

{kind=link}
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines search for your websites and applications so your employees and customers can easily find the content they’re looking for, even when it’s scattered across multiple locations and content repositories within your organization.
Amazon Kendra supports a variety of document formats, such as Microsoft Word, PDF, and text. While working with a leading Edtech customer, we were asked to build an enterprise search solution that also utilizes images and PPT files. This post focuses on extending the document support in Amazon Kendra so you can preprocess text images and scanned documents (JPEG, PNG, or PDF format) to make them searchable. The solution combines Amazon Textract for document preprocessing and optical character recognition (OCR), and Amazon Kendra for intelligent search.
With the new Custom Document Enrichment feature in Amazon Kendra, you can now preprocess your documents during ingestion and augment your documents with new metadata. Custom Document Enrichment allows you to call external services like Amazon Comprehend, Amazon Textract, and Amazon Transcribe to extract text from images, transcribe audio, and analyze video. For more information about using Custom Document Enrichment, refer to Enrich your content and metadata to enhance your search experience with custom document enrichment in Amazon Kendra.
In this post, we propose an alternate method of preprocessing the content prior to calling the ingestion process in Amazon Kendra.
Solution overview
Amazon Textract is an ML service that automatically extracts text, handwriting, and data from scanned documents and goes beyond basic OCR to identify, understand, and extract data from forms and tables. Today, many companies manually extract data from scanned documents like PDFs, images, tables, and forms through basic OCR software that requires manual configuration, which often requires reconfiguration when the form changes.
To overcome these manual and expensive processes, Amazon Textract uses machine learning to read and process a wide range of documents, accurately extracting text, handwriting, tables, and other data without any manual effort. You can quickly automate document processing and take action on the information extracted, whether it’s automating loans processing or extracting information from invoices and receipts.
Amazon Kendra is an easy-to-use enterprise search service that allows you to add search capabilities to your applications so that end-users can easily find information stored in different data sources within your company. This could include invoices, business documents, technical manuals, sales reports, corporate glossaries, internal websites, and more. You can harvest this information from storage solutions like Amazon Simple Storage Service (Amazon S3) and OneDrive; applications such as Salesforce, SharePoint, and ServiceNow; or relational databases like Amazon Relational Database Service (Amazon RDS).
The proposed solution enables you to unlock the search potential in scanned documents, extending the ability of Amazon Kendra to find accurate answers in a wider range of document types. The workflow includes the following steps:
Upload a document (or documents of various types) to Amazon S3.
The event triggers an AWS Lambda function that uses the synchronous Amazon Textract API (DetectDocumentText).
Amazon Textract reads the document in Amazon S3, extracts the text from it, and returns the extracted text to the Lambda function.
The data source on the new text file needs to be reindexed.
When reindexing is complete, you can search the new dataset either via the Amazon Kendra console or API.
The following diagram illustrates the solution architecture.
{kind=link}
In the following sections, we demonstrate how to configure the Lambda function, create the event trigger, process a document, and then reindex the data.
Configure the Lambda function
To configure your Lambda function, add the following code to the function Python editor:
We use the DetectDocumentText API to extract the text from an image (JPEG or PNG) retrieved in Amazon S3.
Create an event trigger at Amazon S3
In this step, we create an event trigger to start the Lambda function when a new document is uploaded to a specific bucket. The following screenshot shows our new function on the Amazon S3 console.
{kind=link}
You can also verify the event trigger on the Lambda console.
{kind=link}
Process a document
To test the process, we upload an image to the S3 folder that we defined for the S3 event trigger. We use the following sample image.
{kind=link}
When the Lambda function is complete, we can go to the Amazon CloudWatch console to check the output. The following screenshot shows the extracted text, which confirms that the Lambda function ran successfully.
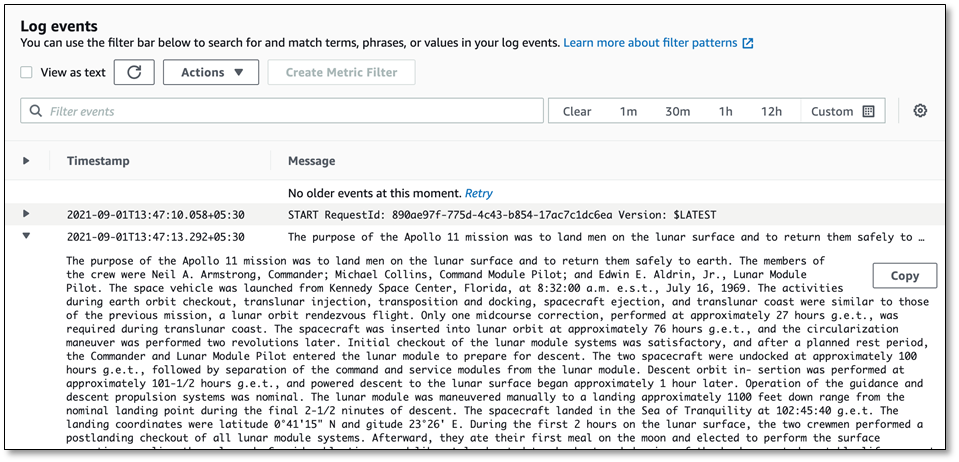{kind=link}
Reindex the data with Amazon Kendra
We can now reindex our data.
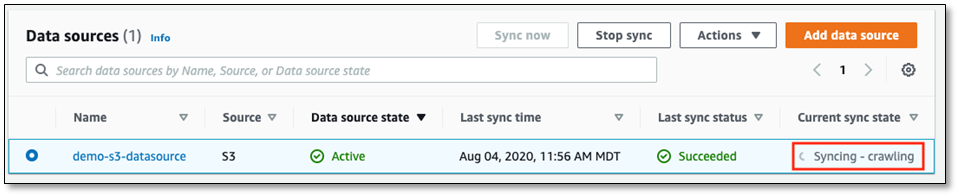
On the Amazon Kendra console, under Data management in the navigation pane, choose Data sources.
Select the data source demo-s3-datasource.
Choose Sync now.
The sync state changes to Synching – crawling.
{kind=link}
When the sync is complete, the sync status changes to Succeeded and the sync state changes to Idle.
{kind=link}
Now we can go back to the search console and see our faceted search in action.
In the navigation pane, choose Search console.
{kind=link}
We added metadata for a few items; two of them are the ML algorithms XGBoost and BlazingText.
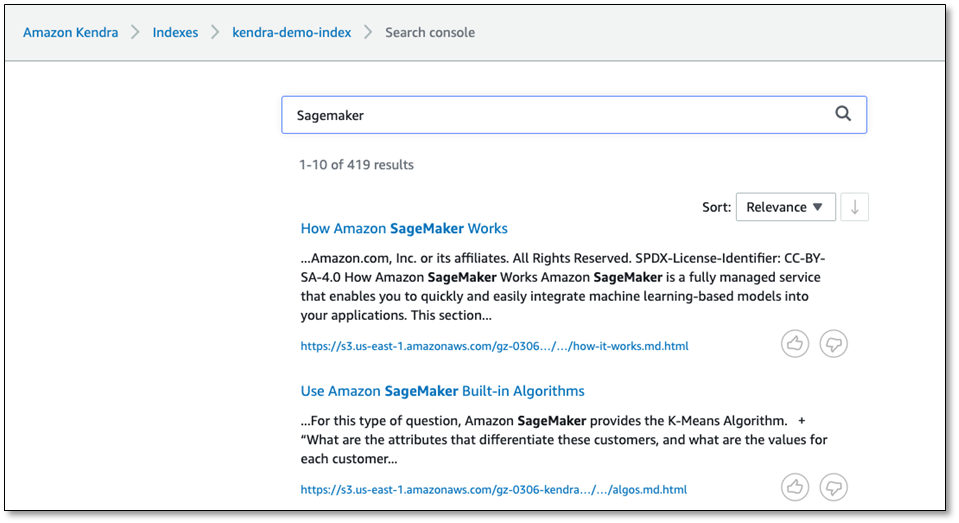
Let’s try searching for Sagemaker.
{kind=link}
Our search was successful, and we got a list of results. Let’s see what we have for facets.
Expand Filter search results.
We have the category and tags facets that were part of our item metadata.
Choose BlazingText to filter results just for that algorithm.
Now let’s perform the search on newly uploaded image files. The following screenshot shows the search on new preprocessed documents.
{kind=link}
{kind=link}
Conclusion
This blog will be helpful in improving the effectiveness of search results and search experience. You can use Amazon Textract to extract text from scanned images that are added as metadata and later available as facets to interact with the search results. This is just an illustration of how you can use AWS native services to create a differentiated search experience for your users. This also helps in unlocking the full potential of your knowledge assets.
For a deeper dive into what you can achieve by combining other AWS services with Amazon Kendra, refer to Make your audio and video files searchable using Amazon Transcribe and Amazon Kendra, Build an intelligent search solution with automated content enrichment, and other posts on the Amazon Kendra blog.
About of Author
Sanjay Tiwary is a Specialist Solutions Architect AI/ML. He spends his time working with strategic customers to define business requirements, provide L300 sessions around specific use cases, and design ML applications and services that are scalable, reliable, and performant. He has helped launch and scale the AI/ML powered Amazon SageMaker service and has implemented several proofs of concept using Amazon AI services. He has also developed the advanced analytics platform as a part of the digital transformation journey.
{kind=link}
Read MoreAWS Machine Learning Blog