
 for relational database users")
{kind=link}
Traditionally, companies have run most of their workloads using relational databases, and they have been the most popular choice for data management for over three decades. Relational databases are rooted in the relational model as proposed by E.F. Codd and C.J. Date in the 1980s. Relational databases support a wide variety of use cases, from highly transactional systems (like bank accounts or inventory management) to analytical systems (like data warehouses and business intelligence), and also for many general-purpose workloads (like web applications). The tabular schemas and set-based declarative query models are a particularly good fit for workloads in which records are statically structured, and the relationships between records are formal but highly flexible.
Over the last 10 years, I have worked as a data architect, as a database administrator, and now as a database specialist at AWS. And I have worked with hundreds of different applications, many of which were being built from scratch. In this tenure, I have witnessed a paradigm shift in the way applications are developed. Many modern applications, such as ecommerce order processing systems and catalog management systems, must keep pace with rapidly evolving business needs. In these applications the data model of traditional relational databases can become cumbersome or constraining. For example, as new product categories are added, the schema of a product catalog table will constantly need to be modified to accommodate new attributes unique to certain products. Similarly, an order table will have to be altered when you want to capture details which were not needed earlier. Additionally, for use cases such as these, developers typically store and query for complex objects that are not directly supported in the relational type system – e.g., catalog items and orders. Normalizing these data, joining across tables, and using object-relational mappers add complexity, impacting development velocity as well as query performance.
The JSON document data model is one of the primary alternatives to relational data model, and is well suited to these use cases. Many relational databases such as PostgreSQL offer the ability to store and query data as a JSON documents. You can store relational data and JSON data side by side and query them together or separately using structured query language (SQL) with Amazon Relational Database Service (Amazon RDS) for PostgreSQL and Amazon Aurora PostgreSQL-Compatible Edition. JSON capabilities in relational databases are great when you want to store both relational and JSON data side by side and query them with complex constructs such as JOIN. But for applications which primarily deal with data that can be best represented using hierarchical JSON documents, a native JSON database system will improve productivity. As a native JSON database system, Amazon DocumentDB (with MongoDB compatibility) implements a query language designed for JSON data, provides indexing capabilities designed for JSON data, and supports open source MongoDB database drivers, and tools. It is also fully managed and purpose built by AWS for security, durability, availability, and scalability. In my experience this is an excellent way to build systems that require flexibility in data structures, or simply don’t fit well with the relational approach to querying data.
Developers who are well versed in building application with relational databases, may find it challenging when they first move to a native JSON database. Data modeling for Amazon DocumentDB is different from normalized relational data modeling. Despite the differences, I have seen many developers succeed at designing an efficient document data model for their business use case, once they learn a few new concepts. This post is intended as an introduction to data modeling in a native JSON database. We cover the concepts of Amazon DocumentDB schema design and data modeling, and how it’s different from relational data modeling concepts.
What is a document database?
A document database is a type of non-relational database that is designed to store and query data as JSON-like documents. This approach has two primary advantages for certain workloads:
Document databases make it easier for developers to store and query data in a database because the document-model format maps cleanly to the data structures that programmers use in their application code
The flexible, semi-structured, and hierarchical nature of documents and document databases allows them to evolve with applications’ needs.
Document databases such as Amazon DocumentDB offer seamless translation between schema and application data types. It makes Amazon DocumentDB an ideal choice for workloads that store and manipulate data, where attributes can be different across records or evolve rapidly with business changes. You can store a document containing information for a product of type “shoes” which has attributes “color” and “size” along with documents for a product from a newly launched category representing mobile phone, which has attributes such as “screen size”, “processor”, and “operating system”.
Representing product catalog which only has shoes, is straight forward with a normalized schema:
product_id
product_category
product_description
brand
size
color
search_tag1
search_tag2
1
casual shoes
ABC Sneakers Size 7 (Red)
ABC
7
red
sneakers
casual shoes
2
sports shoes
ABC Basketball Shoes Size 8 (White)
ABC
8
white
sports shoes
basketball shoes
3
casual shoes
ABC Sneakers Size 8 (Black)
ABC
8
black
sneakers
casual shoes
But as the business evolves and catalog must be redesigned to support new type of products with different attributes, the data model has to be modified. Here is an example of how the data for a more diverse catalog can be represented in a relational database across normalized tables:
products
product_id
product_category
product_description
brand
subcategory
1
shoes
ABC Sneakers Size 7 (Red)
ABC
casual shoes
2
shoes
ABC Basketball Shoes Size 8 (White)
ABC
sports shoes
3
shoes
ABC Sneakers Size 8 (Black)
ABC
casual shoes
4
mobile
XYZ Smartphone 6
XYZ
smart phone
5
mobile
XYZ Smartphone 5
XYZ
smart phone
product_attributes
product_id
product_attribute
attribute_value
1
size
7
1
color
red
2
size
8
2
color
white
3
size
8
3
color
black
4
operating_system
android
4
battery
4000 mAH
4
screen_size_inches
6.3
5
operating_system
android
5
battery
3200 mAH
5
screen_size_inches
5.1
product_tag
product_tag_id
product_id
tag1
1
sneakers
tag2
1
casual shoes
tag3
3
sneakers
tag4
3
casual shoes
tag5
2
sports shoes
tag6
2
basketball shoes
tag7
4
smart phone
tag8
4
android phone
tag9
5
smart phone
tag10
5
android phone
product_variants
product_id
variant_id
1
3
This data can be represented in document model using a document for each product:
Similarly, an order processing system using Amazon DocumentDB does not require schema changes in the database when orders are placed for newly launched items such as “mobile phone” which may require tracking additional information “device id” for every order. In fact the flexible schema allows combining a “book” with “isbn” and “edition” details, and a coffee machine along with the order that has “mobile phone”.
JSON data model
Most programmers have some familiarity with the relational model. A database is a set of tables. Tables have rows that represent entities (for example individual customers, or products), and columns that represent features of those entities (e.g. name, address, or size). The definition of the tables and columns is called a schema, and relational databases enforce disciplined adherence to the schema (such as data types of columns, or the number of columns in a row), as well as a formal mechanism for changing the schema (DDL commands). A record of an object or event in a relational database is a row, and this works extremely well for a lot of transactional business data, but it is not ideal for many modern workloads.
In a relational database all rows have the same number and types of columns. You can modify a schema definition for a table, but the change applies to all the rows. However, for some applications each row would naturally have a different structure from the others. For example, a table that needs to store a bill of materials (BOM) in each row is a challenge, because a BOM typically has a tree structure, and each BOM could have structural variations (e.g. a high-end version of a car could have more components than a low-end version). Traditional solutions to this vary from highly normalized approaches, in which many tables are involved in complex JOIN operations to reconstruct the tree structure (BOM in this case), to storing the data as a binary unit that is opaque to the database (e.g. binary large objects or BLOBS). Today, many relational databases address this by supporting a JSON data type. In these systems you can define a column as a JSON type and use JSON functions in SQL to query data. Some of the concepts that we cover in this post regarding document models also apply to applications that use the native JSON capabilities of a relational database, but there are important differences between relational databases with JSON extensions and native JSON databases. Native JSON databases are purpose built for these workload types, and have capabilities beyond what relational database with JSON offer: 1/ richer JSON querying, manipulation, and indexing, 2/ more innate programming interface for applications developers, and 3/ targeted designs and optimization for JSON-specific performance.
JSON Database Specifics
A document database stores data as collection of documents. JSON represents data in two ways:
Object – A collection of name-value (or key-value) pairs. An object is defined within braces ({}). Each name-value pair begins with the name, followed by a colon, followed by the value. Name-value pairs are comma separated.
Array – An ordered collection of values. An array is defined within brackets ([]). Items in the array are comma separated.
A JSON document can have one or more fields and their values. The following are the common data types that are usually used in document databases and are supported by Amazon DocumentDB:
String – A combination of alphanumeric and special characters.
Number – Positive or negative numbers (integers, decimals, and floating point numbers).
Date – Date and timestamp.
Array – You can have an array of values in a document, which means that unlike relational databases, multi-valued attributes can be stored in-line with a document and don’t need to be stored in a separate table. Members of an array list can be of one the primitive data types (string, number, or date) or a nested document. You can have an array list storing members with a different data type, for instance a user’s memorable_code could be a combination of number and strings, such as [15,10,’DORY THE FISH’]. See the following example code:
Nested document – You can nest a JSON document within a JSON document. In a relational database, you break down a complex record that has additional details, and store them separately in a child table linked via foreign key. In a document database, you can simply store a complex record as a single document. See the following example, which represents a document for a customer with embedded account details:
In Amazon DocumentDB, documents of the same type of entity are stored together in a collection. In case of user profile, documents of all users are stored together in the users collection. You can think of a collection as the equivalent of a table from relational databases. Two different documents in a collection can have different sets of fields and use different data types for the same field. The flexibility that the document model provides enables you to iterate quickly without having to change the schema of your database.
A document can also have an array of nested documents. Consider a scenario where a user has multiple addresses. They can be stored as an array of nested address documents in users collection.
Relational databases and JSON document database terminology
The following table compares the nomenclature used by JSON document databases with terminology used by relational databases using SQL.
Relational database (SQL)
JSON document database
Table
Collection
Row
Document
Column
Attribute
Primary key
Object ID
Index
Index
Nested table or object
Nested or embedded document
Array
Array
Data model considerations
One important element of designing data models is whether or not the model is normalized. Normalization refers to whether data records refer to other data records, or simply incorporate a copy of the content. For example, a transaction record that captures a purchase by a certain customer of a certain product could include all of the customer details and all of the product details (not normalized), or instead it could contain a reference to the customer and a reference to the product, each of which would have content stored in another table (normalized). For many applications the advantages of normalization are compelling, namely that all of the data is stored uniquely and independently, can be updated separately, and takes up less space. On the other hand, normalization can require more complex queries, can be considerably more computationally demanding at query time, and can introduce complex requirements for enforcing application-specific data integrity rules (eg no deletion from a product table if there are any records in a transaction table that still refer to a product that would be deleted).
Both SQL and document models can work with either normalized and non-normalized data models, however the document model is better suited for applications that favor denormalized data, and the SQL model is better suited for applications that favor normalized data.
A document model is different from a data model that uses third normal form (3NF) to avoid duplication of data and uses foreign keys to represent relationship among tables. For example, in a typical normalized relational model, information for a user profile (such as address, city, and state) isn’t stored in the same table as the user details. The following diagram depicts this data model.
Normalized data model
Normalizing a data model is a popular design paradigm with relational databases. A data model such as the one below reduces the redundancy of data, by relying on data records being referenced by other records. There are multiple levels of normalization, including First, Second and Third Normal Form (1NF, 2NF, 3NF).
{kind=link}
In the above example, separate tables are used to store zipcode, city, and state. In the users table, you can use the userid to uniquely identify a user. In relational databases, that’s typically referred as the primary key or unique key. In the address table, you can refer to details related to city and state by simply storing the zipcode, and the details of the city and state related to the zipcode are stored in a separate table. That ensures that the city and state details aren’t repeated several times for multiple addresses that belong to the same zipcode.
A normalized data model in relational databases use foreign keys (FK)s and referential integrity constraints to ensure data integrity between records in different tables. In the example schema with address and zipcode tables, a constraint can be imposed to ensure the address only stores valid Zip Codes. To handle a many-to-many relationship, such as when a user has multiple addresses, and an address can be shared by multiple users, a link table is used.
The normalized data model can be helpful when you have to modify only one attribute that affects all users. Let’s consider an example, where borders are being changed to move a zipcode from one state to another state, you only have to update one row in the zipcode table:
In a normalized data model, because related data is spread across multiple tables, developers use joins and transactions to design applications that access data across multiple tables. You can update data across multiple entities (typically referred to as tables) atomically using transactions, and combine data from several tables using a complex join or subquery expression in SQL language.
Relational databases do not require normalized data models. In the example above, it is entirely possible to maintain separate copies of the Zip Code data (City and State) in the address table, rather than having a separate zipcode table. The same is true of the Address table. Each record in the user table could simply maintain a copy of the entire address (possibly including Zip Code data), rather than a reference to the address in a separate table referenced by FK column pimaryaddress. It is common for real world relational databases to not be fully normalized, but relational database systems are optimized to be really good at managing normalized data.
Selective normalization/denormalization with Amazon DocumentDB
Amazon DocumentDB allows you to selectively normalize your data as needed by your application access patterns. Data that is accessed together can be stored together. For our document model, you can store the data for a user in a single record:
While retrieving information from a document database, you can fetch all information in a single query, instead of querying data across multiple tables using a JOIN. Application developers can directly map an entity in an application to a document. A single user’s record can be represented as a dictionary in Python, or as a class in Java. Being able to express data natively in the form of available data structures in a programming language avoids impedance mismatches between database objects and application data structures. A better impedance match ensures that application developers don’t need to maintain additional mappings using an Object Relational Mapping (ORM) layer. Moreover, Amazon DocumentDB supports joins to combine data from two collections, which should only be used when absolutely needed.
When related data is stored together, you don’t need foreign keys and complex transactions to update details that span across multiple tables in a consistent way. Whenever you need to update user information, the application code can update all the fields in one step and the database writes the whole document back to storage. Hence, updates that need to change most of the details about a user can be done with a single update and will perform much more efficiently.
An operation making a change to multiple documents of a collection in Amazon DocumentDB is always atomic. Let’s say you are updating the name of a building based on locality and zip code for all users. The change will be visible for every document only after the operation completes for all the documents. From Amazon DocumentDB v4.0 onwards, you can also use database transactions to effect an atomic change that spans multiple collections.
Flexible schema
Another aspect where the normalized data model and document data model differ is change management. A normalized data model implemented using tables and columns imposes a schema validation on writes (insert, update, and delete). You have to define a schema before inserting any data to the table. If your business requirement needs changes to the data model, you need to change the table schema accordingly. The addition of a new attribute or field (typically referred to as a column in relational databases) shouldn’t override the rules of normalization.
Depending on the nature of the change, you may need to split up an existing table into two tables to adhere to the rules of normalization. Imagine that the application that is using the user database from our example needs to accommodate users that may have more than one contact number. To accommodate this request, we have to take out the mobile number field from the user table and introduce a new table to store contact information. The following diagram illustrates this change:
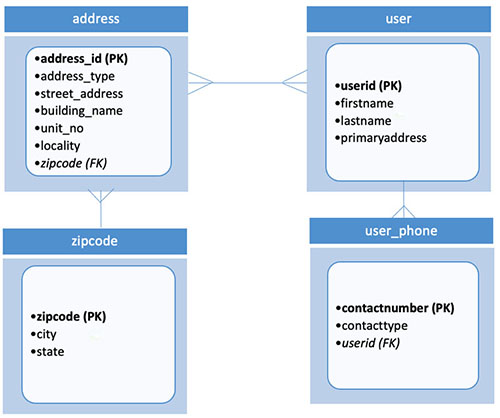{kind=link}
Modifying the table schema requires changes to the application code to handle an insert to one more table. Changing the data model also requires data migration to migrate existing data from the contactnumber column to a new table, and may also result in downtime.
With document models, a schema validation isn’t imposed during insert, update, or delete operations. Implementing a change to the contact number is much easier and can be handled by simply making a change to the application to insert an array of nested documents, instead of inserting a single value. With document databases, schema design plays an important role in how data is read and accessed. Any query that assumed that contactnumber stores a single value, must be changed. To allow for different versions of the application API to access data, you can introduce the new field contactdetails, which is used for new documents:
Amazon DocumentDB supports a flexible data model of JSON documents. Data is stored and retrieved in JSON documents. The following document represents the user profile data for the user John Doe:
Field names are recorded for every document, and two documents in a collection can have a different set of fields and a different structure. You may use OAuth to allow users to sign up using their Google or Facebook profiles. In that case, your application creates an initial user profile with fewer fields in the document, and allows users to add these details later on:
Access patterns
Relational databases have access patterns where data stored in normalized tables is queried using joins and flexible filter criteria. You can also specify a list of fields or columns that you want to include in the output. For example, you can select only the firstname of those users who have the lastname as Doe:
Similar to relational databases, document databases also allow users to specify filter and projection (fields to be included in output) operators in a query. You can express the same query in Amazon DocumentDB as the following code:
Just like relational databases, document databases allow you to perform insert, update, and delete operations. You can also specify a filter criterion while updating or deleting documents, and you can even perform an upsert operation—that is, the database updates an existing document (based on a unique ID) and if it doesn’t exist, it inserts a new document.
Document databases like Amazon DocumentDB support advanced functionalities often found in relational databases like aggregation queries and logical operators for filter expression (such as AND, OR, and so on). Amazon DocumentDB also supports applying filters based on nested documents, an array, and an array of documents. These flexible filtering capabilities are helpful to query and perform updates on a denormalized collection of documents. Amazon DocumentDB also supports joins and transactions to retrieve and update data in different collections.
Flexible indexing
Relational databases support secondary indexes, which improves query performance. Different relational databases support different indexes, but the most common one is BTree indexes.
Amazon DocumentDB supports BTree indexes on an attribute or a combination of attributes, similar to relational database indexes, to improve data retrieval. Amazon DocumentDB also supports the concept of unique indexes. Additionally, to support queries on nested documents and arrays, Amazon DocumentDB supports indexes on nested attributes and array fields.
Conclusion
In this post, we covered a few key concepts of data modeling for Amazon DocumentDB:
Data modeling for document stores such as Amazon DocumentDB is very different from data modeling for relational databases. You can’t apply the same normalization concepts that you typically use for creating a data model using tables and relations in relational databases.
A document is a self-sufficient record that also contains field names. Two documents of the same type can have different sets of attributes, so instead of storing NULL or blank, you can simply skip the details that aren’t applicable to a record.
A document data model allows for complex hierarchy and multi-valued attributes to be stored in a single document.
A document data model makes it very convenient for users to store and retrieve fields together without the need for joins and atomic transactions that span multiple tables.
Support for flexible query operators and indexes makes Amazon DocumentDB a great choice for workloads that need to have a flexible schema and perform ad hoc queries across a collection of documents.
We also covered some scenarios where using a document database makes application development simpler as compared to relational databases.
You can go to the AWS Management Console to spin up a new Amazon DocumentDB cluster and use an Amazon Elastic Compute Cloud (Amazon EC2) instance, AWS Cloud9, or Robo 3T to access your database. For more information, see the following:
Getting started with Amazon DocumentDB (with MongoDB compatibility); Part 1 – using Amazon EC2)
Getting Started with Amazon DocumentDB (with MongoDB compatibility); Part 2 – using AWS Cloud9)
Getting started with Amazon DocumentDB (with MongoDB compatibility); Part 3 – using Robo 3T)
You can also use AWS Database Migration Service (AWS DMS) to migrate relational databases to Amazon DocumentDB, and reduce the overhead of schema maintenance and ORM layers.
About the Authors
Sameer Kumar is a Database Specialist Technical Account Manager at Amazon Web Services. He focuses on Amazon RDS, Amazon Aurora and Amazon DocumentDB. He works with enterprise customers providing technical assistance on database operational performance and sharing database best practices.
Read MoreAWS Database Blog