

{kind=link}
This post was created in collaboration with Mohammed Alauddin, Data Engineering and Data Science Regional Manager, and Kamal Hossain, Lead Data Scientist at iProperty.com.my, now part of PropertyGuru Group.
iProperty.com.my is the market-leading property portal in Malaysia and is now part of the PropertyGuru Group. iProperty.com.my offers a search experience that enables property seekers to go through thousands of property listings available in the market. Although the search function already serves its purpose in narrowing down potential properties for consumers, iProperty.com.my continues relentlessly to look for new ways to improve the consumer search experience.
The major driving force of reinvention for consumers within iProperty.com.my is anchored on data and machine learning (ML), with ML models being trained, retrained, and deployed for their consumers almost on a daily basis. These innovations include property viewing and location-based recommendations, which display a set of listings based on the search behavior and user profiles.
However, with more ML workloads deployed, challenges associated with scale began to surface. In this post, we discuss those challenges and how the iProperty.com.my Data Science team automated their workflows using Amazon SageMaker.
Challenges running ML projects at scale
When the iProperty.com.my Data Science team started out their ML journey, the team’s primary focus was identifying and rolling out ML features that would benefit their consumers. In iProperty.com.my , experimenting and validating newly defined hypotheses quickly is a common practice. However, as their ML footprint grew, the team’s focus gradually shifted from discovering new experiences to undifferentiated heavy lifting. The following are some of the challenges they encountered:
Operational overhead – Over time, they realized they had a variety of tools and frameworks to maintain, such as scikit-learn, TensorFlow, and PyTorch. Different ML frameworks were used for varying use cases. The team resorted to managing these framework updates via multiple self-managed container images, which was highly time-consuming. To keep up with the latest updates for each of these ML frameworks, frequent updates to the container images had to be made. This resulted in higher levels of maintenance, taking the team’s focus away from building new experiences for their consumers.
Lack of automation and self-service capabilities – ML projects involved multiple different teams, such as data engineering, data science, platform engineering, and product teams. Without end-to-end automation, the completion of tasks to launch a feature to market took more time, especially for tasks that had to be processed by multiple teams. As more projects crept in, the wait time between teams increased, impacting the time the feature was delivered to market. The lack of self-service capabilities also contributed to more time spent waiting for each other.
High cost – ML is an iterative process that requires retraining to keep models relevant. Depending on the use cases and the volume of data, training can be costly because it requires the use of powerful virtual machines. The other issue faced was every ML model deployed had its own inference instance, which meant that as more ML models were deployed, the cost went up linearly.
In light of these challenges, the team concluded they needed to rethink their process to build, train, and deploy models. They also identified the need to reevaluate their tooling to improve operational efficiency and manage their cost effectively.
Automating ML delivery with SageMaker
After much research, the team concluded that Amazon SageMaker was the most comprehensive ML platform that addressed their challenges. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. It provides self-service access to integrated Jupyter notebooks for easy access to the data sources for exploration and analysis, without the need to manage servers. With native and prebuilt support for various ML frameworks, such as PyTorch, TensorFlow, and MXNet, SageMaker offers flexible distributed training options that adjust to any specific workflows. The training and hosting are billed by the second, with no minimum fees and no upfront commitments. SageMaker also offers other attractive cost-optimization features such as managed spot training, which can reduce cost up to 90%, SageMaker Savings Plans, and multi-model endpoints that enable a single host to serve multiple models.
The final piece that wrapped everything together was the integration of SageMaker with iProperty.com.my’s continuous integration and continuous delivery (CI/CD) tooling.
To automate their ML delivery, the team redesigned their ML workflows with SageMaker as the underlying service for model development, training, and hosting, coupled with iProperty.com.my’s CI/CD tooling to automate the steps required to release new ML application updates. In the following sections, we discuss the redesigned workflows.
Data preparation workflow
With the introduction of SageMaker, the SageMaker notebook provided self-service environments with access to preprocessed data, which allowed data scientists to move faster with the CPU or GPU resources they needed.
The team relied on the service for data preparation and curation. It provided a unified, web-based visual interface providing complete access, control, and visibility into each step required to build, train, and deploy models, without the need to set up compute instances and file storage.
The team also used Apache Airflow as the workflow engine to schedule and run their complex data pipelines. They use Apache Airflow to automate the initial data preprocessing workflow that provides access to curated data.
The following diagram illustrates the updated workflow.
{kind=link}
The data preparation workflow has the following steps:
The Data Science team inspects sample data (on their laptop) from the data lake and builds extract, transform, and load (ETL) scripts to prepare the data for downstream exploration. These scripts are uploaded to Apache Airflow.
Multiple datasets extracted from iProperty.com.my’s data lake go through multiple steps of data transformation (including joins, filtering, and enrichment). The initial data preprocessing workflow is orchestrated and run by Apache Airflow.
The preprocessed data, in the form of Parquet, is stored and made available in an Amazon Simple Storage Service (Amazon S3) engagement data bucket.
On the SageMaker notebook instance, the Data Science team downloads the data from the engagement data S3 bucket into Amazon Elastic File System (Amazon EFS) to perform local exploration and testing.
More data exploration and data preprocessing activities take place to transform the engagement data into features that better represent the underlying problems to the predictive models.
The curated data is stored in the curated data S3 bucket.
After the data is prepared, the team performs local ML training and inference testing on the SageMaker notebook instance. A subset of the curated data is used during this phase.
Steps 5, 6, and 7 are repeated iteratively until satisfactory results are achieved.
ML model training and deployment workflow
The ML model training and deployment workflow relied on the team’s private Git repository to trigger the workflow implemented on the CI/CD pipeline.
The method implemented was that Git served as the one and only source of truth for configuration settings and source code. This approach required the desired state of the system to be stored in version control, which allowed anyone to view the entire audit trail of changes. All changes to the desired state are fully traceable commits associated with committer information, commit IDs, and timestamps. This meant that both the application and the infrastructure are now versioned through code and can be audited using standard software development and delivery methodology.
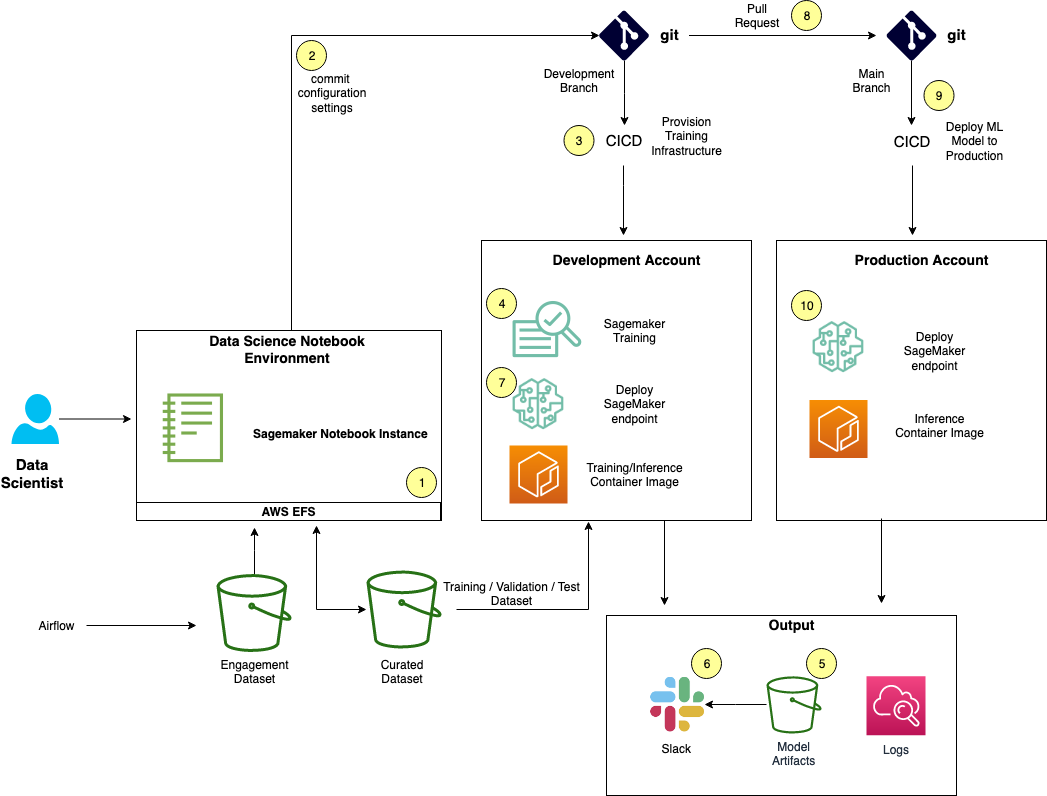
The following diagram illustrates this workflow.
{kind=link}
The workflow has the following steps:
With the data curated from the data preparation workflow, local training and inference testing is performed iteratively on the SageMaker notebook instance.
When the desired results are achieved, the Data Science team commits the configuration settings into Git. The configuration includes the following:
Data source location
Cluster instance type and size
SageMaker prebuilt container image to select the ML framework such as PyTorch, TensorFlow, or scikit-learn
Pricing model to select either Spot or On-Demand Instances.
The Git commit triggers the CI/CD pipeline. The CI/CD pipeline fires up a Python Boto3 script to provision the SageMaker infrastructure.
In the development AWS account, a new SageMaker training job is provisioned with the committed configuration settings with Spot Instances. The dataset from the curated data’s S3 bucket is downloaded into the training cluster, with training starting immediately.
After the ML training job is complete, a model artifact is created and stored in Amazon S3. Every epoch, evaluation metric, and log from the training job is stored in Amazon CloudWatch Logs.
When a model artifact is stored in Amazon S3, it triggers an event that invokes an AWS Lambda function to create a Slack notification that the training job is complete. The notification includes a link to the training job’s CloudWatch Logs for review.
If the Data Science team is satisfied with the evaluation report, the team unblocks the pipeline via an approval function in the CI/CD pipeline and kicks off a Python Boto3 script to deploy the ML model onto the SageMaker hosting infrastructure for further inference testing.
After validation, the team raises a Git pull request to have iProperty.com.my’s ML engineers perform the final review. The ML engineers may run more tests against the development environment’s SageMaker inference endpoint to validate the results.
If everything works as expected, the ML engineer merges the pull request that triggers the CI/CD pipeline to deploy the new model into the data production environment. The CI/CD pipeline runs a Python script to deploy the model on the SageMaker multi-model endpoint. However, if there are issues with the inference results, the pull request is declined with feedback provided.
The SageMaker hosting infrastructure is provisioned and the CI/CD workflow runs a health check script against the SageMaker inference endpoint to validate the inference endpoint’s health.
ML model serving and API layer workflow
For any ML use case, before any ML models are served to consumers, appropriate business logic must be applied to it. The business logic wraps the ML inferenced output (from SageMaker) with various calculations and computation to meet the use case requirements. In iProperty.com.my’s case, the business logic is hosted on AWS Lambda, with a separate Lambda function for every ML use case. AWS Lambda was chosen because of its simplicity and cost-effectiveness.
Lambda allows you to run code without provisioning or managing servers, with scaling and availability handled by the service. You pay only for the compute time you consume, and there is no charge when the code isn’t running.
To manage the serverless application development, iProperty.com.my uses the Serverless Framework (SLS) to develop and maintain their business logic on Lambda. The CI/CD pipeline deploys new updates to Lambda.
The Lambda functions are exposed to consumers via GraphQL APIs built on Amazon Elastic Kubernetes Service (Amazon EKS) with AWS Fargate.
The following diagram illustrates this workflow.
{kind=link}
The workflow includes the following steps:
Continuing from the ML training and deployment workflow, multiple ML models may be deployed on the SageMaker hosting infrastructure. The ML models are overlayed with relevant business logic (implemented on Lambda) before being served to consumers.
If there are any updates to the business logic, the data scientist updates the source code on the Serverless Framework and commits it to the Git repository.
The Git commit triggers the CI/CD pipeline to replace the Lambda function with the latest updates. This activity runs on the development account and is validated before being repeated on the production account.
Multiple Lambda functions are deployed with associated business logics that query the SageMaker inference endpoints.
For every API request made to the API layer, the GraphQL API processes the request and forwards the request to the corresponding Lambda function. An invoked function may query one or more SageMaker inference endpoints, and processes the business logic before providing a response to the requestor.
To evaluate the effectiveness of the ML models deployed, a dashboard that tracks the metric (such as clickthrough rate or open rate) for every ML model is created to visualize the performance of the ML models in production. These metrics served as our guiding light on how iProperty.com.my continues to reiterate and improve the ML models.
Business results
The iProperty.com.my team observed valuable results from the improved workflows.
“By implementing our data science workflows across SageMaker and our existing CI/CD tools, the automation and reduction in operational overhead enabled us to focus on ML model enhancement activities, accelerating our ML models’ time to market faster by 60%,” says Mohammad Alauddin, Head of Data Science and Engineering. “Not only that, with SageMaker Spot Instances, enabled with a simple switch, we were also able to reduce our data science infrastructure cost by 75%. Finally, by improving our ML model’s time to market, the ability to gather our consumer’s feedback was also accelerated, enabling us to tweak and improve our listing recommendations clickthrough rate by 250%.”
Summary and next steps
Although the team was deeply encouraged with the business results, there is still plenty of room to improve their consumer’s experience. They have plans to further enhance the ML model serving workflow, including A/B testing and model monitoring features.
To further reduce undifferentiated work, the team is also exploring SageMaker projects to simplify management and maintenance of their ML workflows, and SageMaker Pipelines to automate steps such as data loading, data transformation, training and tuning, and deployment at scale.
About PropertyGuru Group & iProperty.com.my
iProperty.com.my is headquartered in Kuala Lumpur, Malaysia and employs over 200 employees. iProperty.com.my is the market leading property portal, offering a search experience in both English and Bahasa Malaysia. iProperty.com.my also provides consumer solutions such as LoanCare – a home loan eligibility indicator, News & Lifestyle channel – content to enhance consumers’ property journey, events – to connect property seekers with agents and developers offline, and much more. The company is part of PropertyGuru Group, Southeast Asia’s leading property technology company1.
PropertyGuru is Southeast Asia’s leading property technology company. Founded in 2007, PropertyGuru has grown to become Southeast Asia’s #1 digital property marketplace with leading positions in Singapore, Vietnam, Malaysia and Thailand. The Company currently hosts more than 2.8 million monthly real estate listings and serves over 50 million monthly property seekers and over 50,000 active property agents across the five largest economies in Southeast Asia – Indonesia, Malaysia, Singapore, Thailand and Vietnam.
1 In terms of relative engagement market share based on SimilarWeb data.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Authors
Mohammad Alauddin is the Engineering Manager for Data at PropertyGuru Group. Over the last 15 years, he’s contributed to data analytics, data engineering, and machine learning projects in the Telco, Airline, and PropTech Digital Industry. He also speaks at Data & AI public events. In his spare time, he enjoys indoor activities with family, reading, and watching TV.
{kind=link}
Md Kamal Hossain is the Lead Data Scientist at PropertyGuru Group. He leads the Data Science Centre of Excellence (DS CoE) for ideation, design and productionizing end-to-end AI/ML solutions using cloud services. Kamal has particular interest in reinforcement learning and cognitive science. In his spare time, he likes reading and tries to keep up with his kids.
{kind=link}
Fabian Tan is a Principal Solutions Architect at Amazon Web Services. He has a strong passion for software development, databases, data analytics and machine learning. He works closely with the Malaysian developer community to help them bring their ideas to life.
{kind=link}
Read MoreAWS Machine Learning Blog