

{kind=link}
One of the main challenges in a machine learning (ML) project implementation is the variety and high number of development artifacts and tools used. This includes code in notebooks, modules for data processing and transformation, environment configuration, inference pipeline, and orchestration code. In production workloads, the ML model created within your development framework is almost never the end of the work, but is a part of a larger application or workflow.
Another challenge is the varied nature of ML development activities performed by different user roles. For example, the DevOps engineer develops infrastructure components, such as CI/CD automation, builds production inference pipelines, and configures security and networking. The data engineer is typically focused on data processing and transformation workflows. The data scientist or ML engineer delivers ML models and model building, training, and validation pipelines.
These challenges call for an architecture and framework that facilitate separation of concerns by allowing each development role to work on their own part of the system, and hide the complexity of integration, security, and environment configuration.
This post illustrates how to introduce a modular component-based architecture in your ML application by implementing reusable, self-contained, and consistent components with Amazon SageMaker.
Solution overview
As an example of an ML workflow that spans several development domains, the proposed solution implements a use case of an automated pipeline for data transformation, feature extraction, and ingestion into Amazon SageMaker Feature Store.
On a high level, the workflow comprises the following functional steps:
An upstream data ingestion component uploads data objects to an Amazon Simple Storage Service (Amazon S3) bucket.
The data upload event launches a data processing and transformation process.
The data transformation process extracts, processes, and transforms features, and ingests them into a designated feature group in Feature Store.
{kind=link}
Terminology
This section introduces the following important concepts and definitions.
ML component
An ML component is a construction unit that contains all the required resources, configuration, and workflows to perform a specific ML task. For example, the proposed data transformation and ingestion pipeline can be delivered as an ML component. ML components have a better integration capability to help you to implement reproducible, governed, and secure ML applications. An ML component can encapsulate all the boilerplate code required to properly set up data access permissions, security keys, tagging, naming, and logging requirements for all resources.
A process of implementing an ML component assumes that a dedicated DevOps or MLOps team performs the design, building, testing, and distribution of components. The recipients of ML components are data scientists, data engineers, and ML engineers.
This separation of development responsibilities brings higher agility, a faster time to market, and less manual heavy lifting, and results in a higher quality and consistency of your ML workflows.
Amazon SageMaker project
SageMaker facilitates the development and distribution of ML components with SageMaker projects.
A SageMaker project is a self-sufficient collection of resources, which can be instantiated and used by the entitled users. A project contains all the resources, artifacts, source code, orchestration, and permissions that are needed to perform a designated ML task or workflow. For example, SageMaker provides MLOps project templates to automate setup and implementation of MLOps for your applications.
You can implement a custom SageMaker project template to deliver a packaged ML workflow, which can be distributed and provisioned via an Amazon SageMaker Studio IDE.
When you implement custom reusable components with SageMaker projects, you can separate the development, testing, and distribution process for ML components from their employment, and follow MLOps best practices.
Product portfolio
A project works together with two other AWS services, AWS Service Catalog and AWS CloudFormation, to provide an end-to-end, user-friendly integration in your SageMaker environment and Studio. You can combine multiple projects in a portfolio. A SageMaker project is called product in the portfolio scope. A product portfolio is delivered via AWS Service Catalog into Studio. You can control who can view and provision specific products by associating user roles with a designated portfolio.
Solution architecture
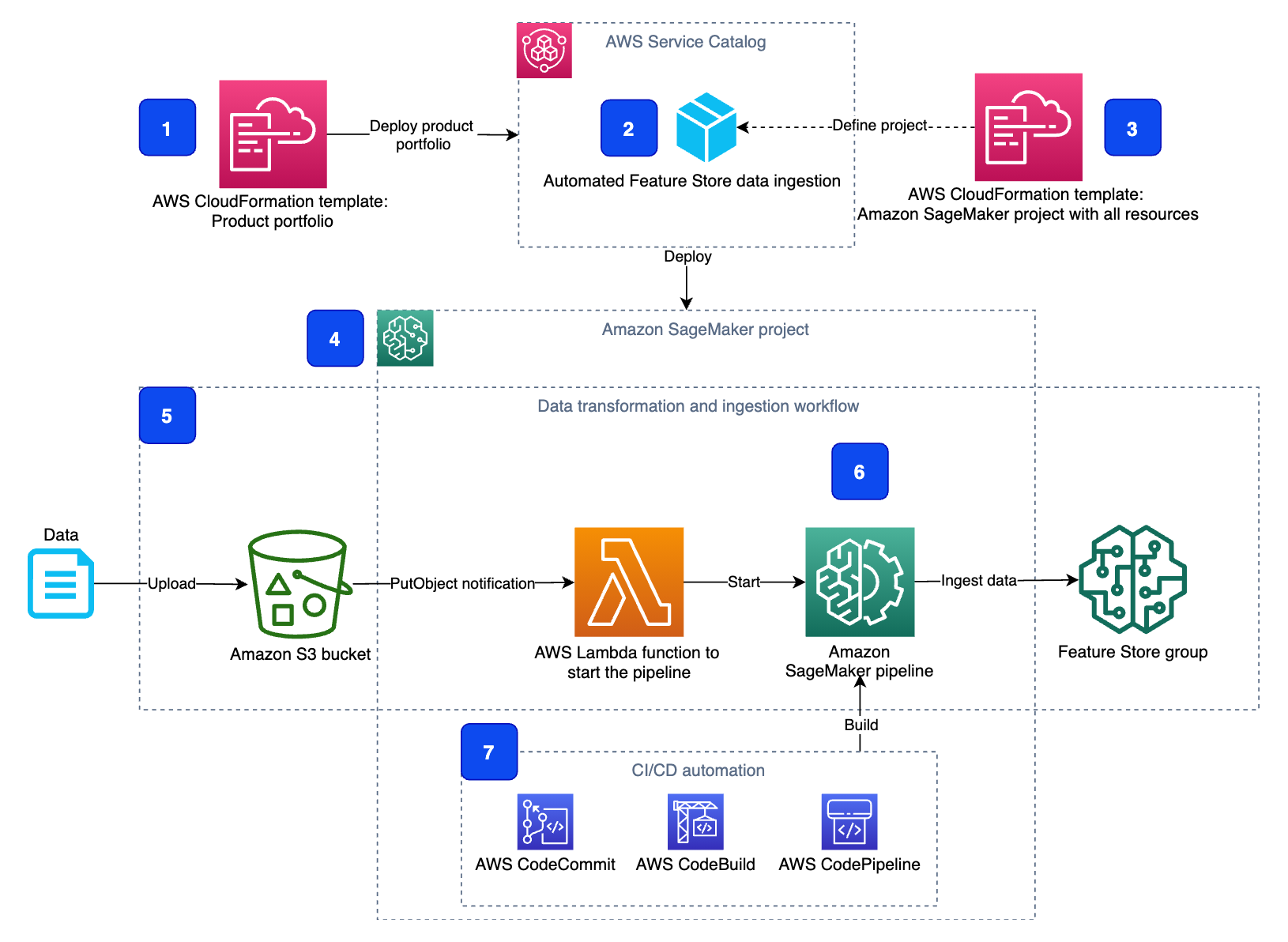
The detailed component architecture of the solution is presented in the following diagram.
{kind=link}
A product portfolio (1) defines the automated Feature Store data ingestion product (2) together with the associated user roles that are allowed to use the portfolio and the containing products. CloudFormation templates define both the product portfolio (1) and the product (2). A CloudFormation template (3) contains all the resources, source code, configuration, and permissions that are needed to provision the product in your SageMaker environment.
When AWS CloudFormation deploys the product, it creates a new SageMaker project (4).
The SageMaker project implements the feature ingestion workflow (5). The workflow contains an AWS Lambda function, which is launched by an Amazon EventBridge rule each time new objects are uploaded into a monitored S3 bucket. The Lambda function starts a SageMaker pipeline (6), which is defined and provisioned as a part of the SageMaker project. The pipeline implements data transformation and ingestion in Feature Store.
The project also provisions CI/CD automation (7) with an AWS CodeCommit repository with source code, AWS CodeBuild with a pipeline build script, and AWS CodePipeline to orchestrate the build and deployment of the SageMaker pipeline (6).
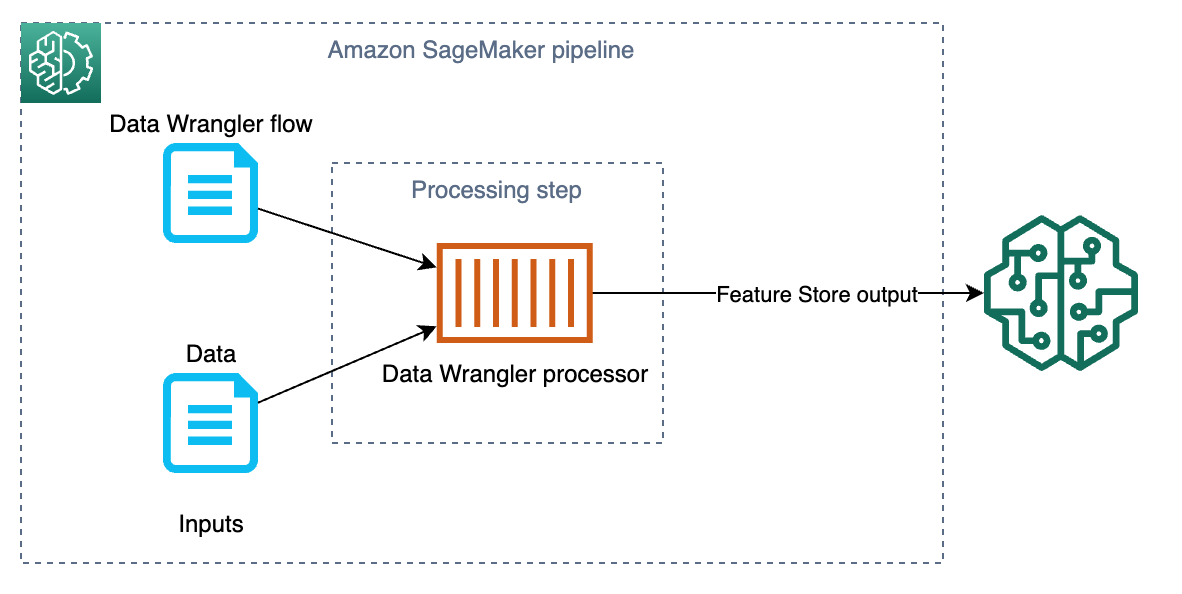
ML pipeline
This solution implements an ML pipeline by using Amazon SageMaker Pipelines, an ML workflow creation and orchestration framework. The pipeline contains a single step with an Amazon SageMaker Data Wrangler processor for data transformation and ingestion into a feature group in Feature Store. The following diagram shows a data processing pipeline implemented by this solution.
{kind=link}
Refer to Build, tune, and deploy an end-to-end churn prediction model using Amazon SageMaker Pipelines for an example of how to build and use a SageMaker pipeline.
The rest of this post walks you through the implementation of a custom SageMaker project. We discuss how to do the following:
Create a project with your resources
Understand the project lifecycle
View project resources
Create a Studio domain and deploy a product portfolio
Work with the project and run a data transformation and ingestion pipeline
The GitHub repository provides the full source code for the end-to-end solution. You can use this code as a starting point for your own custom ML components to deploy using this same reference architecture.
Author a SageMaker project template
To get started with a custom SageMaker project, you need the following resources, artifacts, and AWS Identity and Access Management (IAM) roles and permissions:
A CloudFormation template that defines an AWS Service Catalog portfolio.
A CloudFormation template that defines a SageMaker project.
IAM roles and permissions needed to run your project components and perform the project’s tasks and workflows.
If your project contains any source code delivered as a part of the project, this code must be also delivered. The solution refers to this source code as the seed code.
Files in this solution
This solution contains all the source code needed to create your custom SageMaker project. The structure of the code repository is as follows:
cfn-templates folder: This folder contains the following:
project-s3-fs-ingestion.yaml – A CloudFormation template with the SageMaker project
sm-project-sc-portfolio.yaml – A CloudFormation template with the product portfolio and managed policies with permissions needed to deploy the product
project-seed-code/s3-fs-ingestion folder – Contains the project seed code, including the SageMaker pipeline definition code, build scripts for the CI/CD CodeBuild project, and source code for the Lambda function
notebooks folder – Contains the SageMaker notebooks to experiment with the project
The following sections describe each part of the project authoring process and give examples of the source code.
AWS Service Catalog portfolio
An AWS Service Catalog portfolio is delivered as a CloudFormation template, which defines the following resources:
Portfolio definition.
Product definition.
Product to portfolio association for each product.
Portfolio to IAM principle association. This defines which IAM principles are allowed to deploy portfolio products.
Product launch role constraint. This defines which IAM role AWS CloudFormation assumes when a user provisions the template.
To make your project template available in Studio, you must add the following tag to the product:
Refer to Create Custom Project Templates for more details on custom project templates.
This solution contains an example of an AWS Service Catalog portfolio that contains a single product.
Product CloudFormation template
A CloudFormation template defines the product. The product’s template is self-sufficient and contains all the resources, permissions, and artifacts that are needed to deliver the product’s functionality.
For the product to work with SageMaker projects, you must add the following parameters to your product template:
This solution contains a product template that creates several resources.
For the data transformation and ingestion pipeline, the template creates the following:
A SageMaker pipeline definition source code.
A Lambda function to start the SageMaker pipeline whenever a new object is uploaded to the monitored S3 bucket.
An IAM execution role for the Lambda function.
An S3 bucket to keep an AWS CloudTrail log. You need a CloudTrail log to enable EventBridge notification for object put events on the monitored bucket. You use the CloudTrail-based notification instead of Amazon S3 notifications because you must not overwrite an existing Amazon S3 notification on the monitored bucket.
A CloudTrail log configured to capture WriteOnly events on S3 objects under a specified S3 prefix.
An EventBridge rule to launch the Lambda function whenever a new object is uploaded to the monitored S3 bucket. The EventBridge rule pattern monitors the events PutObject and CompleteMultipartUpload.
For CI/CD automation, the template creates the following:
An S3 bucket to store CodePipeline artifacts
A CodeCommit repository with the SageMaker pipeline definition
An EventBridge rule to launch CodePipeline when the CodeCommit repository is updated
A CodeBuild project to build the SageMaker pipeline
A CodePipeline pipeline to orchestrate the build of the SageMaker pipeline
IAM roles and permissions
To launch and use a SageMaker project, you need two IAM roles:
An IAM role to launch a product from AWS Service Catalog – This rule is assumed by AWS Service Catalog and contains permission specifically needed to deploy resources using CloudFormation templates. The AWS Service Catalog-based approach allows data scientists and ML engineers to provision custom ML components and workflows centrally without requiring each ML user to have high-profile permissions policies or going via a manual and non-reproducible individual deployment process.
An IAM role to use resources created by a SageMaker project – These resources include a CodePipeline pipeline, a SageMaker pipeline, and an EventBridge rule. The project’s CloudFormation template explicitly specifies which resource uses which role.
When you enable SageMaker projects for Studio users, the provisioning process creates two IAM roles in your AWS account: AmazonSageMakerServiceCatalogProductsLaunchRole and AmazonSageMakerServiceCatalogProductsUseRole. The SageMaker-provided project templates use these roles to deploy and operate the created resources. You can use these roles for your custom SageMaker projects, or you can create your own roles with a specific set of IAM permissions suited to your requirements. Make sure these roles are given all necessary permissions, specifically S3 bucket access, to perform their tasks.
Refer to AWS Managed Policies for SageMaker projects and JumpStart for more details on the default roles.
If you create and assign any IAM roles to resources created by the project provisioning via AWS Service Catalog and AWS CloudFormation, the role AmazonSageMakerServiceCatalogProductsLaunchRole must have iam:PassRole permission for a role you pass to a resource. For example, this solution creates an IAM execution role for the Lambda function. The managed policy for AmazonSageMakerServiceCatalogProductsLaunchRole contains the corresponding permission statement:
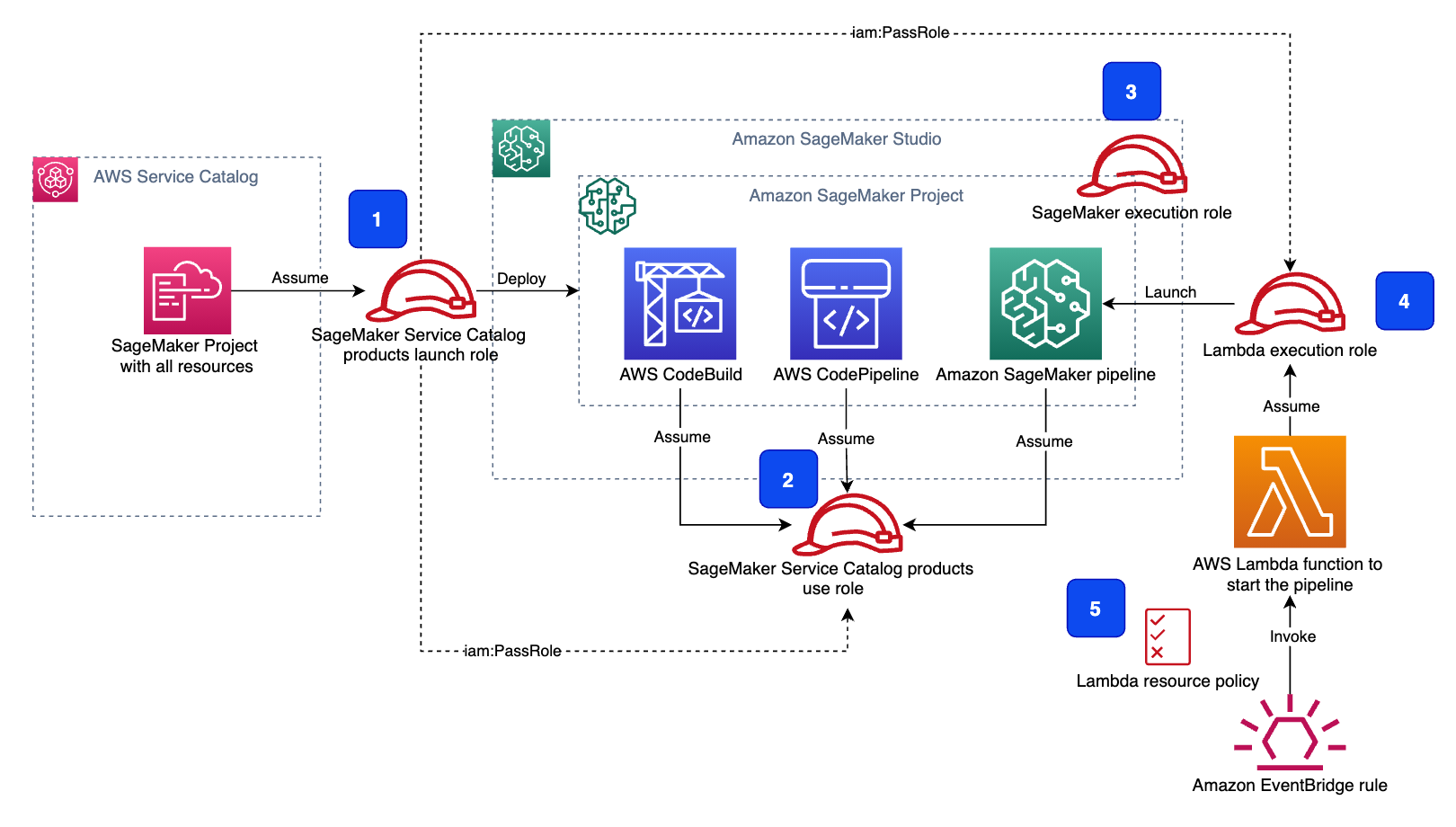
The following diagram shows all the IAM roles involved and which service or resource assumes which role.
{kind=link}
The architecture contains the following components:
The SageMaker Service Catalog products launch role. This role calls the iam:PassRole API for the SageMaker Service Catalog products use role (2) and the Lambda execution role (4).
The SageMaker Service Catalog products use role. Project resources assume this role to perform their tasks.
The SageMaker execution role. Studio notebooks use this role to access all resources, including S3 buckets.
The Lambda execution role. The Lambda function assumes this role.
The Lambda function resource policy allows EventBridge to invoke the function.
Refer to SageMaker Studio Permissions Required to Use Projects for more details on the Studio permission setup for projects.
Project seed code
If your custom SageMaker project uses CI/CD workflow automation or contains any source code-based resources, you can deliver the seed code as a CodeCommit or third-party Git repository such as GitHub and Bitbucket. The project user owns the code and can customize it to implement their requirements.
This solution delivers the seed code, which contains a SageMaker pipeline definition. The project also creates a CI/CD workflow to build the SageMaker pipeline. Any commit to the source code repository launches the CodePipeline pipeline.
Project lifecycle
A project passes through distinct lifecycle stages: you create a project, use it and its resources, and delete the project when you don’t need it anymore. Studio UX integrates end-to-end SageMaker projects including project resources, data lineage, and lifecycle control.
Create a project
You can provision a SageMaker project directly in your Studio IDE or via the SageMaker API.
To create a new SageMaker project in Studio, complete the following steps:
On the SageMaker resources page, choose Projects on the drop-down menu.
Choose Create project.
Choose Organization templates.
Choose the template for the project you want to provision.
Enter a name and optional description for your project.
Under Project template parameters, provide your project-specific parameters.
{kind=link}
{kind=link}
{kind=link}
You can also use the Python SDK to create a project programmatically, as shown in this code snippet from the 01-feature-store-ingest-pipeline notebook:
Each project is provisioned via an AWS Service Catalog and AWS CloudFormation process. Because you have the corresponding IAM access policy, for example AWSCloudFormationReadOnlyAccess, you can observe the project deployment on the AWS CloudFormation console. As shown in the following screenshot, you can browse stack info, events, resources, outputs, parameters, and the template.
{kind=link}
View project resources
After you provision the project, you can browse SageMaker-specific project resources in the Studio IDE.
{kind=link}
You can also see all the resources created by the project deployment process on the AWS CloudFormation console.
Any resource created by the project is automatically tagged with two tags: sagemaker:project-name and sagemaker:project-id, allowing for data and resource lineage.
{kind=link}
You can add your own tags to project resources, for example, to fulfill your specific resource tagging and naming requirements.
Delete project
If you don’t need the provisioned project any more, to stop incurring charges, you must delete it to clean up the resources created by the project.
At the time of writing this post, you must use the SageMaker API to delete a project. A sample Python code looks like the following:
Deleting the project also initiates the deletion of the CloudFormation stack with the project template.
A project can create other resources, such as objects in S3 buckets, ML models, feature groups, inference endpoints, or CloudFormation stacks. These resources may not be removed upon project deletion. Refer to the specific project documentation for how to perform a full cleanup.
This solution provides a Studio notebook to delete all the resources created by the project.
Deploy the solution
To deploy the solution, you must have administrator (or power user) permissions to package the CloudFormation templates, upload the templates in your S3 bucket, and run the deployment commands.
To start working with the solution’s notebooks, provision a project, and run a data transformation and ingestion pipeline, you must complete the following deployment steps from the solution’s GitHub README file:
Clone the solution’s GitHub repo to your local development environment.
Create a Studio domain (instructions in the README file).
Deploy the SageMaker project portfolio (instructions in the README file).
Add custom permissions to the AWS Service Catalog launch and SageMaker execution IAM roles (instructions in the README file).
Start Studio and clone the GitHub repository into your SageMaker environment (instructions in the README file).
Solution walkthrough
The delivered notebooks take you through the following solution steps:
Setup:
Set up the working environment, create an S3 bucket for data upload, download and explore the test dataset
Optionally, create a Data Wrangler flow for data transformation and feature ingestion
Create a feature group in Feature Store where features are kept
Query the data from the feature group
Feature Store ingestion pipeline:
Provision a SageMaker project with a data pipeline
Explore the project resources
Test the data pipeline by uploading new data to the monitored S3 bucket
Run the data pipeline on demand via Python SDK
Query the data from the feature group
Clean up:
Delete the project and project’s resources
Delete the feature group
Delete project-provisioned S3 buckets and S3 objects
Clean up
To avoid charges, you must remove all project-provisioned and generated resources from your AWS account.
Follow the instructions in the solution’s README file.
Call to action
In this post, you learned how to create ML components for your modular architecture using SageMaker projects. SageMaker projects offer a convenient and AWS-native method to package and deliver reusable units to implement ML workflows. Integrating SageMaker projects with SageMaker Pipelines and CI/CD CodePipeline automation gives you power tools to follow MLOps best practices and increase the speed and quality of your development work.
Your ML workflows and pipelines may benefit from being encapsulated into a reusable and parametrizable component. Now you can implement this component using the described approach with SageMaker projects.
Additional references
For more hands-on examples of using SageMaker projects and pipelines for various use cases, see the following resources:
Automate a centralized deployment of Amazon SageMaker Studio with AWS Service Catalog
Create Amazon SageMaker projects with image building CI/CD pipelines
Create Amazon SageMaker projects using third-party source control and Jenkins
GitHub public repository for Feature Store workshop
GitHub public repository for Amazon SageMaker drift detection
Schedule an Amazon SageMaker Data Wrangler flow to process new data periodically using AWS Lambda
Build, tune, and deploy and end-to-end churn prediction model using Amazon SageMaker Pipelines
About the Author
Yevgeniy Ilyin is a Solutions Architect at AWS. He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.
{kind=link}
Read MoreAWS Machine Learning Blog