

{kind=link}
Amazon Relational Database Services (Amazon RDS) Custom for SQL Server is a managed database service for legacy, custom, and packaged applications that require access to the underlying operating system and database (DB) environment. Amazon RDS Custom is now available for the SQL Server database engine. Amazon RDS Custom for SQL Server automates the setup, operation, and scaling of databases in the cloud while granting access to the database and underlying operating system to configure settings, install drivers, and enable native features to meet the dependent application’s requirements.
There are several methods and tools that you can use to migrate self-managed SQL Server databases running on physical or virtual machines to Amazon RDS Custom for SQL Server:
Using native SQL Server backup and restore features.
Using Always On availability groups. For more information, refer to Migrate an on-premises SQL Server standalone workload to Amazon RDS Custom for SQL Server using domain-independent, Always On availability groups.
Using AWS Database Migration Service (AWS DMS). AWS DMS can help you move data quickly and securely to the cloud. However, it has a few limitations; refer to Limitations on using SQL Server as a source for AWS DMS for more information.
Using SQL Server transactional replication. For more information, refer to Configure SQL Server replication between Amazon RDS Custom for SQL Server and Amazon RDS for SQL Server.
Using a distributed availability group.
You can store the native backups on Amazon Simple Storage Service (Amazon S3) or an Amazon Elastic Block Store (Amazon EBS) volume attached to Amazon RDS Custom for SQL Server. Amazon S3 is the most common platform for storing database backup files because it can increase agility and reduce cost. To see the full benefits of Amazon S3, refer to Features of Amazon S3.
In this post, we highlight using native backup and restore with Amazon S3. We also showcase the use of all native backup types and restores (full, differential, log). The use of both differential and log restores is helpful during a database migration cutover to minimize downtime. We provide the steps to migrate an on-premises database to Amazon RDS Custom for SQL Server using Amazon S3 based on manual backups.
Solution overview
The following diagram illustrates the typical migration steps when using native backups to minimize application downtime.
{kind=link}
The steps are as follows:
Initial step – Full database backup and restore
Perform a full on-premises database backup at 12:00 AM (midnight) and upload to an S3 bucket.
On Amazon RDS Custom for SQL Server, download the full database backup file from Amazon S3 and restore with NORECOVERY.
Intermediate step – Differential database backup and restore
Perform an on-premises differential database backup at 8:00 AM and upload to an S3 bucket.
On Amazon RDS Custom for SQL Server, download the differential database backup file from Amazon S3 and restore with NORECOVERY.
Cutover step – Transaction log backup and restore
Perform an on-premises transaction log backup at 8:20 AM and upload to an S3 bucket.
On Amazon RDS Custom for SQL Server, download the transaction log backup file from Amazon S3 and restore with RECOVERY.
Prerequisites
We assume that you have the following prerequisites:
Background knowledge about SQL Server backup and restore.
An S3 bucket configured to store the necessary database backup files. For instructions, refer to Creating a bucket.
AWS services such as Amazon S3, Amazon Elastic Compute Cloud (Amazon EC2), the AWS Command Line Interface (AWS CLI), and Amazon RDS.
Basic knowledge of how to set up and launch RDS for Custom SQL Server instances. For more information, refer to Creating and connecting to a DB instance for Amazon RDS for custom SQL Server
Because this solution involves AWS resource setup and utilization, it will incur the costs on your account. Refer to AWS Pricing for more information. We strongly recommend that you set this up in a non-production instance and run end-to-end validations before you implement this solution in a production environment.
Initial step: Full database backup and restore
This post assumes that the SampleTest database is being migrated from an on-premises SQL Server instance to Amazon RDS Custom for SQL Server on a given date (for example, September 4, 2022).
Full database backup
During the initial step, you perform a full database backup of the source (on-premises) instance with the following command :
Upload the full database backup file to Amazon S3
When the full database backup is complete, upload the backup file to an S3 bucket (sqlservers3backuprestore). To upload the backup files to Amazon S3, you can use the Amazon S3 console or the AWS CLI. The following is an example using the AWS CLI.
Run the following command on the source (on-premises) instance:
{kind=link}
Download the full database backup file from Amazon S3 to Amazon RDS Custom for SQL Server
To download the database backup files, you need to RDP into the RDS Custom DB instance. See Connecting to your RDS Custom DB instance using RDP for detailed steps.
After you RDP into your RDS Custom for SQL Server instance, make sure you can access the S3 bucket using the Amazon S3 console or AWS CLI and download the backup files.
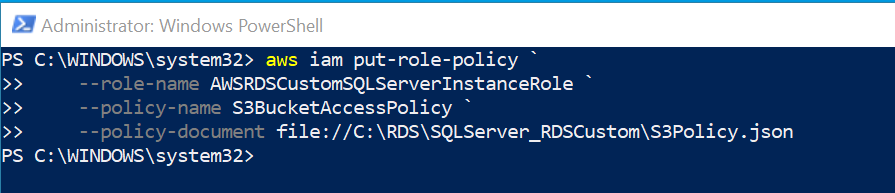
Before you can download files with the AWS CLI, provide access to the S3 bucket where the backups are stored by adding a policy to the Amazon EC2 role similar to the one provided in the following example. This can also be done from your computer.
To add a policy to a role, save the policy as a JSON file and run the following AWS CLI command (save the preceding JSON as S3Policy.json):
{kind=link}
As a best practice, the RDS Custom for SQL Server instance should be in a private subnet. You also need to modify the policy of the VPC Amazon S3 gateway endpoint to allow access to the S3 bucket where the backups are stored. For our example, we add the following policy. You can do this through the Amazon Virtual Private Cloud (Amazon VPC) console (refer to Control access to services using endpoint policies) or using the AWS CLI (refer to modify-vpc-endpoint). See the following code:
After we’ve given access to the S3 bucket, we can download the backup files to the D:rdsdbdataBACKUP directory.
Use the following command to download the full database backup file on the target (RDS Custom for SQL Server) instance:
{kind=link}
Restore the full database backup in Amazon RDS Custom for SQL Server
After you download the full database backup file, use the native SQL Server restore command.
Note that Amazon S3 has a size limit of 5 TB per file. For native backups of larger databases, you can use a multi-file backup on the source instance.
Currently, the maximum database instance storage for Amazon RDS Custom for SQL Server is 16 TiB.
For our example, we use SQL Server Management Studio (SSMS) to perform the restore. The following restore statement uses the NORECOVERY option:
Run the following commands on the target (RDS Custom for SQL Server) instance:
The database is left in the RESTORING state, allowing for subsequent differential or log restores.
Intermediate step: Differential database backup and restore
In this section, we walk through the steps for the differential database backup and restore.
Differential database backup
At 8:00 AM, we perform a differential database backup on premises with the following command to capture all the changes that happened since the last full backup:
Upload the differential database backup file to Amazon S3
When the differential database backup is complete, upload the backup file to Amazon S3. The following is an example of the AWS CLI command.
Run the following command on the source (on-premises) instance:
{kind=link}
Download the differential database backup file from Amazon S3 to Amazon RDS Custom for SQL Server
All necessary permissions were set up before downloading the full backup file. Use the following AWS CLI command to download the differential database backup file.
Run the following commands on the target (RDS Custom for SQL Server) instance:
{kind=link}
Restore the differential database backup in Amazon RDS Custom for SQL Server
After you download the differential database backup file, use the following native SQL Server differential restore command on the target (RDS Custom for SQL Server) instance:
The database is left in the RESTORING state, allowing for subsequent log restore.
Cutover step: Transaction log backup and restore
Transaction logs record all the database modifications made by each transaction. You must create at least one full backup before you can create any log backups. The sequence of transaction log backups (called a log chain) is independent of data backups.
In our example, the cutover from on premises to the Amazon RDS Custom for SQL Server occurs at 8:20 AM. The first step of the cutover is to stop any traffic from the application to the source database. Also, the source database can be set to read-only to make sure no other transactions are recorded.
Run the following command on the source (on-premises) instance:
Transaction log backup
After traffic to the database is stopped, perform a transaction log backup using the following command on the source (on-premises) instance:
Upload the transaction log backup file to Amazon S3
When the transaction log backup is complete, upload the backup file to Amazon S3. The following is an example of the AWS CLI command on the source (on-premises) instance:
{kind=link}
Download the transaction log backup file from Amazon S3 to Amazon RDS Custom
Use the following AWS CLI command on the target instance to download the transaction log backup file:
{kind=link}
Restore the transaction log backup
If you want to restore a database to a certain point, restore the full backup followed by the latest differential backup and all subsequent transaction logs up to that restore point.
In our example, we restored the differential backup taken at 8:00 AM. Now we need to restore the transaction log backup taken at 8:20 AM after the database was set to read-only. Use the following native SQL Server transaction log restore command on the target instance:
Now that the database is migrated, you can reconfigure the application to point to the new RDS Custom for SQL Server endpoint.
Clean up
If you don’t need the database backup files anymore, remove them from Amazon S3 and the D:rdsdbdataBACKUP directory with the following command:
Summary
In this post, we demonstrated how to migrate a self-managed SQL Server database to Amazon RDS Custom for SQL Server using native backup and restore functionality through Amazon S3. Try out Amazon RDS Custom for SQL Server for applications that require operating system and database customization to manage your database services effectively.
If you have any questions or suggestions, leave a comment.
About the authors
Priya Nair is a Database consultant at AWS. She has 18 plus years of experience working with different database technologies. She works as database migration specialist to help Amazon customers to move their on-premises database environment to AWS cloud database solutions.
{kind=link}
Jose Amado-Blanco is a Sr. Consultant on Database Migration with over 25 years of experience working with database technologies. He helps customers on their journey to migrate and modernize their database solutions from on-premises to AWS.
{kind=link}
InduTeja Aligeti is a Lead Database Consultant at AWS. She has 16+years of experience working with Microsoft Technologies with a specialization in SQL Server. She focuses on helping customers to build high-available, cost-effective database solutions and migrate their large scale SQL Server databases to AWS.
{kind=link}
Read MoreAWS Database Blog