bound process. In contrast, an I/O-bound process is limited by the amount of time it takes I/O operations to complete. Calling a remote service to perform a task—such as a DynamoDB query—is an example of an I/O-bound process.
Typically, for CPU-bound processes, the number of threads you allocate should be no more than the number of cores less 1. For example, for a 16-core environment, not shared with any other processes, you can create up to 15 threads, in addition to the main process thread, to run your parallel tasks. But in I/O-bound workloads, you can safely create many more threads than the number of cores, because the cores mostly wait for the remote service to complete its tasks.
The following discussion is Java based, but you can apply the same concepts to other programming languages.
Implementation
In this section, I discuss implementing a solution through threading with Java and using a CompletableFuture asynchronous framework to run subqueries concurrently.
Java and threading
Java offers several methods to construct a multithreading solution, including:
The basic thread class.
Managed thread pools using the ExecutorService interface.
The CompletableFuture class.
Each option offers advantages and disadvantages. Some methods are easier to code but have fewer capabilities, whereas others might require more knowledge and coding efforts. Your chosen approach should balance between complexity and flexibility, making the solution relatively easy to implement while achieving your performance goals.
Starting in Java 8, designers of Java added the Java Stream feature, which improves the readability and simplicity of code that uses iterations. In addition, they added parallel streams, which simplify using multithreading.
It should be noted that Java 8 parallel streams use the common ForkJoin thread pool. The number of threads available in the common ForkJoin pool is 1 fewer than the number of cores. You can increase the size of the thread pool, but doing so changes the pool size for all other code instances that use the common ForkJoin threading approach and so should be implemented cautiously.
The creation of sub-queries using the order-date method, which uses year-month values, is shown in Figure 5 that follows. Figure 5 shows a primary query to find all records where category is SPORT being split into multiple subqueries based on month. The results of the subqueries are then combined into a single result.
{kind=link}
You can use the design shown in Figure 6 that follows to code the above solution using parallel streams to collect orders.
Create a list of query parameters and decide on the logic you want to use to split the query into subqueries.
Run the subqueries in parallel to build the data stream.
Call the sub-query for each query parameter.
Flatten the subquery results into a single stream of all orders.
Collect the results.
Return a list of all orders that match the query.
{kind=link}
The following code shows implementation of multiple parallel streams to collect orders:
Here’s the code for the primary DynamoDB query used to list orders:
Important: To design the optimal solution for the approach discussed in this post, you must consider several things when choosing your strategy for splitting data, such as:
Total amount of data that the query runs against (thousands, millions, or billions of records).
Type of compute environment (smaller or larger number of cores).
Type of subqueries (searching by string prefix or by numeric value).
Number of subqueries.
Potential uniformity of the data size for each subquery.
Number of threads available to use for a given compute environment.
There are additional performance considerations, such as record size (number of fields returned by the query) and filter expressions applied to the queried records.
During testing, I observed that using the common ForkJoin thread pool with parallel stream implementation had suboptimal performance with large numbers of parallel queries, because the number of queued tasks waited for threads to be available. In this case, having more cores is a significant boost for the overall solution performance, especially when the processes are I/O bound.
The next tool in the Java toolset is completable futures, a reactive and asynchronous functional framework that lets you provide the custom thread pool. Completable futures allow you to create as many threads as make sense for the environment and for the problem that you need to solve. In addition, it’s important to know that the SDK for Java v2 heavily uses completable futures and reactive streams. I discuss the SDK v2 later in this post.
CompletableFuture asynchronous framework
The CompletableFuture class is a relatively new paradigm for Java. It was introduced in Java 8 and has about 50 different methods for composing, combining, and running asynchronous computation steps and handling errors. Its use of CompletionStage, which supports dependent functions and actions that trigger upon its completion, is especially useful.
The code I used for querying and splitting the data into 12 monthly collections is similar to the following:
The code shows a simple Future collect step, but for a better approach, see Understand Advanced Java Completable Future Features: Implementing FuturesCollector by Douglas C Schmidt.
I opted to create my own ForkJoin pool thread, with the number of threads matching the number of subqueries—12, 48, or 365 for order-date approach or 64 for query-slot case. I use the same subquery code that I used for the parallel stream implementation.
The preceding code does the same thing whether I use the order-date or query-slot-mod64 method:
Provides criteria for splitting the data (like date prefixes or query-slot values).
Iterates through each value and submits asynchronous subqueries.
Returns a list of completable futures.
Joins all futures and waits for their completion.
Flattens all results and collects the final list of orders.
Although I show only the basic operations with the returned list of orders in this post, you could process each result in the same thread by using the already established thread pool and CompletableFuture staging methods.
Testing results
In this section, I discuss my methodology, testing results, and the SDK for Java v2.
Methodology
I populated the DynamoDB table with approximately 270,000 records. The following is an example of an orders record:
I then ran nine different test cases:
Single query without any splitting into subqueries.
Parallel stream approach using a common ForkJoin pool for 12, 48, and 365 subqueries, as discussed previously.
One parallel stream test using the query-slot-mod64 attribute to create 64 subqueries.
Sequential stream approach using CompletableFuture with a ForkJoin thread pool for 12, 48, and 365 subqueries, as discussed previously.
Sequential stream approach using CompletableFuture with the user’s provided ForkJoin thread pool using the query-slot-mod64 attribute and 64 subqueries.
I ran each test case 10 times and averaged the total time per case. I ran each test using two setups:
A basic Amazon Elastic Compute Cloud (Amazon EC2) setup.
A more robust Amazon EC2 setup similar to what might be used in a production environment.
For the basic test, I used a t2.xlarge EC2 instance with 4 vCPUs and 16 GB of RAM. For a better representation of a real production environment, I used a m5.24xlarge EC2 instance with 96 vCPUs and 384 GB of RAM. Implementation using parallel streams and common ForkJoin relied on the underlying thread pool size, whereas CompletableFuture implementation was optimized for the number of threads required by the test case.
Results and observations
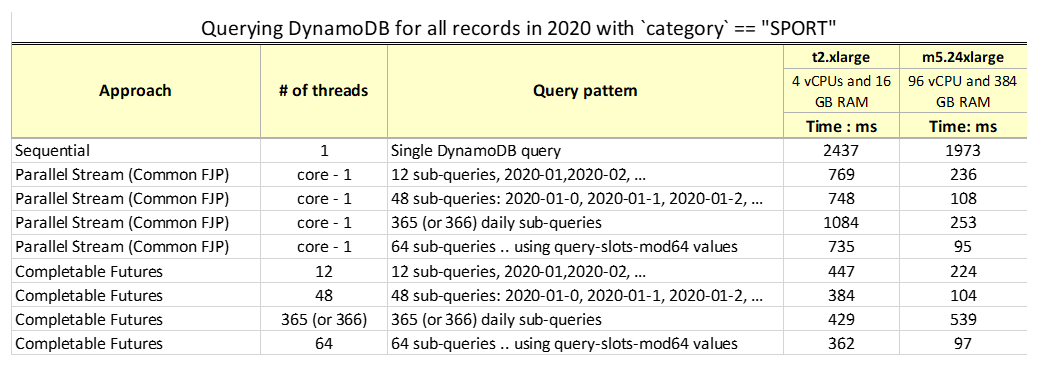
The following table summarizes the results of querying a DynamoDB table for all records in 2020 with the category SPORT.
{kind=link}
Although the results are intuitive, you might find the following observations helpful when you try the solution with your data:
The performance of a single query is much slower—in some cases almost 20 times slower—than using parallelism with subqueries.
Even the most constrained environments perform better with parallelism than with single threading.
Note: Your AWS Lambda functions might also benefit from this parallelism.
Comparing environments with constraints to robust environments—such as environments that have more cores—shows significantly greater.
A large number of subqueries can reduce performance on less powerful machines with a common ForkJoin thread pool implementation, as shown with the t2 machine and 365 threads.
Specifying the number of threads in the thread pool can help improve performance even in a constrained environment (such as the t2 environment).
On more powerful EC2 instances, parallel streams with a common ForkJoin pool have similar performance results as using CompletableFuture and a user-defined thread pool size. This was evident in the test with 96 vCPUs where most of the cases required fewer CPUs, therefore common ForkJoin had no disadvantages compared to the approach in which you choose the size of the thread pool.
Numeric sort key comparison is faster than using the order-date prefix when comparing with the begin_with() function.
For our data size and test cases, all environments perform best with a thread pool size between 48 and 64.
Modulo query patterns that have assigned query slot values might perform better in cases where the live data is distributed unevenly (such as seasonal changes like holiday shopping) but uniform distribution is desired to optimize the performance of multiple parallel subqueries.
Your DynamoDB system needs to be properly sized in regards to read capacity and throughput. Building for more parallelism can have cost implications.
Overall, the results obtained using a multithreading approach are impressive, regardless of the underlying environment. Having 270,000 records returned in 100 to 360 milliseconds is a respectable result for most use cases.
AWS SDK for Java v2
Although I mostly discussed the SDK for Java v1 in this post, now’s a good time to talk about new ideas brought in by the reactive programming paradigm and the AWS SDK for Java v2 that you can use in the future. In this post, I don’t go into the details of reactive programming concepts because plenty of literature is available on this topic, but in this section, I share an example of how to use a push model, and how to use asynchrony to get the data from DynamoDB.
The new AWS SDK for Java 2.x offers APIs that implement reactive streams and an observable interface, which allows the consumer of events and data to subscribe to the stream, thereby removing the need to poll the service provider for the events or data. For examples of this paradigm, see the AWS SDK for Java v2 GitHub repository.
For our example, I used the following code to create an asynchronous version of the DynamoDB client:
I can use the query result publisher and consumption logic in DynamoDB along with one of the popular external libraries for working with reactive streams, like Project Reactor or RxJava (used in the example that follows) to model the query:
The following is a simple code snippet that brings all the subqueries into a single result, similar to what I did with regular parallel streams and the AWS SDK for Java v1:
Reactive programming, combined with other topics I discussed in this post, is an exciting area to explore. The reactive approach lets us process events as they arrive, speeding up processing by not waiting until all the data is available. And most importantly, it hides the underlying complexities of threading, blocking, and synchronization between parallel processes.
Conclusion
This post highlights the power of parallelism. I discussed the DynamoDB query system and the ways to split queries into multiple subqueries that can be run independently and in parallel. In addition to addressing DynamoDB query solutions, I showed you Java code that uses parallel streams with a common ForkJoin pool, as well as how to use CompletableFuture with a defined thread pool size. For comparison, I showed you a way to use the AWS SDK for Java v2 and a reactive programming method to deal with asynchrony and the push model used by the publisher providing the data.
The results showed that splitting a single large query into multiple sub-queries significantly improves performance. Before you decide on your implementation steps, it’s a good idea to test using your data, compute environment, and query pattern. Although I discussed two approaches (using date and query-slot), there are several ways to achieve similar query patterns, like querying by different countries, states, zip codes, product categories, and more. Anything that has finite cardinality is a good choice for subquery splitting, because you need to determine the thread pool size before you run the query.
Finally, retrieving data in smaller chunks allows for immediate processing without waiting for all the data to be returned.
You can find the code mentioned in this post on GitHub. Feel free to test it. The project contains a README.md that covers all the necessary details and requirements to have a successful code run.
About the Author
Zoran Ivanovic is a Big Data Principal Consultant with AWS Professional Services in Canada. After 5 years of experience leading one of the largest big data teams in Amazon, he moved to AWS to share his experience with larger enterprise customers who are interested in leveraging AWS services to build their mission-critical systems in the cloud.
Read MoreAWS Database Blog