

{kind=link}
The last few years have seen rapid development in the field of natural language processing (NLP). Although hardware has improved, such as with the latest generation of accelerators from NVIDIA and Amazon, advanced machine learning (ML) practitioners still regularly encounter issues deploying their large language models. Today, we announce new capabilities in Amazon SageMaker that can help: you can configure the maximum Amazon EBS volume size and timeout quotas to facilitate large model inference. Coupled with model parallel inference techniques, you can now use the fully managed model deployment and management capabilities of SageMaker when working with large models with billions of parameters.
In this post, we demonstrate these new SageMaker capabilities by deploying a large, pre-trained NLP model from Hugging Face across multiple GPUs. In particular, we use the Deep Java Library (DJL) serving and tensor parallelism techniques from DeepSpeed to achieve under 0.1 second latency in a text generation use case with 6 billion parameter GPT-J. Complete example on our GitHub repository coming soon.
Large language models and the increasing necessity of model parallel inference
Language models have recently exploded in both size and popularity. In 2018, BERT-large entered the scene and, with its 340 million parameters and novel transformer architecture, set the standard on NLP task accuracy. Within just a few years, state-of-the-art NLP model size has grown by more than 500 times, with models such as OpenAI’s 175 billion parameter GPT-3 and similarly sized open-source Bloom 176 B raising the bar on NLP accuracy. This increase in the number of parameters is driven by the simple and empirically-demonstrated positive relationship between model size and accuracy: more is better. With easy access from model zoos such as Hugging Face and improved accuracy in NLP tasks such as classification and text generation, practitioners are increasingly reaching for these large models. However, deploying them can be a challenge.
Large language models can be difficult to host for low-latency inference use cases because of their size. Typically, ML practitioners simply host a model (or even multiple models) within the memory of a single accelerator device that handles inference end to end on its own. However, large language models can be too big to fit within the memory of a single accelerator, so this paradigm can’t work. For example, open-source GPT-NeoX with 20 billion parameters can require more than 80 GB of accelerator memory, which is more than triple what is available on an NVIDIA A10G, a popular GPU for inference. Practitioners have a few options to work against this accelerator memory constraint. A simple but slow approach is to use CPU memory and stream model parameters sequentially to the accelerator. However, this introduces a communication bottleneck between the CPU and GPU, which can add seconds to inference latency and is therefore unsuitable for many use cases that require fast responses. Another approach is to optimize or compress the model so that it can fit on a single device. Practitioners must implement complex techniques such as quantization, pruning, distillation, and others to reduce the memory requirements. This approach requires a lot of time and expertise and can also reduce the accuracy and generalization of a model, which can also be a non-starter for many use cases.
A third option to use model parallelism. With model parallelism, the parameters and layers of a model are partitioned and then spread across multiple accelerators. This approach allows practitioners to take advantage of both the memory and processing power of multiple accelerators at once and can deliver low-latency inference without impacting the accuracy of the model. Model parallelism is already a popular technique in training (see Introduction to Model Parallelism) and is increasingly becoming used in inference as practitioners require low-latency responses from large models.
There are two general types of model parallelism: pipeline parallelism and tensor parallelism. Pipeline parallelism splits a model between layers, so that any given layer is contained within the memory of a single GPU. In contrast, tensor parallelism splits layers such that a model layer is spread out across multiple GPUs. Both of these model parallel techniques are used in training (often together), but tensor parallelism can be a better choice for inference because batch size is often one with inference. When batch size is one, only tensor parallelism can take advantage of multiple GPUs at once when processing the forward pass to improve latency.
In this post, we use DeepSpeed to partition the model using tensor parallelism techniques. DeepSpeed Inference supports large Transformer-based models with billions of parameters. It allows you to efficiently serve large models by adapting to the best parallelism strategies for multi-GPU inference, accounting for both inference latency and cost. For more information, refer to DeepSpeed: Accelerating large-scale model inference and training via system optimizations and compression and this DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale.
Solution overview
The Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. The DJL is built with native Java concepts on top of existing deep learning frameworks. The DJL is designed to be deep learning engine agonistic. You can switch engines at any point. The DJL also provides automatic CPU/GPU choice based on hardware configuration.
Although the DJL is designed originally for Java developers to get start with ML, DJLServing is a high-performance universal model serving solution powered by the DJL that is programming language agnostic. It can serve the commonly seen model types, such the PyTorch TorchScript model, TensorFlow SavedModel bundle, Apache MXNet model, ONNX model, TensorRT model, and Python script model. DJLServing supports dynamic batching and worker auto scaling to increase throughput. You can load different versions of a model on a single endpoint. You can also serve models from different ML frameworks at the same time. What’s more, DJLServing natively supports multi-GPU by setting up MPI configurations and socket connections for inference. This frees the heavy lifting of setting up a multi-GPU environment.
Our proposed solution uses the newly announced SageMaker capabilities, DJLServing and DeepSpeed Inference, for large model inference. As of this writing, all Transformer-based models are supported. This solution is intended for parallel model inference using a single model on a single instance.
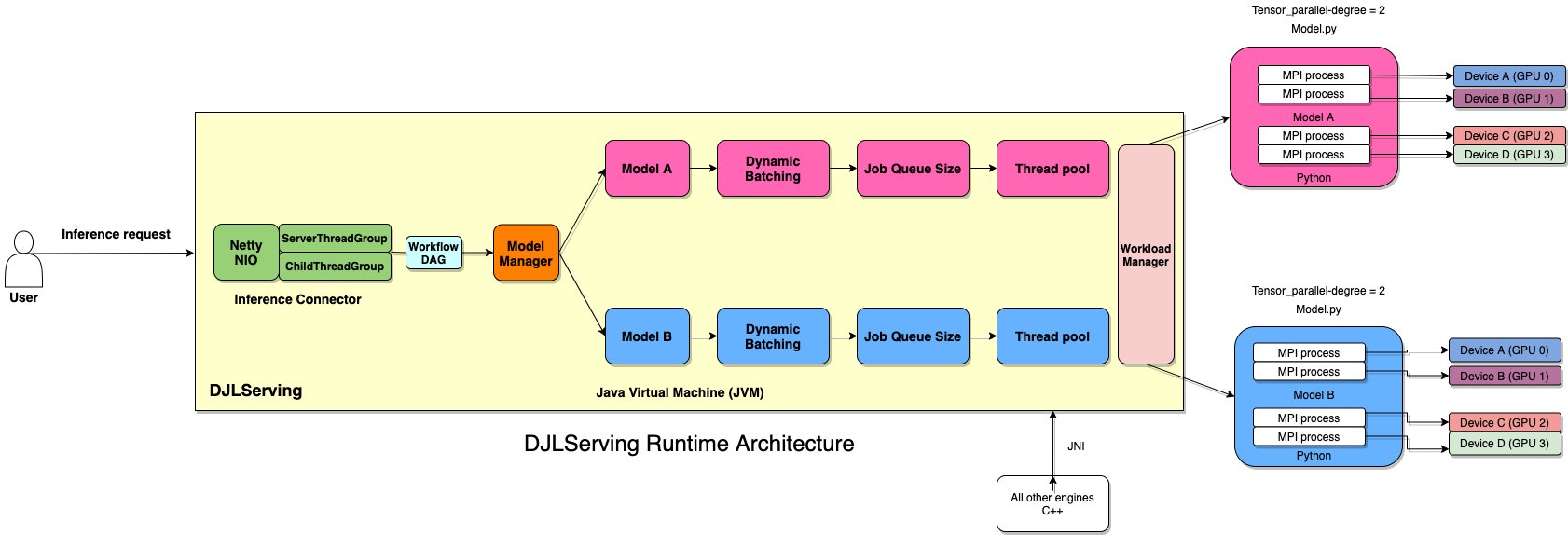
DJLServing is built with multiple layers. The routing layer is built on top of Netty. The remote requests are handled in the routing layer to distribute to workers, either threads in Java or processes in Python, to run inference. The total number of Java threads are set to 2 * cpu_core from the machine to make full usage of computing power. The worker numbers can be configured per model or the DJL’s auto-detection on hardware. The following diagram illustrates our architecture.
{kind=link}
Inference large models on SageMaker
The following steps demonstrate how to deploy a gpt-j-6B model in SageMaker using DJL serving. This is made possible by the capability to configure the EBS volume size, model download timeout time, and startup health-check timeout time. You can try out this demo by running the following notebook.
Pull the Docker image and push to Amazon ECR
The Docker image djl-serving:0.18.0-deepspeed is our DJL serving container with DeepSpeed incorporated. We then push this image to Amazon Elastic Container Registry (Amazon ECR) for later use. See the following code:
Create our model file
First, we create a file called serving.properties that contains only one line of code. This tells the DJL model server to use the Rubikon engine. Rubikon is an AWS developed large model supporting package. In this demo, it facilitates the MPI threads setup and socket connection. It also sets the number of GPUs (model slicing number) by reading in the TENSOR_PARALLEL_DEGREE parameter defined in our model.py file in the next paragraph. The file contains the following code:
Next, we create our model.py file, which defines our model as gpt-j-6B. In our code, we read in the TENSOR_PARALLEL_DEGREE environment variable (default value is 1). This sets the number of devices over which the tensor parallel modules are distributed. Please note, DeepSpeed provides a few built-in partition logics, and gpt-j-6B is one of them. We use it by specifying replace_method and relpace_with_kernel_inject. If you have your customized model and need DeepSpeed to partition effectively, you need to change relpace_with_kernel_inject to false and add injection_policy to make the runtime partition work. For more information, refer to Initializing for Inference.
We create a directory called gpt-j and copy model.py and serving.properties to this directory:
Lastly, we create the model file and upload it to Amazon Simple Storage Service (Amazon S3):
Create a SageMaker model
We now create a SageMaker model. We use the ECR image we created earlier and the model artifact from the previous step to create the SageMaker model. In the model setup, we configure TENSOR_PARALLEL_DEGREE=2, which means the model will be partitioned along 2 GPUs. See the following code:
After running the preceding command, you see output similar to the following:
Create a SageMaker endpoint
You can use any instances with multiple GPUs for testing. In this demo, we use a p3.16xlarge instance. In the following code, note how we set the ModelDataDownloadTimeoutInSeconds, ContainerStartupHealthCheckTimeoutInSeconds, and VolumeSizeInGB parameters to accommodate the large model size. The VolumeSizeInGB parameter is applicable to GPU instances supporting the EBS volume attachment.
Lastly, we create a SageMaker endpoint:
You see it printed out in the following code:
Starting the endpoint might take a while. You can try a few more times if you run into the InsufficientInstanceCapacity error.
Performance tuning
Performance tuning and optimization is an empirical process often involving multiple iterations. The number of parameters to tune is combinatorial and the set of configuration parameter values aren’t independent of each other. Various factors affect optimal parameter tuning, including payload size, type, and the number of ML models in the inference request flow graph, storage type, compute instance type, network infrastructure, application code, inference serving software runtime and configuration, and more.
SageMaker real-time inference is ideal for inference workloads where you have real-time, interactive, low-latency requirements. There are four most commonly used metrics for monitoring inference request latency for SageMaker inference endpoints:
Container latency – The time it takes to send the request, fetch the response from the model’s container, and complete inference in the container. This metric is available in Amazon CloudWatch as part of the invocation metrics published by SageMaker.
Model latency – The total time taken by all SageMaker containers in an inference pipeline. This metric is available in CloudWatch as part of the invocation metrics published by SageMaker.
Overhead latency – Measured from the time that SageMaker receives the request until it returns a response to the client, minus the model latency. This metric is available in CloudWatch as part of the invocation metrics published by SageMaker.
End-to-end latency – Measured from the time the client sends the inference request until it receives a response back. You can publish this as a custom metric in CloudWatch.
Container latency depends on several factors; the following are among the most important:
Underlying protocol (HTTP(s)/gRPC) used to communicate with the inference server
Overhead related to creating new TLS connections
Deserialization time of the request/response payload
Request queuing and batching features provided by the underlying inference server
Request scheduling capabilities provided by the underlying inference server
Underlying runtime performance of the inference server
Performance of preprocessing and postprocessing libraries before calling the model prediction function
Underlying ML framework backend performance
Model-specific and hardware-specific optimizations
In this section, we focus primarily on container latency and specifically on optimizing DJLServing running inside a SageMaker container.
Tune the ML engine for multi-threaded inference
One of the advantages of the DJL is multi-threaded inference support. It can help increase the throughput of your inference on multi-core CPUs and GPUs and reduce memory consumption compare to Python. Refer to Inference Performance Optimization for more information about optimizing the number of threads for different engines.
Tune Netty
DJLServing is built with multiple layers. The routing layer is built on top of Netty. Netty is a NIO client server framework that enables quick and easy development of network applications such as protocol servers and clients. In Netty, Channel is the main container; it contains a ChannelPipeline and is associated with an EventLoop (a container for a thread) from an EventLoopGroup. EventLoop is essentially an I/O thread and may be shared by multiple channels. ChannelHandlers are run on these EventLoop threads. This simple threading model means that you don’t need to worry about concurrency issues in the run of your ChannelHandlers. You are always guaranteed sequential runs on the same thread for a single run through your pipeline. DJLServing uses Netty’s EpollEventLoopGroup on Linux. The total number of Netty threads by default is set to 2 * the number of virtual CPUs from the machine to make full usage of computing power. Furthermore, because you don’t create large numbers of threads, your CPU isn’t overburdened by context switching. This default setting works fine in most cases; however, if you want to set the number of Netty threads for processing the incoming requests, you can do so by setting the SERVING_NUMBER_OF_NETTY_THREADS environment variable.
Tune workload management (WLM) of DJLServing
DJLServing has WorkLoadManager, which is responsible for managing the workload of the worker thread. It manages the thread pools and job queues, and scales up or down the required amount of worker threads per ML model. It has auto scaling, which adds an inference job to the job queue of the next free worker and scales up the worker thread pool for that specific model if necessary. The scaling is primarily based on the job queue depth of the model, the batch size, and the current number of worker threads in the pool. The job_queue_size controls the number of inference jobs that can be queued up at any point in time. By default, it is set to 100. If you have higher concurrency needs per model serving instance, you can increase the job_queue_size, thread pool size, and minimum or maximum thread workers for a particular model by setting the properties in serving.properties, as shown in the following example code:
As of this writing, you can’t configure job_queue_size in serving.properties. The default value job_queue_size is controlled by an environment variable, and you can only configure the per-model setting with the registerModel API.
Many practitioners tend to run inference sequentially when the server is invoked with multiple independent requests. Although easier to set up, it’s usually not the best practice to utilize GPU’s compute power. To address this, DJLServing offers the built-in optimizations of dynamic batching to combine these independent inference requests on the server side to form a larger batch dynamically to increase throughput.
All the requests reach the dynamic batcher first before entering the actual job queues to wait for inference. You can set your preferred batch sizes for dynamic batching using the batch_size settings in serving.properties. You can also configure max_batch_delay to specify the maximum delay time in the batcher to wait for other requests to join the batch based on your latency requirements.
You can fine-tune the following parameters to increase the throughput per model:
batch_size – The inference batch size. The default value is 1.
max_batch_delay – The maximum delay for batch aggregation. The default value is 100 milliseconds.
max_idle_time – The maximum idle time before the worker thread is scaled down.
min_worker – The minimum number of worker processes. For the DJL’s DeepSpeed engine, min_worker is set to number of GPUs/TENSOR_PARALLEL_DEGREE.
max_worker – The maximum number of worker processes. For the DJL’s DeepSpeed engine, max_worker is set to mumber of GPUs/TENSOR_PARALLEL_DEGREE.
Tune degree of tensor parallelism
For large model support that doesn’t fit in the single accelerator device memory, the number of Python processes are determined by the total number of accelerator devices on the host. The tensor_parallel_degree is created for slicing the model and distribute to multiple accelerator devices. In this case, even if a model is too large to host on a single accelerator, it can still be handled by DJLServing and can run on multiple accelerator devices by partitioning the model. Internally, DJLServing creates multiple MPI processes (equal to tensor_parallel_degree) to manage the slice of each model on each accelerator device.
You can set the number of partitions for your model by setting the TENSOR_PARALLEL_DEGREE environment variable. Please note this configuration is a global setting and applies to all the models on the host. If the TENSOR_PARALLEL_DEGREE is less than the total number of accelerator devices (GPUs), DJLServing launches multiple Python process groups equivalent to the total number of GPUs/TENSOR_PARALLEL_DEGREE. Each Python process group consists of Python processes equivalent to TENSOR_PARALLEL_DEGREE. Each Python process group holds the full copy of the model.
Summary
In this post, we showcased the newly launched SageMaker capability to allow you to configure inference instance EBS volumes, model downloading timeout, and container startup timeout. We demonstrated this new capability in an example of deploying a large model in SageMaker. We also covered options available to tune the performance of the DJL. For more details about SageMaker and the new capability launched, refer to [!Link] and [!Link].
About the authors
Frank Liu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking with friends and family.
Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
{kind=link}
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
{kind=link}
Robert Van Dusen is a Senior Product Manager at AWS.
{kind=link}
Alan Tan is a Senior Product Manager with SageMaker leading efforts on large model inference. He’s passionate about applying Machine Learning to the area of Analytics. Outside of work, he enjoys the outdoors.
{kind=link}
Read MoreAWS Machine Learning Blog