

{kind=link}
Amazon DocumentDB (with MongoDB compatibility) is a scalable, highly durable, and fully managed database service for operating mission-critical MongoDB workloads.
SQL is the de facto standard for data and analytics and one of the most popular languages among data engineers and data analysts. The Amazon DocumentDB JDBC driver provides a SQL interface that allows SQL-based tools to easily access JSON data stored in Amazon DocumentDB. With the Amazon DocumentDB JDBC driver, you can visualize JSON data with business intelligence (BI) tools like Tableau Desktop and run SQL queries on JSON data with developer tools like DbVisualizer.
This post helps you download, install, and configure the Amazon DocumentDB JDBC driver with Tableau Desktop and DbVisualizer.
Prerequisites
To implement this solution, you must have the following prerequisites:
An Amazon DocumentDB cluster. You can use an existing Amazon DocumentDB cluster or create a new one. This post assumes the default values for port (27017) and TLS (enabled) settings.
Tableau Desktop to visualize data (for this post, 2021.2.2).
DbVisualizer to query data (for this post, we use the DbVisualizer Free version 12.1.3).
If you’re connecting to your Amazon DocumentDB cluster from outside the cluster’s VPC, the JDBC driver uses an SSH tunnel to connect to it. An Amazon Elastic Compute Cloud (Amazon EC2) instance running in the same VPC as your Amazon DocumentDB cluster is used for SSH tunneling. There are two options to create an SSH tunnel for the JDBC driver:
Internally, using the JDBC driver SSH tunnel options.
Externally, using the SSH application. For more information on creating an external SSH tunnel, see Connecting to an Amazon DocumentDB Cluster from Outside an Amazon VPC.
For this post, we use the internal SSH tunnel option.
Solution Overview
The solution described in this post includes the following tasks:
Load sample data to your Amazon DocumentDB cluster.
Understanding schema discovery.
Connect and visualize data with Tableau Desktop.
Connect and query data with DbVisualizer.
Load sample data
First, import the sample datasets into the samples database in your Amazon DocumentDB cluster using the mongoimport tool.
Import cases.json into the cases collection:
Import moviedata.json into the movies collection. You need to use the –jsonArray option when importing this dataset:
For more information on finding your Amazon DocumentDB cluster endpoint, see Finding a Cluster’s Endpoints.
Understanding schema discovery
Before you use the JDBC driver, it’s important to understand how it generates table schemas from documents stored in Amazon DocumentDB. The following table compares terminology used by SQL databases with terminology used by Amazon DocumentDB.
SQL Database
Amazon DocumentDB
Table
Collection
Row
Document
Column
Field
The JDBC driver performs automatic schema discovery, mapping collections to tables, documents to rows, and fields to columns. This schema is used by the JDBC driver to provide a SQL interface for querying Amazon DocumentDB data.
When the JDBC driver first connects to an Amazon DocumentDB cluster, it samples the documents in each collection and creates schemas based on the following behavior.
Each collection is mapped to a base table with the same name as the collection. The following table summarizes the base table names used in this post, based on our sample datasets.
Amazon DocumentDB Collection
Base Table
cases
cases
movies
movies
For base tables, the primary key name is <base table name>__id and is mapped to the _id field. All other scalar fields (such as Boolean, Double, Date, and String) are mapped to a column in the base table.
As shown in the following sample document from the cases collection, all fields are scalar fields:
The following is the generated table schema.
{kind=link}
The following is an example of the cases table.
cases__id
Case_type
Cases
Difference
Date
Country_Region
611e800f0bed581b054edffd
Confirmed
0
0
3/9/2020
US
Object and array fields are mapped to separate virtual tables with a foreign key relationship back to the parent table. A parent table can be the base table or another virtual table in case of fields that have multiple levels of nesting. The name of the virtual table is generated by appending the name of the object or array field to the name of the parent table.
For virtual tables generated from object and array fields, the primary key name is the same as the parent table primary key name and is a foreign key back to the parent table. For virtual tables generated from array fields, additional indexes are generated to represent the index into the array at each level of the array.
As shown in the following sample document from the movies collection, there is a mix of scalar, object, and array fields, and some nesting:
We generate the following table schemas.
{kind=link}
The following is an example of the movies table.
movies__id
year
title
61267be60bed585a382b2ca1
2013
Rush
The following is an example of the movies_info table.
movies__id
release_date
rating
image_url
plot
rank
61267be60bed585a382b2ca1
2013-09-…
8.3
http:/…
A re-creation of…
2
The following is an example of the movies_info_directors table.
movies__id
info_directors_index_lvl_0
value
61267be60bed585a382b2ca1
0
Ron Howard
The following is an example of the movies_info_genres table.
movies__id
info_genres_index_lvl_0
value
61267be60bed585a382b2ca1
0
Action
61267be60bed585a382b2ca1
1
Biography
61267be60bed585a382b2ca1
2
Drama
61267be60bed585a382b2ca1
3
Sport
The following is an example of the movies_info_actors table.
movies__id
info_actors_index_lvl_0
value
61267be60bed585a382b2ca1
0
Daniel Bruhl
61267be60bed585a382b2ca1
1
Chris Hemsworth
61267be60bed585a382b2ca1
2
Olivia Wilde
The rest of this post uses the term table for the base table and generated virtual tables. For more information on automated schema discovery behavior, see Schema Discovery.
Download the JDBC driver files
Download the JDBC driver .jar and .taco files. Note the location of the downloaded files as you will need it when configuring Tableau Desktop and DbVisualizer.
Visualize data with Tableau Desktop
With the JDBC driver, you can visualize data with BI tools. In this section, I configure and use Tableau Desktop to visualize the sample datasets.
Install the JDBC driver and connector
Copy the JDBC driver .jar file to the following directory according to your operating system. For more information, see Other Databases (JDBC).
Windows C:Program FilesTableauDrivers
Mac ~/Library/Tableau/Drivers
Copy the Amazon DocumentDB Tableau connector .taco file to the following directory according to your operating system. For more information, see Use a connector built with Tableau Connector SDK.
Windows C:Users[user]DocumentsMy Tableau RepositoryConnectors
Mac ~/Documents/My Tableau Repository/Connectors
Configure Tableau Desktop
When you launch Tableau Desktop, you can see the Start page with the Connect pane on the left.
In the Connect pane, under To a Server, choose More….
Choose Amazon DocumentDB by AWS from the list of installed connectors.
On the General tab provide the following information:
For Hostname, enter your Amazon DocumentDB cluster endpoint.
For Port, enter 27017.
For Database, enter samples.
For Username, enter your Amazon DocumentDB cluster master user name.
For Password, enter your Amazon DocumentDB cluster master password.
Select Enable TLS.
Select Allow Invalid Hostnames.
{kind=link}
This indicates that invalid host names for the TLS certificate are allowed and is useful when using an internal SSH tunnel to connect to an Amazon DocumentDB cluster.
{kind=link}
On the Advanced tab provide the following information.
Select Enable SSH Tunnel.
For SSH User, enter your SSH tunnel EC2 instance user name.
For more information, see Get information about your instance.
For SSH Hostname, enter your SSH tunnel EC2 instance host name.
For SSH Private Key File, enter the path to your SSH tunnel EC2 instance private key.
For more information, see Locate the private key.
Deselect SSH Strict Host Key Check.
Select Enable Retry Reads.
For Read Preference, choose Primary.
{kind=link}
For more information on connection options, see Connection String Syntax and Options.
Choose Sign In to connect to your Amazon DocumentDB cluster.
Visualize the data
After you connect to your Amazon DocumentDB cluster, you see the data source page. This page shows the connection (the Amazon DocumentDB cluster endpoint) in the left pane and at the top of the canvas.
The JDBC driver performs automatic schema discovery to generate a SQL to Amazon DocumentDB schema mapping upon connection to the database. The Schema drop-down menu contains samples, corresponding to the database name.
{kind=link}
Choose the samples schema to see the tables created by the JDBC driver.
Drag the cases table to the top half of the canvas.
{kind=link}
The canvas updates to show the cases table with a data grid below it.
{kind=link}
You can now review the first 1,000 rows from the cases table.
{kind=link}
At the bottom of the Tableau Desktop window, choose the Sheet 1 tab to view a new worksheet.
A worksheet is where you build views of your data by dragging and dropping fields onto the Columns and Rows shelves.
{kind=link}
For this post, we build a view that shows the total number of cases by country ordered by the total case count.
Drag the Country Region field to the Columns shelf.
The view is updated with the countries in the sample dataset.
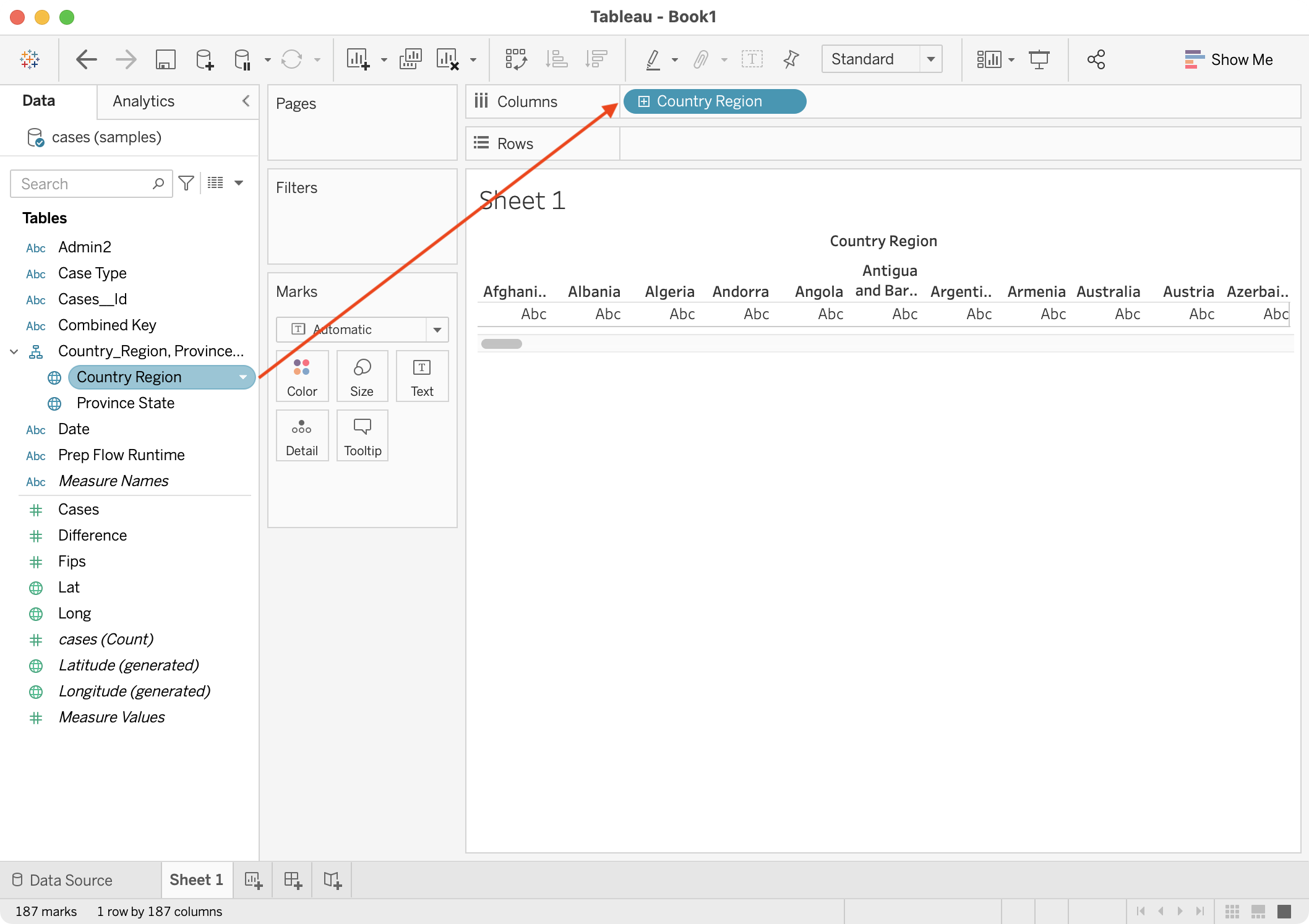{kind=link}
Drag the Cases field to the Rows shelf.
The view is updated with the total number of cases in each country.
{kind=link}
Choose the sort icon on the Cases axis.
The view is updated to order the countries by the total case count.
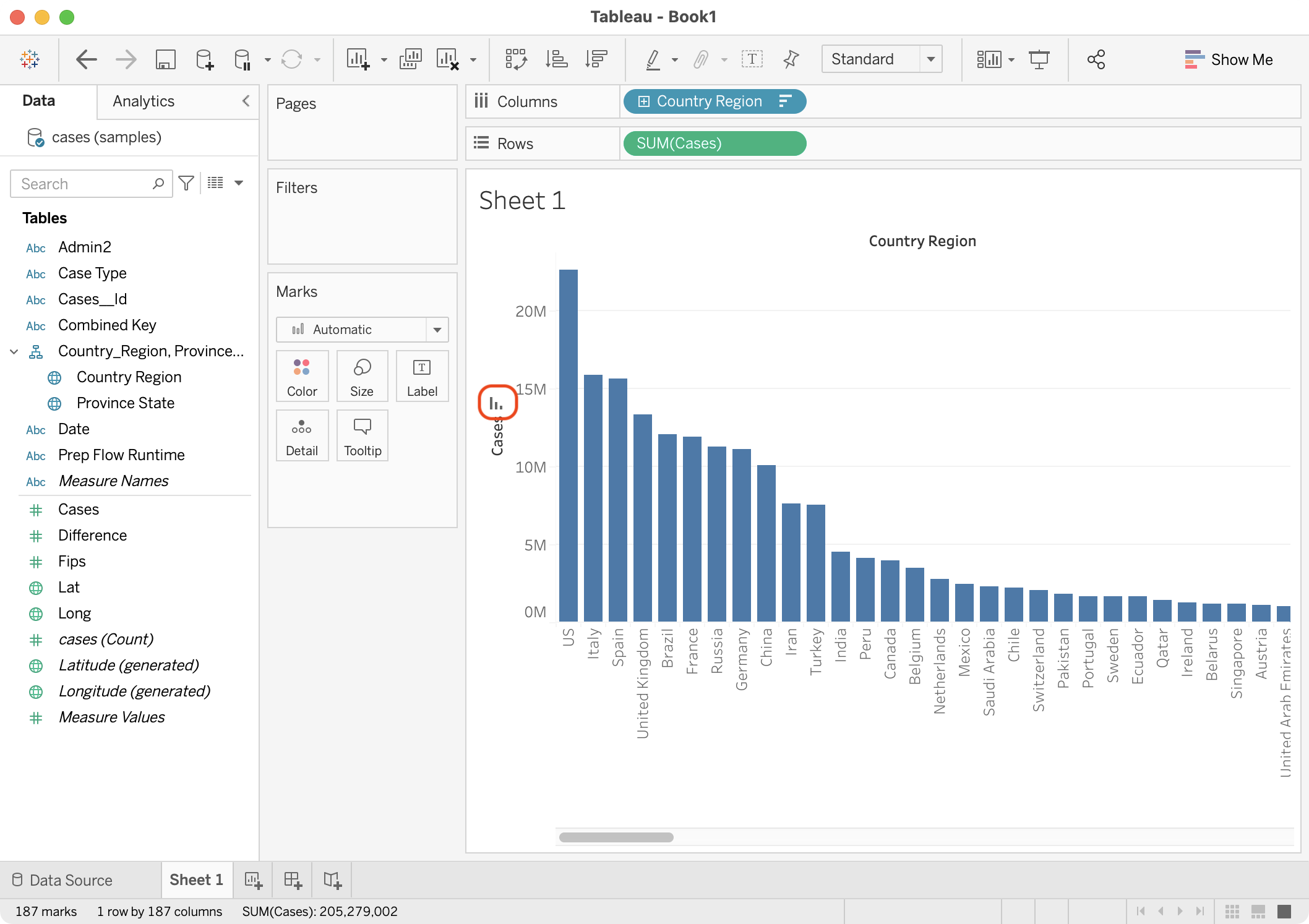{kind=link}
To see some other visualizations you can perform, choose Show Me. For example, you can choose the packed bubbles visualization.
{kind=link}
Choose Show Me again to hide the list of visualizations.
{kind=link}
Tableau Desktop can detect many kinds of location data. In this case, Tableau Desktop recognizes the Country Region values in the sample dataset and generates latitude and longitude values based on them. We can use the generated location information to visualize the sample dataset.
Choose Show Me and choose maps.
Choose Show Me again to hide the list of visualizations.
{kind=link}
{kind=link}
Next, we visualize data from multiple movies tables.
At the bottom of the Tableau Desktop window, choose the Data Source tab.
In the top half of the canvas, on the cases drop-down menu, choose Remove.
Drag the movies and movies_info_actors tables to the top half of the canvas.
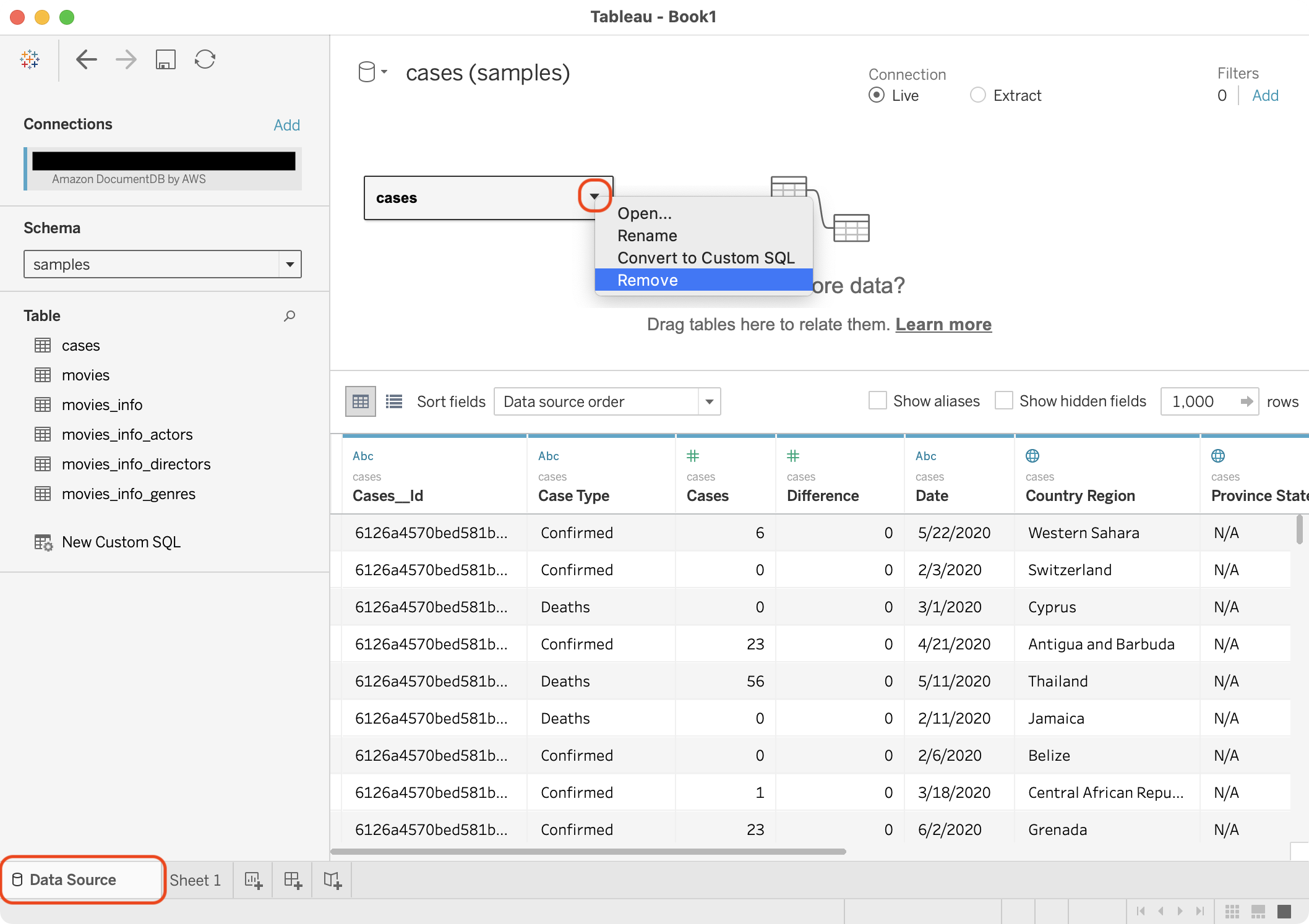{kind=link}
{kind=link}
An Edit Relationship window appears asking you to confirm the relationship between the tables. Tableau Desktop automatically detects and uses the Movies_Id field in both tables, so you can close this window. For more information, see Relate Your Data.
{kind=link}
At the bottom of the Tableau Desktop window, choose the New Worksheet tab to create a new worksheet.
{kind=link}
We build a view that shows the total number of movies each actor has starred in ordered by the number of movies they have starred in.
Drag the Value field of the movies_info_actors table to the Columns shelf.
The view is updated with the actor names in the sample dataset.
{kind=link}
Every table in a data source has a Count field that is automatically generated and calculated by Tableau.
Drag the generated movies (Count) field of the movies table to the Rows shelf.
The view is updated with the total number of movies each actor has starred in. For more information, see the Fields that Tableau automatically creates.
{kind=link}
Choose the sort icon on the Count of movies axis.
The view is updated to order the actors by the number of movies they starred in.
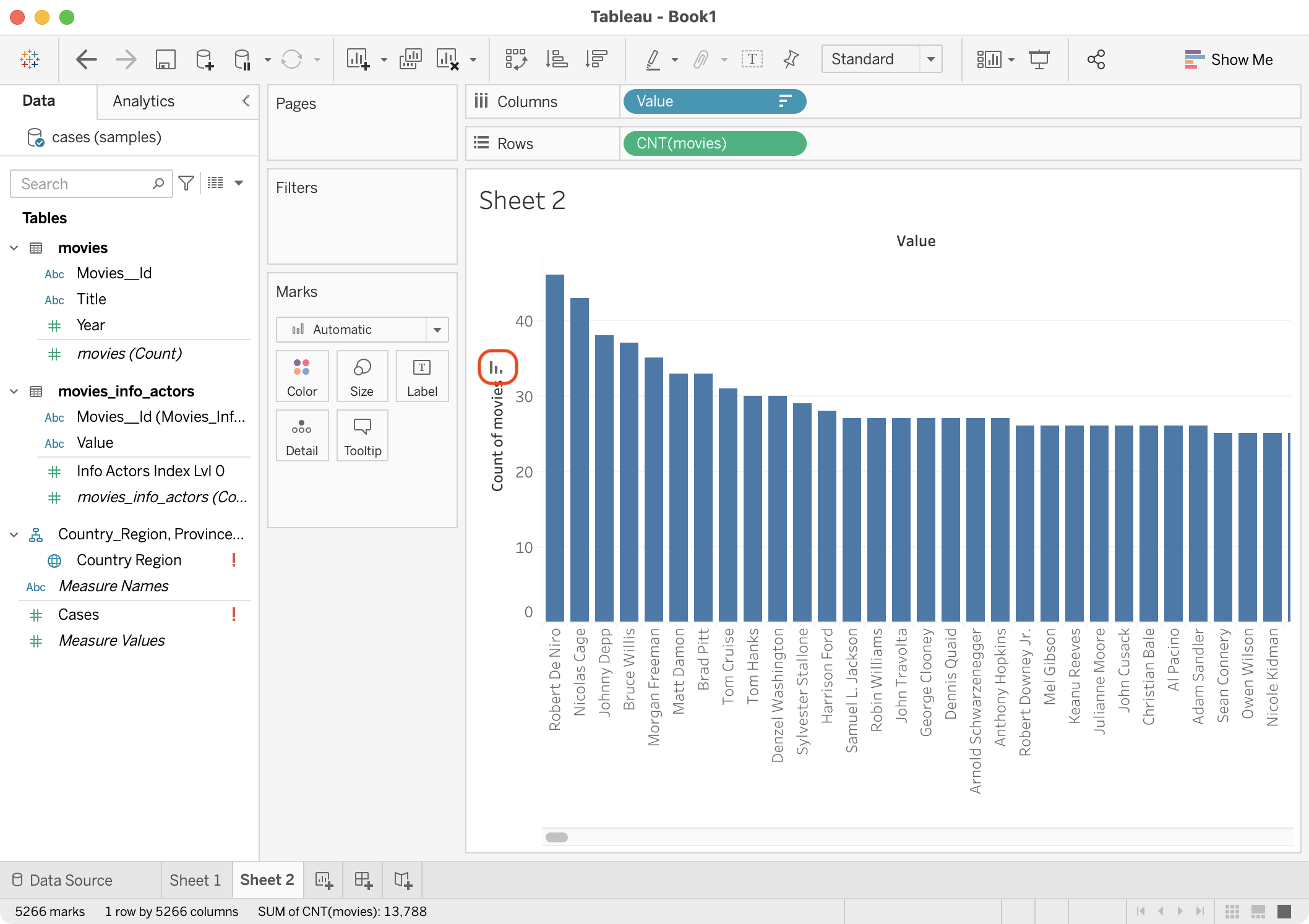{kind=link}
Run SQL queries with DbVisualizer
In addition to visualizing data with BI tools, the JDBC driver allows to you run SQL queries on JSON data. In this section, you configure and use DbVisualizer to run SQL queries on the sample datasets.
Configure DbVisualizer
Launch DbVisualizer, the complete the following steps:
On the Tools menu, choose Driver Manager….
Choose the Create a new driver icon.
In the Driver Settings section, provide the following information:
For Name, enter Amazon DocumentDB.
For URL Format, enter jdbc:documentdb://<host>[:port]/<database>[?option=value[&option=value[…]]]
For more information on connection options, see Connection String Syntax and Options.
In the Driver jar Files section, choose the Open file icon.
In the Open window, navigate to the location of the JDBC driver .jar file.
Choose the file and then choose Open.
In the Driver Settings section of the Driver Manager window, confirm that the Driver Class is software.amazon.documentdb.jdbc.DocumentDbDriver.
Close the Driver Manager window.
{kind=link}
{kind=link}
{kind=link}
Next, you create a connection to your Amazon DocumentDB cluster.
On the Database menu, choose Create Database Connection.
If asked to use the Connection Wizard, choose No Wizard.
On the Connection tab, provide the following information:
For Name, enter Samples.
For Driver (JDBC), choose Amazon DocumentDB.
For Database URL, enter jdbc:documentdb://<Amazon DocumentDB cluster endpoint>:27017/samples?sshUser=<your SSH tunnel EC2 instance user name>&sshHost=<your SSH tunnel EC2 instance host name>&sshPrivateKeyFile=<path to your SSH tunnel EC2 instance private key>&tlsAllowInvalidHostnames=true&sshStrictHostKeyChecking=false&readPreference=secondaryPreferred&retryReads=true
For Database Userid, enter your Amazon DocumentDB cluster master user name.
For Database Password, enter your Amazon DocumentDB cluster master password.
{kind=link}
{kind=link}
Select Connect to connect to your Amazon DocumentDB cluster.
{kind=link}
The samples schema in the navigation corresponds to the database name. You can expand the samples schema to see the tables created by the JDBC driver.
Run queries
To run queries on your data, complete the following steps:
Choose the cases table and the Data tab to display the first 1,000 rows from the cases table.
In the main toolbar, choose the Create a new SQL Commander tab icon to run SQL queries against the cases data.
On the Untitled SQL Commander tab, confirm that the Samples database connection is being used and enter the following SQL query in the SQL editor:
{kind=link}
{kind=link}
Choose the Execute icon get a list of countries ordered by the total case count.
Run the following query that joins data from the movies, movies_info, and movies_info_actors tables to return a list of the all movies that Robert De Niro has starred in, ordered by rating:
{kind=link}
{kind=link}
For more information on SQL query support, see SQL Support and Limitations.
Clean up
To clean up resources created during the exercises in this post, remove the following:
The Amazon DocumentDB cluster
The EC2 instance used for SSH tunneling
Summary
This post introduced you to the JDBC driver and walked you through downloading, installing, configuring, and using it to visualize data in Tableau Desktop and run SQL queries in DbVisualizer.
For more information about the JDBC driver see Connect Using Amazon DocumentDB JDBC Driver and the Amazon DocumentDB JDBC Driver documentation on GitHub.
If you have any questions or comments about this post, please use the comments section. If you have any features requests for Amazon DocumentDB, email us at [email protected].
About the Author
Douglas Bonser is a Senior DocumentDB Specialist Solutions Architect based out of the Dallas/Ft. Worth area in Texas. He enjoys helping customers solve problems and modernize their applications using NoSQL database technology. Prior to joining AWS he has worked extensively with NoSQL and relational database technologies for over 30 years.
{kind=link}
Read MoreAWS Database Blog