

{kind=link}
Amazon’s intelligent document processing (IDP) helps you speed up your business decision cycles and reduce costs. Across multiple industries, customers need to process millions of documents per year in the course of their business. For customers who process millions of documents, this is a critical aspect for the end-user experience and a top digital transformation priority. Because of the varied formats, most firms manually process documents such as W2s, claims, ID documents, invoices, and legal contracts, or use legacy OCR (optical character recognition) solutions that are time-consuming, error-prone, and costly. An IDP pipeline with AWS AI services empowers you to go beyond OCR with more accurate and versatile information extraction, process documents faster, save money, and shift resources to higher value tasks.
In this series, we give an overview of the IDP pipeline to reduce the amount of time and effort it takes to ingest a document and get the key information into downstream systems. The following figure shows the stages that are typically part of an IDP workflow.
In this two-part series, we discuss how you can automate and intelligently process documents at scale using AWS AI services. In part 1, we discussed the first three phases of the IDP workflow. In this post, we discuss the remaining workflow phases.
Solution overview
The following reference architecture shows how you can use AWS AI services like Amazon Textract and Amazon Comprehend, along with other AWS services to implement the IDP workflow. In part 1, we described the data capture and document classification stages, where we categorized and tagged documents such as bank statements, invoices, and receipt documents. We also discussed the extraction stage, where you can extract meaningful business information from your documents. In this post, we extend the IDP pipeline by looking at Amazon Comprehend default and custom entities in the extraction phase, perform document enrichment, and also briefly look at the capabilities of Amazon Augmented AI (Amazon A2I) to include a human review workforce in the review and validation stage.
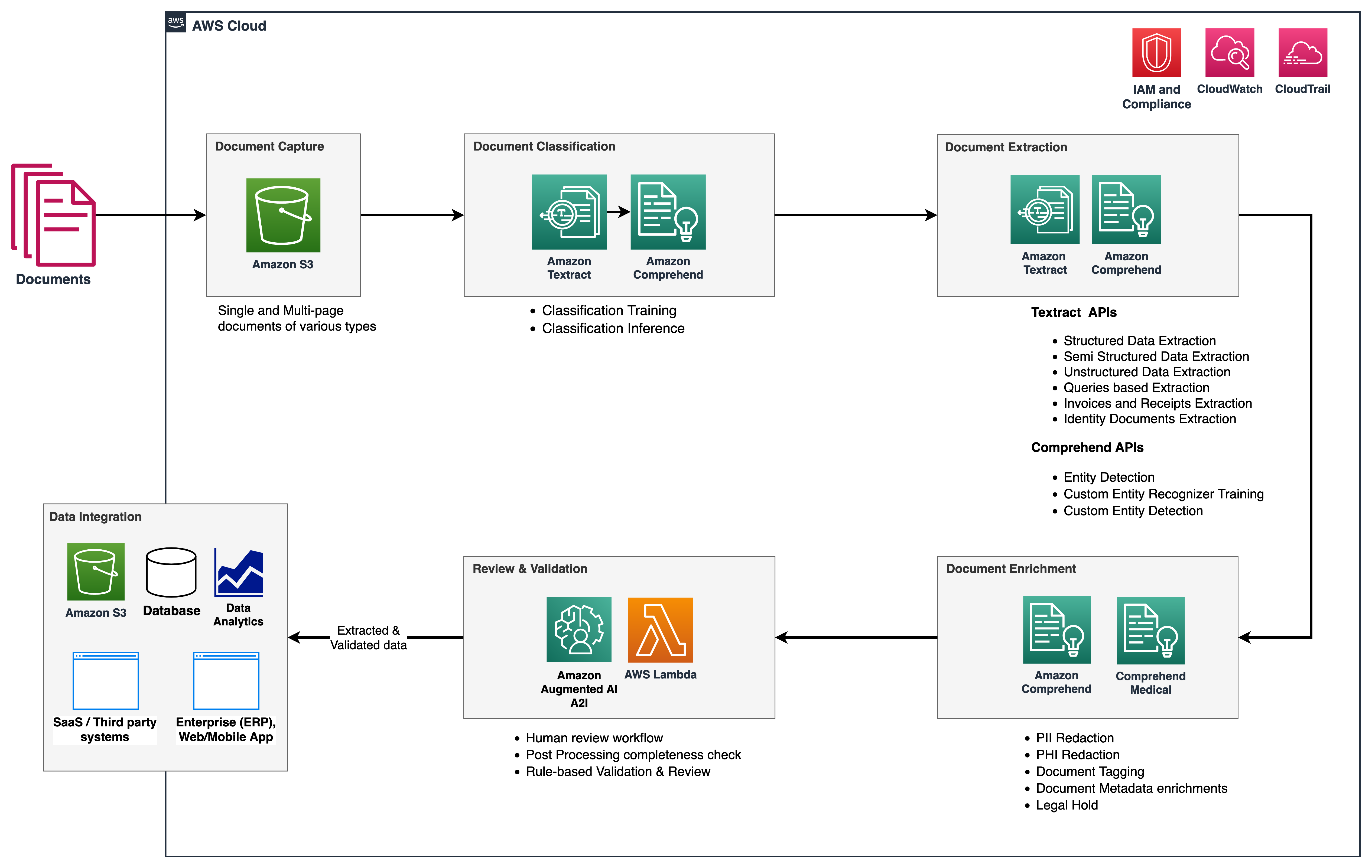{kind=link}
We also use Amazon Comprehend Medical as part of this solution, which is a service to extract information from unstructured medical text accurately and quickly and identify relationships among extracted health information, and link to medical ontologies like ICD-10-CM, RxNorm, and SNOMED CT.
Amazon A2I is a machine learning (ML) service that makes it easy to build the workflows required for human review. Amazon A2I brings human review to all developers, removing the undifferentiated heavy lifting associated with building human review systems or managing large numbers of human reviewers whether it runs on AWS or not. Amazon A2I integrates with Amazon Textract and Amazon Comprehend to provide you the ability to introduce human review steps within your IDP workflow.
Prerequisites
Before you get started, refer to part 1 for a high-level overview of IDP and details about the data capture, classification, and extraction stages.
Extraction phase
In part 1 of this series, we discussed how we can use Amazon Textract features for accurate data extraction for any type of documents. To extend this phase, we use Amazon Comprehend pre-trained entities and an Amazon Comprehend custom entity recognizer for further document extraction. The purpose of the custom entity recognizer is to identify specific entities and generate custom metadata regarding our documents in CSV or human readable format to be later analyzed by the business users.
Named entity recognition
Named entity recognition (NER) is a natural language processing (NLP) sub-task that involves sifting through text data to locate noun phrases, called named entities, and categorizing each with a label, such as brand, date, event, location, organizations, person, quantity, or title. For example, in the statement “I recently subscribed to Amazon Prime,” Amazon Prime is the named entity and can be categorized as a brand.
Amazon Comprehend enables you to detect such custom entities in your document. Each entity also has a confidence level score that Amazon Comprehend returns for each entity type. The following diagram illustrates the entity recognition process.
To get entities from the text document, we call the comprehend.detect_entities() method and configure the language code and text as input parameters:
We run the get_entities() method on the bank document and obtain the entity list in the results.
Although entity extraction worked fairly well in identifying the default entity types for everything in the bank document, we want specific entities to be recognized for our use case. More specifically, we need to identify the customer’s savings and checking account numbers in the bank statement. We can extract these key business terms using Amazon Comprehend custom entity recognition.
Train an Amazon Comprehend custom entity recognition model
To detect the specific entities that we’re interested in from the customer’s bank statement, we train a custom entity recognizer with two custom entities: SAVINGS_AC and CHECKING_AC.
Then we train a custom entity recognition model. We can choose one of two ways to provide data to Amazon Comprehend: annotations or entity lists.
The annotations method can often lead to more refined results for image files, PDFs, or Word documents because you train a model by submitting more accurate context as annotations along with your documents. However, the annotations method can be time-consuming and work-intensive. For simplicity of this blog post, we use the entity lists method, which you can only use for plain text documents. This method gives us a CSV file that should contain the plain text and its corresponding entity type, as shown in the preceding example. The entities in this file are going to be specific to our business needs (savings and checking account numbers).
For more details on how to prepare the training data for different use cases using annotations or entity lists methods, refer to Preparing the training data.
The following screenshot shows an example of our entity list.
Create an Amazon Comprehend custom NER real-time endpoint
Next, we create a custom entity recognizer real-time endpoint using the model that we trained. We use the CreateEndpoint API via the comprehend.create_endpoint() method to create the real-time endpoint:
After we train a custom entity recognizer, we use the custom real-time endpoint to extract some enriched information from the document and then perform document redaction with the help of the custom entities recognized by Amazon Comprehend and bounding box information from Amazon Textract.
Enrichment phase
In the document enrichment stage, we can perform document enrichment by redacting personally identifiable information (PII) data, custom business term extraction, and so on. Our previous sample document (a bank statement) contains the customers’ savings and checking account numbers, which we want to redact. Because we already know these custom entities by means of our Amazon Comprehend custom NER model, we can easily use the Amazon Textract geometry data type to redact these PII entities wherever they appear in the document. In the following architecture, we redact key business terms (savings and checking accounts) from the bank statement document.
As you can see in the following example, the checking and savings account numbers are hidden in the bank statement now.
Traditional OCR solutions struggle to extract data accurately from most unstructured and semi-structured documents because of significant variations in how the data is laid out across multiple versions and formats of these documents. You may then need to implement custom preprocessing logic or even manually extract the information out of these documents. In this case, the IDP pipeline supports two features that you can use: Amazon Comprehend custom NER and Amazon Textract queries. Both these services use NLP to extract insights about the content of documents.
Extraction with Amazon Textract queries
When processing a document with Amazon Textract, you can add the new queries feature to your analysis to specify what information you need. This involves passing an NLP question, such as “What is the customer’s social security number?” to Amazon Textract. Amazon Textract finds the information in the document for that question and returns it in a response structure separate from the rest of the document’s information. Queries can be processed alone, or in combination with any other FeatureType, such as Tables or Forms.
With Amazon Textract queries, you can extract information with high accuracy irrespective of the how the data is laid out in a document structure, such as forms, tables, and checkboxes, or housed within nested sections in a document.
To demonstrate the queries feature, we extract valuable pieces of information like the patient’s first and last names, the dosage manufacturer, and so on from documents such as a COVID-19 vaccination card.
We use the textract.analyze_document() function and specify the FeatureType as QUERIES as well as add the queries in the form of natural language questions in the QueriesConfig.
The following code has been trimmed down for simplification purposes. For the full code, refer the GitHub sample code for analyze_document().
For the queries feature, the textract.analyze_document() function outputs all OCR WORDS and LINES, geometry information, and confidence scores in the response JSON. However, we can just print out the information that we queried for.
Document is a wrapper function used to help parse the JSON response from the API. It provides a high-level abstraction and makes the API output iterable and easy to get information out of. For more information, refer to the Textract Response Parser and Textractor GitHub repos. After we process the response, we get the following information as shown in the screenshot.
Review and validation phase
This is the final stage of our IDP pipeline. In this stage, we can use our business rules to check for completeness of a document. For example, from an insurance claims document, the claim ID is extracted accurately and successfully. We can use AWS serverless technologies such as AWS Lambda for further automation of these business rules. Moreover, we can include a human workforce for document reviews to ensure the predictions are accurate. Amazon A2I accelerates building workflows required for human review for ML predictions.
With Amazon A2I, you can allow human reviewers to step in when a model is unable to make a high confidence prediction or to audit its predictions on an ongoing basis. The goal of the IDP pipeline is to reduce the amount of human input required to get accurate information into your decision systems. With IDP, you can reduce the amount of human input for your document processes as well as the total cost of document processing.
After you have all the accurate information extracted from the documents, you can further add business-specific rules using Lambda functions and finally integrate the solution with downstream databases or applications.
For more information on how to create an Amazon A2I workflow, follow the instructions from the Prep for Module 4 step at the end of 03-idp-document-enrichment.ipynb in our GitHub repo.
Clean up
To prevent incurring future charges to your AWS account, delete the resources that we provisioned in the setup of the repository by navigating to the Cleanup section in our repo.
Conclusion
In this two-part post, we saw how to build an end-to-end IDP pipeline with little or no ML experience. We discussed the various stages of the pipeline and a hands-on solution with AWS AI services such as Amazon Textract, Amazon Comprehend, Amazon Comprehend Medical, and Amazon A2I for designing and building industry-specific use cases. In the first post of the series, we demonstrated how to use Amazon Textract and Amazon Comprehend to extract information from various documents. In this post, we did a deep dive into how to train an Amazon Comprehend custom entity recognizer to extract custom entities from our documents. We also performed document enrichment techniques like redaction using Amazon Textract as well as the entity list from Amazon Comprehend. Finally, we saw how you can use an Amazon A2I human review workflow for Amazon Textract by including a private work team.
For more information about the full code samples in this post, refer to the GitHub repo.
We recommend you review the security sections of the Amazon Textract, Amazon Comprehend, and Amazon A2I documentation and follow the guidelines provided. Also, take a moment to review and understand the pricing for Amazon Textract, Amazon Comprehend, and Amazon A2I.
About the authors
Chin Rane is an AI/ML Specialist Solutions Architect at Amazon Web Services. She is passionate about applied mathematics and machine learning. She focuses on designing intelligent document processing solutions for AWS customers. Outside of work, she enjoys salsa and bachata dancing.
{kind=link}
Sonali Sahu is leading Intelligent Document Processing AI/ML Solutions Architect team at Amazon Web Services. She is a passionate technophile and enjoys working with customers to solve complex problems using innovation. Her core areas of focus are artificial intelligence and machine learning for intelligent document processing.
{kind=link}
Anjan Biswas is an AI/ML specialist Senior Solutions Architect. Anjan works with enterprise customers and is passionate about developing, deploying and explaining AI/ML, data analytics, and big data solutions. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS.
{kind=link}
Suprakash Dutta is a Solutions Architect at Amazon Web Services. He focuses on digital transformation strategy, application modernization and migration, data analytics, and machine learning. He is part of the AI/ML community at AWS and designs intelligent document processing solutions.
{kind=link}
Read MoreAWS Machine Learning Blog