

{kind=link}
Internet of Things (IoT) has enabled customers in multiple industries, such as manufacturing, automotive, and energy, to monitor and control real-world environments. By deploying a variety of edge IoT devices such as cameras, thermostats, and sensors, you can collect data, send it to the cloud, and build machine learning (ML) models to predict anomalies, failures, and more. However, if the use case requires real-time prediction, you need to enrich your IoT solution with ML at the edge (ML@Edge) capabilities. ML@Edge is a concept that decouples the ML model’s lifecycle from the app lifecycle and allows you to run an end-to-end ML pipeline that includes data preparation, model building, model compilation and optimization, model deployment (to a fleet of edge devices), model execution, and model monitoring and governing. You deploy the app once and run the ML pipeline as many times as you need.
As you can imagine, to implement all the steps proposed by the ML@Edge concept is not trivial. There are many questions that developers need to address in order to implement a complete ML@Edge solution, for example:
How do I operate ML models on a fleet (hundreds, thousands, or millions) of devices at the edge?
How do I secure my model while deploying and running it at the edge?
How do I monitor my model’s performance and retrain it, if needed?
In this post, you learn how to answer all these questions and build an end-to-end solution for automating your ML@Edge pipeline. You’ll see how to use Amazon SageMaker Edge Manager, Amazon SageMaker Studio, and AWS IoT Greengrass v2 to create an MLOps (ML Operations) environment that automates the process of building and deploying ML models to large fleets of edge devices.
In the next sections, we present a reference architecture that details all the components and workflows required to build a complete solution for MLOps focused on edge workloads. Then we dive deep into the steps this solution runs automatically to build and prepare a new model. We also show you how to prepare the edge devices to start deploying, running, and monitoring ML models, and demonstrate how to monitor and maintain the ML models deployed to your fleet of devices.
Solution overview
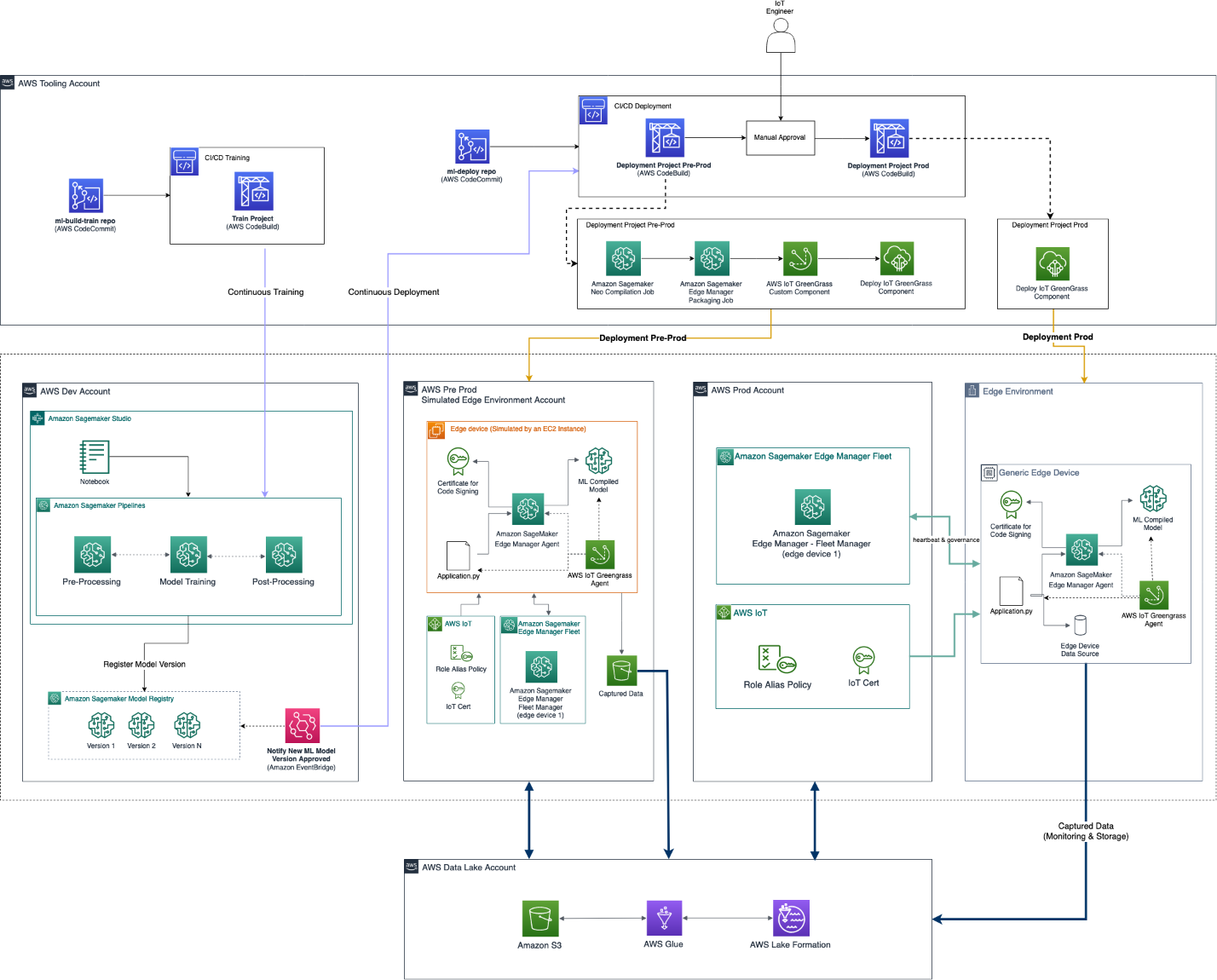
Productionization of robust ML models requires the collaboration of multiple personas, such as data scientists, ML engineers, data engineers, and business stakeholders, under a semi-automate infrastructure following specific operations (MLOps). Also, the modularization of the environment is important in order to give all these different personas the flexibility and agility to develop or improve (independently of the workflow) the component for which they are responsible. An example of such an infrastructure consists of multiple AWS accounts that enable this collaboration and productionization of the ML models both in the cloud and to the edge devices. In the following reference architecture, we show how we organized the multiple accounts and services that compose this end-to-end MLOps platform for building ML models and deploying them at the edge.
{kind=link}
This solution consists of the following accounts:
Data lake account – Data engineers ingest, store, and prepare data from multiple data sources, including on-premise databases and IoT devices.
Tooling account – IT operators manage and check CI/CD pipelines for automated continuous delivery and deployment of ML model packages across the pre-production and production accounts for remote edge devices. Runs of CI/CD pipelines are automated through the usage of Amazon EventBridge, which monitors change status events of ML models and targets AWS CodePipeline.
Experimentation and development account – Data scientists can conduct research and experiment with multiple modeling techniques and algorithms to solve business problems based on ML, creating proof of concept solutions. ML engineers and data scientists collaborate to scale a proof of concept, creating automated workflows using Amazon SageMaker Pipelines to prepare data and build, train, and package ML models. The deployment of the pipelines is driven via CI/CD pipelines, while the version control of the models is achieved using the Amazon SageMaker model registry. Data scientists evaluate the metrics of multiple model versions and request the promotion of the best model to production by triggering the CI/CD pipeline.
Pre-production account – Before the promotion of the model to the production environment, the model needs to be tested to ensure robustness in a simulation environment. Therefore, the pre-production environment is a simulator of the production environment, in which SageMaker model endpoints are deployed and tested automatically. Test methods might include an integration test, stress test, or ML-specific tests on inference results. In this case, the production environment isn’t a SageMaker model endpoint but an edge device. To simulate an edge device in pre-production, two approaches are possible: use an Amazon Elastic Compute Cloud (Amazon EC2) instance with the same hardware characteristics, or use an in-lab testbed consisting of the actual devices. With this infrastructure, the CI/CD pipeline deploys the model to the corresponding simulator and conducts the multiple tests automatically. After the tests run successfully, the CI/CD pipeline requires manual approval (for example, from the IoT stakeholder to promote the model to production).
Production account – In the case of hosting the model on the AWS Cloud, the CI/CD pipeline deploys a SageMaker model endpoint on the production account. In this case, the production environment consists of multiple fleets of edge devices. Therefore, the CI/CD pipeline uses Edge Manager to deploy the models to the corresponding fleet of devices.
Edge devices – Remote edge devices are hardware devices that can run ML models using Edge Manager. It allows the application on those devices to manage the models, run inference against the models, and capture data securely into Amazon Simple Storage Service (Amazon S3).
SageMaker projects help you to automate the process of provisioning resources inside each of these accounts. We don’t dive deep into this feature, but to learn more about how to build a SageMaker project template that deploys ML models across accounts, check out Multi-account model deployment with Amazon SageMaker Pipelines.
Pre-production account: Digital twin
After the training process, the resulting model needs to be evaluated. In the pre-production account, you have a simulated Edge device. It represents the digital twin of the edge device on which the ML model runs in production. This environment has the dual purpose of performing the classic tests (such as unit, integration, and smoke) and to be a playground for the development team. This device is simulated using an EC2 instance where all the components needed to manage the ML model were deployed.
The involved services are as follows:
AWS IoT Core – We use AWS IoT Core to create AWS IoT thing objects, create a device fleet, register the device fleet so it can interact with the cloud, create X.509 certificates to authenticate edge devices to AWS IoT Core, associate the role alias with AWS IoT Core that was generated when the fleet has created, get an AWS account-specific endpoint for the credential provider, get an official Amazon Root CA file, and upload the Amazon CA file to Amazon S3.
Amazon Sagemaker Neo – Sagemaker Neo automatically optimizes machine learning models for inference to run faster with no loss in accuracy. It supports machine learning model already built with DarkNet, Keras, MXNet, PyTorch, TensorFlow, TensorFlow-Lite, ONNX, or XGBoost and trained in Amazon SageMaker or anywhere else. Then you choose your target hardware platform, which can be a SageMaker hosting instance or an edge device based on processors from Ambarella, Apple, ARM, Intel, MediaTek, Nvidia, NXP, Qualcomm, RockChip, Texas Instruments, or Xilinx.
Edge Manager – We use Edge Manager to register and manage the edge device within the Sagemaker fleets. Fleets are collections of logically grouped devices you can use to collect and analyze data. Besides, Edge Manager packager, packages the optimized model and create an AWS IoT Greengrass V2 component that can directly be deployed. You can use Edge Manager to operate ML models on a fleet of smart cameras, smart speakers, robots, and other SageMaker device fleets.
AWS IoT Greengrass V2 – AWS IoT Greengrass allows you to deploy components into the simulated devices using an EC2 instance. By using the AWS IoT Greengrass V2 agent in the EC2 instances, we can simplify the access, management, and deployment of the Edge Manager agent and model to devices. Without AWS IoT Greengrass V2, setting up devices and fleets to use Edge Manager requires you to manually copy the agent from an S3 release bucket. With AWS IoT Greengrass V2 and Edge Manager integration, it’s possible to use AWS IoT Greengrass V2 components. Components are pre-built software modules that can connect edge devices to AWS services or third-party service via AWS IoT Greengrass.
Edge Manager agent – The Edge Manager agent is deployed via AWS IoT Greengrass V2 in the EC2 instance. The agent can load multiple models at a time and make inference with loaded models on edge devices. The number of models the agent can load is determined by the available memory on the device.
Amazon S3 – We use an S3 bucket to store the inference captured data from the Edge Manager agent.
We can define a pre-production account as a digital twin for testing ML models before moving them into real edge devices. This offers the following benefits:
Agility and flexibility – Data scientists and ML engineers need to quickly validate if the ML model and associated scripts (preprocessing and inference scripts) will work on the device edge. However, IoT and data science departments in large enterprises may be different entities. By identically replicating the technology stack in the cloud, data scientists and ML engineers can iterate and consolidate artifacts prior to deployment.
Accelerated risk assessment and production time – Deployment on the edge device is the final stage of the process. After you validate everything in an isolated and self-contained environment, secure it to be adherent to the specifications required by the edge in terms of quality, performance, and integration. This helps avoid further involvement of other people in the IoT department to fix and iterate on artifact versions.
Improved team collaboration and enhanced quality and performance – Development team can immediately assess the impact of the ML model by analyzing edge hardware metrics and measuring the level of interactions with third-party tools (eg. I/O rate). Then, the IoT team is only responsible for deployment to the production environment, and can be confident that the artifacts are accurate for a production environment.
Integrated playground for testing – Given the target of ML models, the pre-production environment in a traditional workflow should be represented by an edge device outside the cloud environment. This introduces another level of complexity. Integrations are needed to collect metrics and feedback. Instead, by using the digital twin simulated environment, interactions are reduced and time to market is shortened.
Production account and edge environment
After the tests are complete and the artifact stability is achieved, you can proceed to production deployment through the pipelines. Artifact deployment occurs programmatically after an operator has approved the artifact. However, access to the AWS Management Console is granted to operators in read-only mode to be able to monitor metadata associated with the fleets and therefore have insight into the version of the deployed ML model and other metrics associated with the lifecycle.
Edge device fleets belong to the AWS production account. This account has specific security and networking configurations to allow communication between the cloud and edge devices. The main AWS services deployed in the production account are Edge Manager, which is responsible for managing all the device fleets, collecting data, and operating ML models, and AWS IoT Core, which manages IoT thing objects, certificates, role alias, and endpoints.
At the same time, we need to configure an edge device with the services and components to manage ML models. The main components are as follows:
AWS IoT Greengrass V2
An Edge Manager agent
AWS IoT certificates
Application.py, which is responsible for orchestrating the inference process (retrieving information from the edge data source and performing inference using the Edge Manager agent and loaded ML model)
A connection to Amazon S3 or the data lake account to store inferenced data
Automated ML pipeline
Now that you know more about the organization and the components of the reference architecture, we can dive deeper into the ML pipeline that we use to build, train, and evaluate the ML model inside the development account.
A pipeline (built using Amazon SageMaker Model Building Pipelines) is a series of interconnected steps that is defined by a JSON pipeline definition. This pipeline definition encodes a pipeline using a Directed Acyclic Graph (DAG). This DAG gives information on the requirements for and relationships between each step of your pipeline. The structure of a pipeline’s DAG is determined by the data dependencies between steps. These data dependencies are created when the properties of a step’s output are passed as the input to another step.
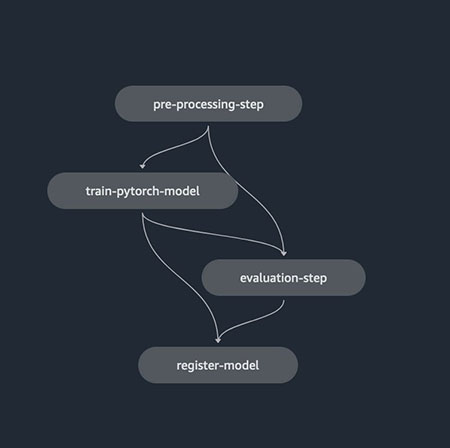
To enable data science teams to easily automate the creation of new versions of ML models, it’s important to introduce validation steps and automated data for continuously feeding and improving ML models, as well as model monitoring strategies for enabling pipeline triggering. The following diagram shows an example pipeline.
{kind=link}
For enabling automations and MLOps capabilities, it’s important to create modular components for creating reusable code artifacts that can be sharable across different steps and ML use cases. This enables you to quickly move the implementation from an experimentation phase to a production phase by automating the transition.
The steps for defining an ML pipeline for enabling the continuous training and versioning of ML models are as follows:
Preprocessing – The process of data cleaning, feature engineering, and dataset creation for training the ML algorithm
Training – The process of training the developed ML algorithm for generating a new version of the ML model artifact
Evaluation – The process of evaluation of the generated ML model, for extracting key metrics related to the model behavior on new data not seen during the training phase
Registration – The process of versioning the new trained ML model artifact by linking the metrics extracted with the generated artifact
You can see more details of how to build a SageMaker pipeline in the following notebook.
Trigger CI/CD pipelines using EventBridge
When you finish building the model, you can start the deployment process. The last step of the SageMaker pipeline defined in the previous section registers a new version of the model in the specific SageMaker model registry group. The deployment of a new version of the ML model is managed using the model registry status. By manually approving or rejecting an ML model version, this step raises an event that is captured by EventBridge. This event can then start a new pipeline (CI/CD this time) for creating a new version of the AWS IoT Greengrass component that is then deployed to the pre-production and production accounts. The following screenshot shows our defined EventBridge rule.
{kind=link}
This rule monitors the SageMaker model package group by looking for updates of model packages in the status Approved or Rejected.
The EventBridge rule is then configured to target CodePipeline, which starts the workflow of creating a new AWS IoT Greengrass component by using Amazon SageMaker Neo and Edge Manager.
Optimize ML models for the target architecture
Neo allows you to optimize ML models for performing inference on edge devices (and in the cloud). It automatically optimizes the ML models for better performance based on the target architecture, and decouples the model from the original framework, allowing you to run it on a lightweight runtime.
Refer to the following notebook for an example of how to compile a PyTorch Resnet18 model using Neo.
Build the deployment package by including the AWS IoT Greengrass component
Edge Manager allows you to manage, secure, deploy, and monitor models to a fleet of edge devices. In the following notebook, you can see more details of how to build a minimalist fleet of edge devices and run some experiments with this feature.
After you configure the fleet and compile the model, you need to run an Edge Manager packaging job, which prepares the model to be deployed to the fleet. You can start a packaging job by using the Boto3 SDK. For our parameters, we use the optimized model and model metadata. By adding the following parameters to OutputConfig, the job also prepares an AWS IoT Greengrass V2 component with the model:
PresetDeploymentType
PresetDeploymentConfig
See the following code:
Deploy ML models at the edge at scale
Now it’s time to deploy the model to your fleet of edge devices. First, we need to ensure that we have the necessary AWS Identity and Access Management (IAM) permissions to provision our IoT devices and are able to deploy components to it. We require two basic elements to start onboarding devices into our IoT platform:
IAM policy – This policy allows for the automatic provisioning of such devices, attached to the user or role performing the provisioning. It should have IoT write permissions to create the IoT thing and group, as well as to attach the necessary policies to the device. For more information, refer to Minimal IAM policy for installer to provision resources.
IAM role – this role is attached to the IoT things and groups that we create. You can create this role at provisioning time with basic permissions, but it will lack features like access to Amazon S3 or AWS Key Management Service (AWS KMS) that might be needed later. You can create this role beforehand and reuse it when we provision the device. For more information, refer to Authorize core devices to interact with AWS.
AWS IoT Greengrass installation and provisioning
After we have the IAM policy and role in place, we’re ready to install AWS IoT Greengrass Core software with automatic resource provisioning. Although it’s possible to provision the IoT resources following manual steps, there is the convenient procedure of automatically provisioning these resources during the installation of the AWS IoT Greengrass v2 nucleus. This is the preferred option to quickly onboard new devices into the platform. Besides default-jdk, other packages are required to be installed, such as curl, unzip, and python3.
When we provision our device, the IoT thing name must be exactly the same as the edge device defined in Edge Manager, otherwise data won’t be captured to the destination S3 bucket.
The installer can create the AWS IoT Greengrass role and alias during the installation if they don’t exist. However, they’ll be created with minimal permissions and will require manually adding more policies to interact with other services such as Amazon S3. We recommend creating these IAM resources beforehand as shown earlier, and then reuse them as you onboard new devices into the account.
Model and inference component packaging
After our code has been developed, we can deploy both the code (for inference) and our ML models as components into our devices.
After the ML model is trained in SageMaker, you can optimize the model with Neo using a Sagemaker compilation job. The resulting compiled model artifacts, can then be packaged into a GreenGrass V2 component using the Edge Manager packager. Then, it can be registered as a custom component in the My Components section on the AWS IoT Greengrass console. This component already contains the necessary lifecycle commands to download and decompress the model artifact in our device, so that the inference code can load it up to send the images captured through it.
Regarding the inference code, we must create a component using the console or AWS Command Line Interface (AWS CLI). First, we pack our source inference code and necessary dependencies to Amazon S3. After we upload the code, we can create our component using a recipe in .yaml or JSON like the following example:
This example recipe shows the name and description of our component, as well as the necessary prerequisites before our run script command. The recipe unpacks the artifact in a work folder environment in the device, and we use that path to run our inference code. The AWS CLI command to create such recipe is:
You can now see this component created on the AWS IoT Greengrass console.
Beware of the fact that the component version matters, and it must be specified in the recipe file. Repeating the same version number will return an error.
After our model and inference code have been set up as components, we’re ready to deploy them.
Deploy the application and model using AWS IoT Greengrass
In the previous sections, you learned how to package the inference code and the ML models. Now we can create a deployment with multiple components that include both components and configurations needed for our inference code to interact with the model in the edge device.
The Edge Manager agent is the component that should be installed on each edge device in order enable all the Edge Manager capabilities. On the SageMaker console, we have a device fleet defined, which has an associated S3 bucket. All edge devices associated with the fleet will capture and report their data to this S3 path. The agent can be deployed as a component in AWS IoT Greengrass v2, which makes it easier to install and configure than if the agent were deployed in standalone mode. When deploying the agent as a component, we need to specify its configuration parameters, namely the device fleet and S3 path.
We create a deployment configuration with the custom components for the model and code we just created. This setup is defined in a JSON file that lists the deployment name and target, as well as the components in the deployment. We can add and update the configuration parameters of each component, such as in the Edge Manager agent, where we specify the fleet name and bucket.
It’s worth noting that we have added not only the model, inference components, and agent, but also the AWS IoT Greengrass CLI and nucleus as components. The former can help debug certain deployments locally on the device. The latter is added into the deployment to configure the necessary network access from the device itself if needed (for example, proxy settings), and also in case you want to perform an OTA upgrade of the AWS IoT Greengrass v2 nucleus. The nucleus isn’t deployed because it’s installed in the device, and only the configuration update will be applied (unless an upgrade is in place). To deploy, we simply need to run the following command over the preceding configuration. Remember to set up the target ARN to which the deployment will be applied (an IoT thing or IoT group). We can also deploy these components from the console.
Monitor and manage ML models deployed to the edge
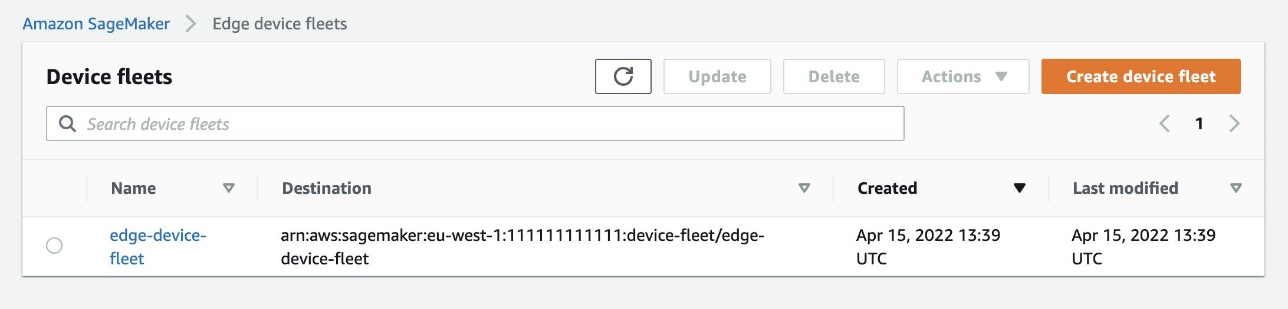
Now that your application is running on the edge devices, it’s time to understand how to monitor the fleet to improve governance, maintenance, and visibility. On the SageMaker console, choose Edge Manager in the navigation pane, then choose Edge device fleets. From here, choose your fleet.
{kind=link}
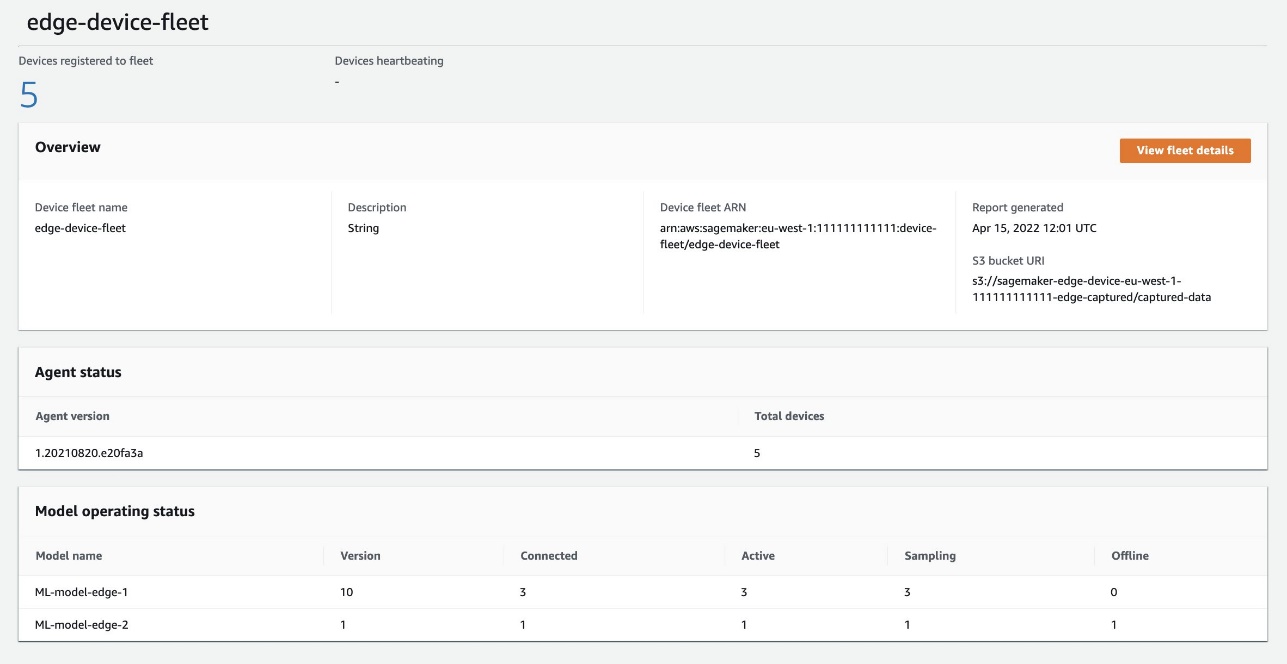
On the fleet’s detail page, you can see some metadata of the models that are running on each device of your fleet. Fleet report is generated every 24 hours.
{kind=link}
Data captured by each device through the Edge Agent is sent to an S3 bucket in json lines format (JSONL). The process of sending captured data is managed from an application standpoint. You are therefore free to decide whether to send this data, how and how often.
{kind=link}
You can use this data for many things, such as monitoring data drift and model quality, building a new dataset, enriching a data lake, and more. A simple example of how to utilize this data is when you identify some data drift in the way users are interacting with your application and you need to train a new model. You then build a new dataset with the captured data and copy it back to the development account. This can automatically start a new run of your environment that builds a new model and redeploys it to the whole fleet to keep the performance of the deployed solution.
Conclusion
In this post, you learned how to build a complete solution that combines MLOps and ML@Edge using AWS services. Building such a solution is not trivial, but we hope the reference architecture presented in this post can inspire and help you build a solid architecture for your own business challenges. You can also use just the parts or modules of this architecture that integrate with your existing MLOps environment. By prototyping one single module at a time and using the appropriate AWS services to address each piece of this challenge, you can learn how to build a robust MLOps environment and also further simplify the final architecture.
As a next step, we encourage you to try out Sagemaker Edge Manager to manage your ML at edge lifecycle. For more information on how Edge Manager works, see Deploy models at the edge with SageMaker Edge Manager .
About the authors
Bruno Pistone is an AI/ML Specialist Solutions Architect for AWS based in Milan. He works with customers of any size on helping them to to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His field of expertice are Machine Learning end to end, Machine Learning Industrialization and MLOps. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
{kind=link}
Matteo Calabrese is an AI/ML Customer Delivery Architect in AWS Professional Services team. He works with EMEA large enterprises on AI/ML projects, helping them in proposition, design, deliver, scale, and optimize ML production workloads. His main expertise are ML Operation (MLOps) and Machine Learning at Edge. His goal is shortening their time to value and accelerate business outcomes by providing AWS best practices. In his spare time, he enjoys hiking and traveling.
{kind=link}
Raúl Díaz García is a Sr Data Scientist in AWS Professional Services team. He works with large enterprise customers across EMEA, where he helps them enable solutions related to Computer Vision and Machine Learning in the IoT space.
{kind=link}
Sokratis Kartakis is a Senior Machine Learning Specialist Solutions Architect for Amazon Web Services. Sokratis focuses on enabling enterprise customers to industrialize their Machine Learning (ML) solutions by exploiting AWS services and shaping their operating model, i.e. MLOps foundation, and transformation roadmap leveraging best development practices. He has spent 15+ years on inventing, designing, leading, and implementing innovative end-to-end production-level ML and Internet of Things (IoT) solutions in the domains of energy, retail, health, finance/banking, motorsports etc. Sokratis likes to spend his spare time with family and friends, or riding motorbikes.
{kind=link}
Samir Araújo is an AI/ML Solutions Architect at AWS. He helps customers creating AI/ML solutions which solve their business challenges using AWS. He has been working on several AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. He likes playing with hardware and automation projects in his free time, and he has a particular interest for robotics.
{kind=link}
Read MoreAWS Machine Learning Blog