

{kind=link}
Enterprise customers have repeatedly told us they want to migrate to open-source databases such as PostgreSQL. You can choose from several different ways to migrate your data and database schema from SQL Server to PostgreSQL. However, after the initial database migration is completed, manually rewriting application code, switching out database drivers, and verifying that the application behavior hasn’t changed requires significant effort. As a result, organizations struggle to start these types of projects because of the opportunity cost of tying up developers, and the risk of introducing errors when making extensive changes to the application code. We built Babelfish for Aurora PostgreSQL to make it easier to migrate applications from SQL Server to Amazon Aurora PostgreSQL-Compatible Edition.
In this post, we show how you can migrate from SQL Server to Babelfish for Aurora PostgreSQL.
Challenges in migrating from a commercial to open-source database
Migrating from legacy SQL Server databases can be time-consuming and resource-intensive.
{kind=link}
Let’s say you have an application that uses a SQL Server connectivity driver to connect to the database endpoint using the TDS protocol (Tabular Data Stream) and T-SQL (Microsoft’s SQL dialect). Your goal is to migrate the same app to use a PostgreSQL endpoint and PL/pgSQL. Three major steps are involved in any migration: moving over the schema, migrating the data, and modifying the client applications. When moving the client applications, the majority of the work goes into replacing the SQL Server drivers with their PostgreSQL equivalents, then migrating the T-SQL code into PL/pgSQL which is complex, time consuming and risky.
Out of the box readiness: Alternate mechanisms
Now with Babelfish, Aurora PostgreSQL can speak both Postgres PL/pgSQL and T-SQL. A Babelfish instance is bilingual, speaking both protocols and languages with one single cluster. Your application can connect directly to a TDS endpoint and speak T-SQL. It can also speak to the PostgreSQL endpoint and leverage PL/pgSQL. This way, you can keep the legacy app mostly as it’s written in T-SQL. If desired, new development can also be done in T-SQL. Over time, you may choose to gradually migrate to PostgreSQL.
{kind=link}
Overview of Migration Steps
The following is an outline of the migration process with Babelfish:
Generate the DDL from the source database.
Run the Babelfish Compass tool to determine whether the application contains any SQL features not currently supported by Babelfish.
Review the Babelfish Compass assessment report and rewrite or remove any unsupported SQL features (this could be an iterative process depending on your application).
Create the Babelfish cluster.
Connect to the Babelfish database.
Run the updated DDL against the Babelfish database.
Test and iterate until the migrated application’s functionality is correct.
Generate DDL using SSMS
In this post, we review the School Sample Database, you can download the DDL file here. To run the assessment for your application, complete the following steps for generating the DDL script using SQL Server Management Studio (SSMS):
Open SSMS and connect to your SQL Server instance as sa.
Right-click the source database, choose Tasks, and choose Generate Scripts.
Choose Next.
Choose Select specific database objects and select everything except Users.
Choose Advanced, which opens a new options window.
Search and modify the following options:
Types of data to script – Choose Schema only
Script Extended Properties – Choose False
Script Owner – Choose True
Script Object-Level-Permissions – Choose True
Script Logins – Choose True
Script Triggers – Choose True
Script Indexes – Choose True
{kind=link}
Babelfish Compass tool
The Babelfish Compass tool analyzes SQL/DDL code exported from one or more Microsoft SQL Server databases. Babelfish Compass identifies the SQL features that aren’t supported by the current version of Babelfish. The purpose of such analysis is to inform a go/no-go decision about whether it makes sense to consider starting a migration project from SQL Server to Babelfish. For this purpose, Babelfish Compass produces an assessment report that lists, in detail, all the SQL features found in the SQL/DDL code, and whether these are supported by the latest version of Babelfish.
Babelfish Compass is a standalone, on-premises tool. Although Babelfish Compass is part of the Babelfish product, it’s technically separate from Babelfish itself as well as from the Babelfish code, and is located in a separate GitHub repository.
With Babelfish Compass, you run the assessment on the DDL file(s) to determine what extent of T-SQL code is supported by Babelfish and identify T-SQL code that may require changing before running against Babelfish.
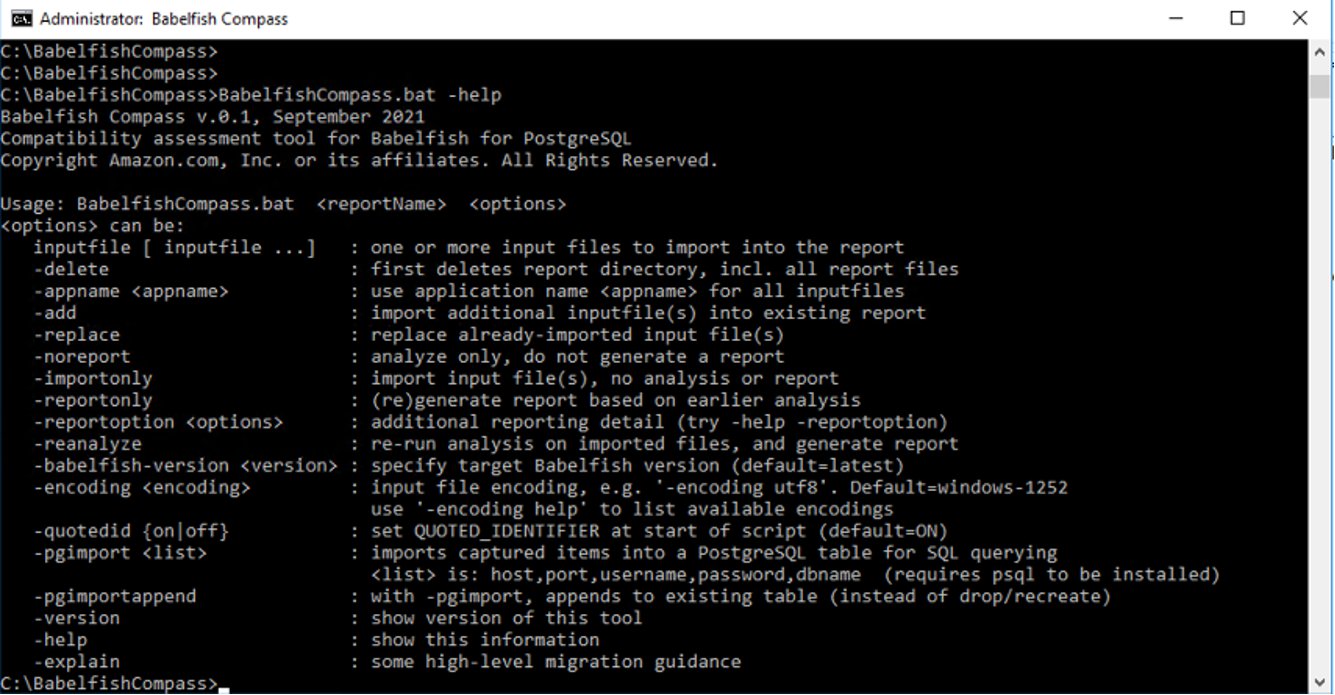
For this post, I installed the Babelfish Compass tool in C:BabelfishCompass:
{kind=link}
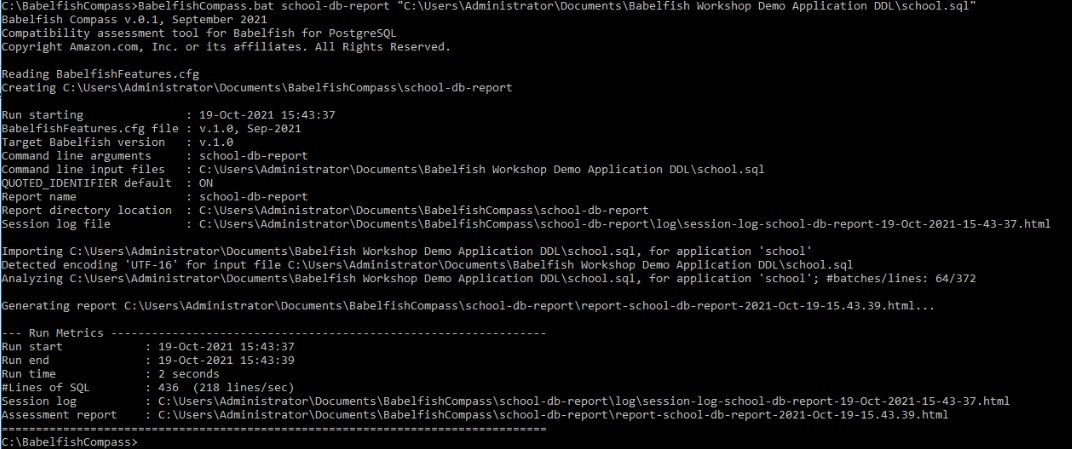
For this post, we use the School Sample Database. You can copy the DDL for this database and save it in a file. We saved the file in the folder C:BabelfishCompasstest. To analyze this script, you must run the following command line:
{kind=link}
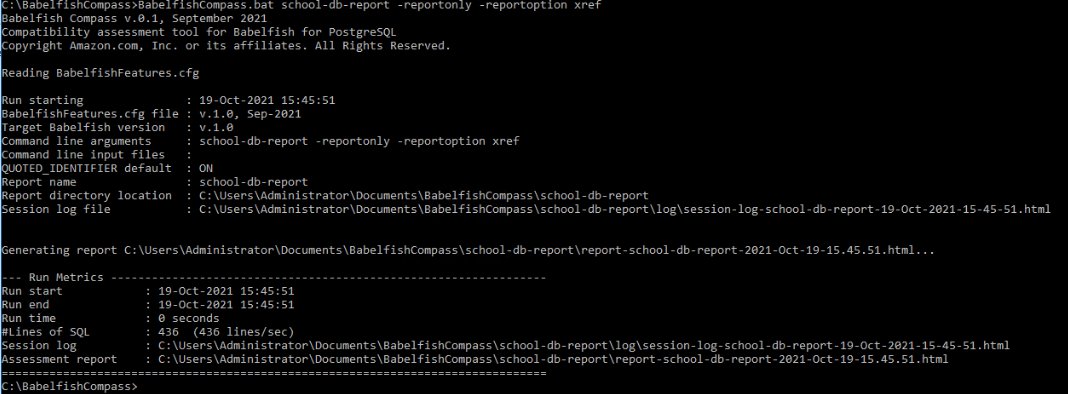
After you run the assessment, the report opens in your browser. This report has a summary of SQL features found that are supported or unsupported by Babelfish. To generate a cross-reference with the exact location of each non-supported feature, run the following command line:
{kind=link}
Reports are located in C:UsersAdministratorDocumentsBabelfishCompass under the YourFirstReportName directory.
{kind=link}
Review the Babelfish Compass assessment report
The Babelfish Compass assessment report contains an assessment based on the resources you scanned with the Babelfish Compass tool. This report lists applications analyzed along with the summary and SQL features report.
Please note that the version of Babelfish being used in this article is version 1.0. Limitations discussed apply to this version.
{kind=link}
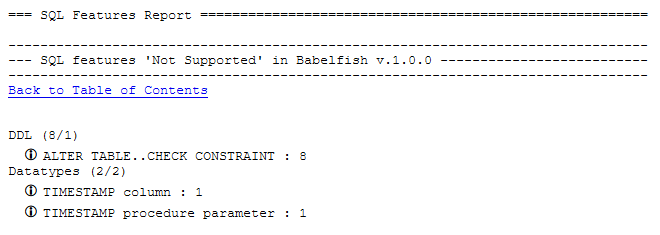
The assessment summary shows the list of objects analyzed, including supported and unsupported features. In the next section of the report, we can see the SQL features report starting from unsupported features.
{kind=link}
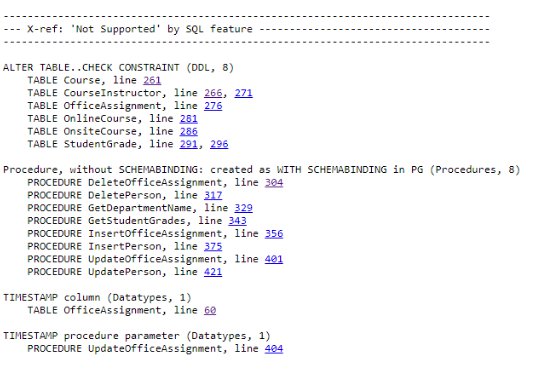
In the case above the TIMESTAMP column is supported in both SQL Server and PostgreSQL, but there is a reason for listing this as unsupported. In SQL Server, TIMESTAMP is a synonym for the ROWVERSION data type whereas in PostgreSQL it allows you to store both date and time and not a synonym for the ROWVERSION. The TIMESTAMP datatype is not supported by the current version of Babelfish for Aurora PostgreSQL. Therefore, you need to change to DATETIME datatype and evaluate your application to make sure it’s not impacting your functionality before proceeding.
{kind=link}
In the following example, you can see ALTER TABLE..CHECK CONSTRAINT is not supported by the current version of Babelfish for Aurora PostgreSQL.
Also, CLUSTERED constraints are not supported by the current version of Babelfish for Aurora PostgreSQL. These constraints are still created as if NONCLUSTERED. You need to review the impact on row ordering and its importance within your application before proceeding further.
{kind=link}
You can review these using the cross-reference report which links to the exact location of each non-supported feature. The following screenshot shows the cross-reference section. You can click on the line number, which takes you to the SQL for this unsupported feature, so you can review the details. In our case, we choose Table OfficeAssignment, line 60.
{kind=link}
The following screenshot shows us the DDL.
{kind=link}
School Sample Database – EF6” School Sample Database for Entity Framework 6, by ajcvickers is licensed under CC BY 4.0
You can validate the remaining observations in the same fashion and then use the updated DDL to populate the Babelfish database.
Create a Babelfish cluster
You can find the detailed step-by-step instructions on how to create the Babelfish cluster and connect to the Babelfish database using SSMS or SQLCMD in the documentation.
Populate the Babelfish database
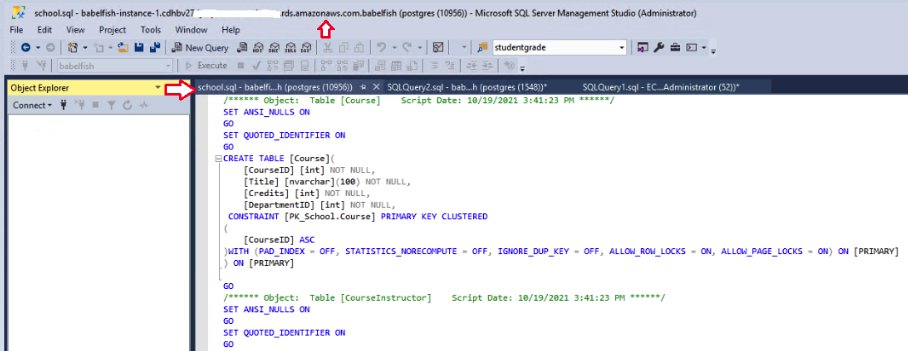
As mentioned in the documentation, you can connect to the Babelfish database using the Babelfish TDS endpoint listening 1433 in SSMS query editor and run the queries from there. In this case, open the School sample database DDL file using SSMS (by default, it’s connected to the primary database; choose the query window (right-click) to disconnect and then reconnect using the Babelfish cluster endpoint and credentials).
Similarly, you can use standard SQLServer command line utility sqlcmd to create and populate the database.
In the following screenshot, I connected to the Babelfish database using SSMS and ran the updated DDL script.
{kind=link}
School Sample Database – EF6” School Sample Database for Entity Framework 6, by ajcvickers is licensed under CC BY 4.0
When the assessment is complete and you have created the database, to populate your Babelfish database, you can follow the same steps as generating the DDL using SSMS. However, for Types of data to script, choose Data Only, which generates the SQL statements for populating your database.
Accessing Babelfish tables from PostgreSQL
The database tables and data used by Babelfish are also available to the PostgreSQL engine. You can access your database simultaneously using a Babelfish connection and a separate native PostgreSQL connection in the same application.
You connect to the Babelfish-enabled database from PostgreSQL by using the Aurora PostgreSQL endpoint on port 5432 by default.
For details about connecting to a DB cluster using Aurora PostgreSQL, see Connecting to an Amazon Aurora PostgreSQL DB cluster.
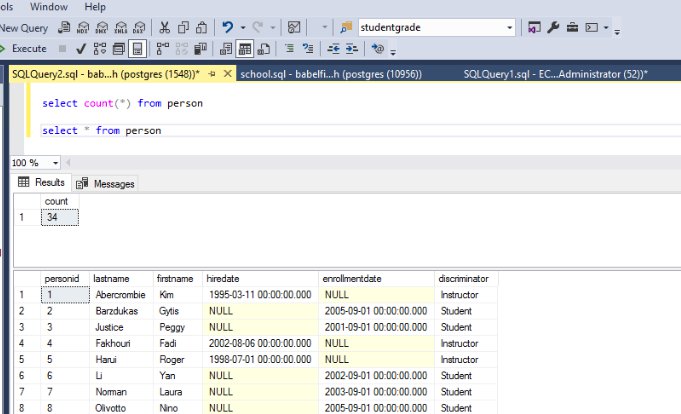
Validate the migrated data and test the functionality using TDS and PostgreSQL endpoints
After you run the DDL, let’s confirm that we can see the same results between the TDS and PostgreSQL endpoints.
{kind=link}
School Sample Database – EF6” School Sample Database for Entity Framework 6, by ajcvickers is licensed under CC BY 4.0
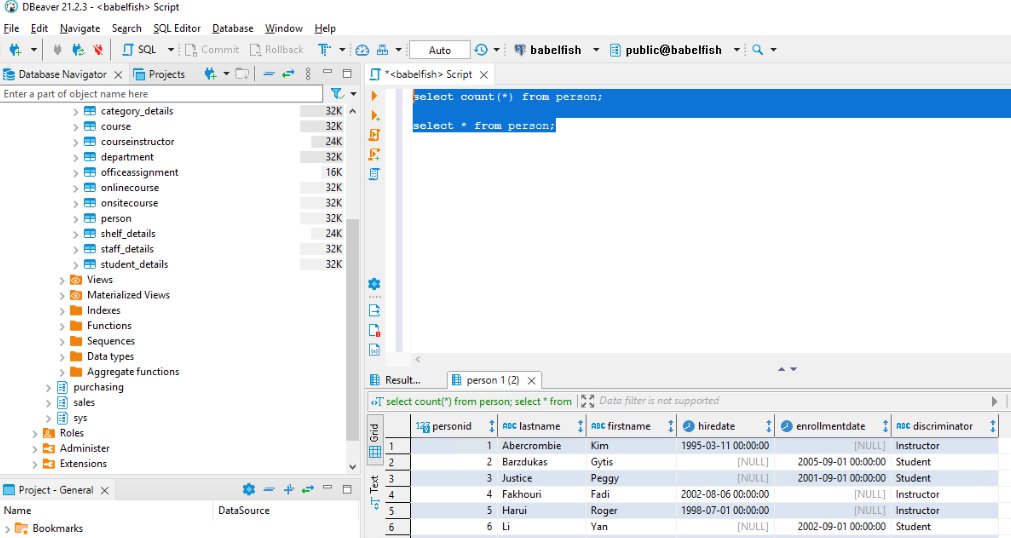
We run the same query using the PostgreSQL endpoint using the DBeaver community edition.
{kind=link}
School Sample Database – EF6” School Sample Database for Entity Framework 6, by ajcvickers is licensed under CC BY 4.0
{kind=link}
School Sample Database – EF6” School Sample Database for Entity Framework 6, by ajcvickers is licensed under CC BY 4.0
New functionality development
Let’s create some new functionality using T-SQL syntax in SSMS and confirm that it’s working. For example, let’s say you want the application to create a new trigger to list the updated rows when someone updates the person table:
School Sample Database – EF6” School Sample Database for Entity Framework 6, by ajcvickers is licensed under CC BY 4.0
{kind=link}
Let’s update the person table and the trigger gets executed (a SELECT statement of the updated rows). For clarity, the row before updating was selected to showcase the value is getting updated.
School Sample Database – EF6” School Sample Database for Entity Framework 6, by ajcvickers is licensed under CC BY 4.0
{kind=link}
As we can see, the row was updated and the trigger is working correctly as it displays the updated row. We have successfully migrated and tested an existing T-SQL application to Babelfish, including the new functionality development.
Availability and Limitations
The following limitations apply to version 1.0 of Babelfish.
Babelfish for Aurora PostgreSQL supports the following features with the following restrictions:
Works with Aurora PostgreSQL engine version 13.4 or later.
Supports snapshot creation and restore.
A Babelfish-enabled DB cluster supports a single Babelfish database.
The following Aurora limitations apply to Babelfish:
AWS Identity and Access Management (IAM) database authentication is currently not supported for Babelfish logins.
Amazon RDS Proxy is currently not supported for the TDS endpoint.
Summary
In this post, we showed the steps involved in migrating a SQL Server application to Babelfish with Aurora PostgreSQL, including using the Babelfish Compass tool to determine what extent of T-SQL code will be supported by Babelfish, the steps to review the report and fix the DDL for any unsupported features and new functionality development. Because most of the SQL features in the demo application are supported by Babelfish, this application could be migrated to PostgreSQL with minimal effort.
For more information about this feature and the Babelfish for Aurora PostgreSQL service, see the AWS Babelfish documentation.
If you have any questions, comments, or suggestions, please leave a comment below.
About the Author
Ramesh Kumar Venkatraman is a Solutions Architect at AWS who is passionate about containers and databases. He works with AWS customers to design, deploy and manage their AWS workloads and architectures. In his spare time, he loves to play with his two kids and follows cricket.
{kind=link}
Read MoreAWS Database Blog