

{kind=link}
Amazon SageMaker Autopilot automatically builds, trains, and tunes the best machine learning (ML) models based on your data, while allowing you to maintain full control and visibility. We have recently announced support for time series data in Autopilot. You can use Autopilot to tackle regression and classification tasks on time series data, or sequence data in general. Time series data is a special type of sequence data where data points are collected at even time intervals.
Manually preparing the data, selecting the right ML model, and optimizing its parameters is a complex task, even for an expert practitioner. Although automated approaches exist that can find the best models and their parameters, these typically can’t handle data that comes as sequences, such as network traffic, electricity consumption, or household expenses recorded over time. Because this data takes the form of observations acquired at different time points, consecutive observations can’t be treated as independent of each other and need to be processed as a whole. You can use Autopilot for a wide range of problems dealing with sequential data. For example, you can classify network traffic recorded over time to identify malicious activities, or determine if individuals qualify for a mortgage based on their credit history. You provide a dataset containing time series data and Autopilot handles the rest, processing the sequential data through specialized feature transforms and finding the best model on your behalf.
Autopilot eliminates the heavy lifting of building ML models, and helps you automatically build, train, and tune the best ML model based on your data. Autopilot runs several algorithms on your data and tunes their hyperparameters on a fully managed compute infrastructure. In this post, we demonstrate how you can use Autopilot to solve classification and regression problems on time series data. For instructions on creating and training an Autopilot model, see Customer Churn Prediction with Amazon SageMaker Autopilot.
Time series data classification using Autopilot
As a running example, we consider a multi-class problem on the time series dataset UWaveGestureLibraryX, containing equidistant readings of accelerometer sensors while performing one of eight predefined hand gestures. For simplicity, we consider only X dimension of the accelerometer. The task is to build a classification model to map the time series data from the sensor readings to the predefined gestures. The following figure shows the first rows of the dataset in CSV format. The entire table consists of 896 rows and two columns: the first column is a gesture label and the second column is a time series of sensor readings.
{kind=link}
Convert data to the right format with Amazon SageMaker Data Wrangler
On top of accepting numerical, categorical, and standard text columns, Autopilot now also accepts a sequence input column. If your time series data doesn’t follow this format, you can easily convert it through Amazon SageMaker Data Wrangler. Data Wrangler reduces the time it takes to aggregate and prepare data for ML from weeks to minutes. With Data Wrangler, you can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization from a single visual interface. For instance, consider the same dataset but in a different input format: each gesture (specified by ID) is a sequence of equidistant measurements of the accelerometer. When stored vertically, each row contains a timestamp and one value. The following figure compares this data in its original format and a sequence format.
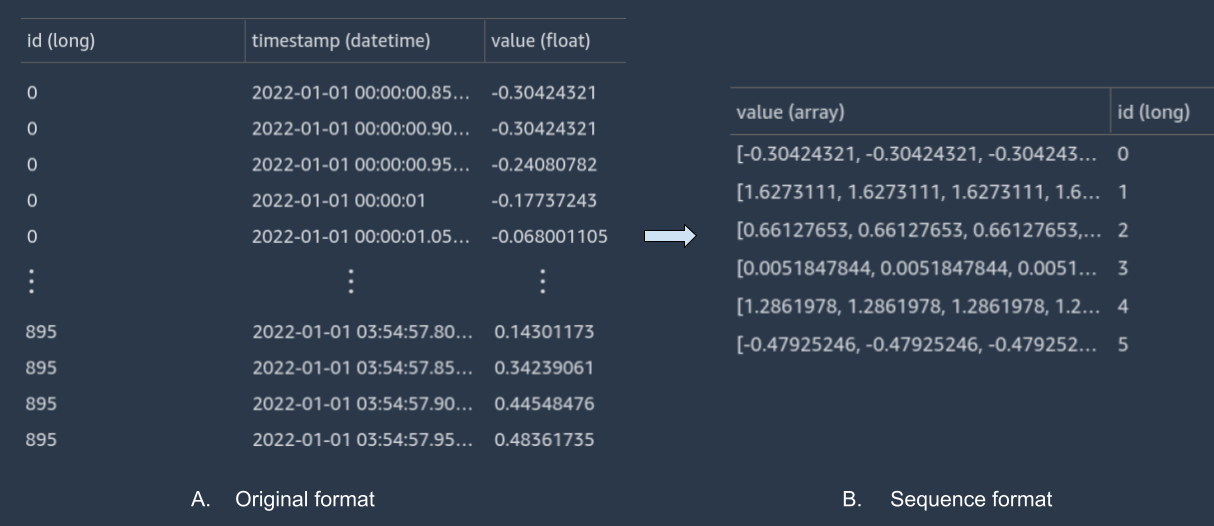{kind=link}
To convert this dataset to the format described earlier using Data Wrangler, load the dataset from Amazon Simple Storage Service (Amazon S3). Then use the time series Group by transform, as shown in the following screenshot, and export the data back to Amazon S3 in CSV format.
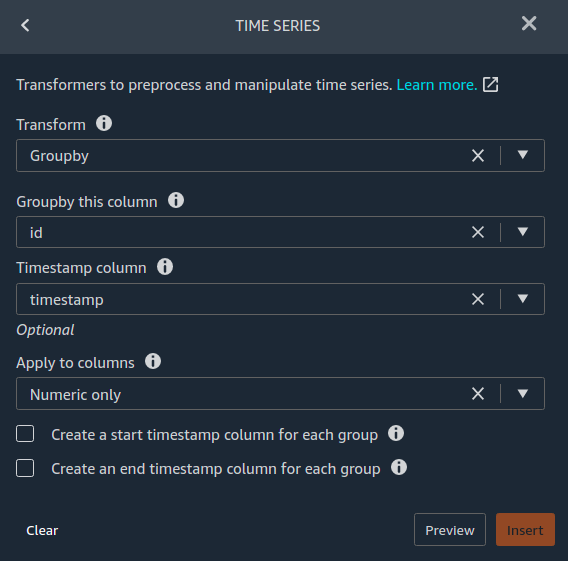{kind=link}
When the dataset is in its designated format, you can proceed with Autopilot. To check out other time series transformers of Data Wrangler refer to Prepare time series data with Amazon SageMaker Data Wrangler.
Launch an AutoML job
As with other input types supported by Autopilot, each row of the dataset is a different observation and each column is a feature. In this example, we have a single column containing time series data, but you can have multiple time series columns. You can also have multiple columns with different input types, such as time series, text, and numerical.
To create an Autopilot experiment, place the dataset in an S3 bucket and create a new experiment within Amazon SageMaker Studio. As shown in the following screenshot, you must specify the name of experiment, S3 location of the dataset, S3 location for the output artifacts, and the column name to predict.
{kind=link}
Autopilot analyzes the data, generates ML pipelines, and runs a default 250 iterations of hyperparameter optimization on this classification task. As shown in the following model leaderboard, Autopilot reaches 0.821 accuracy, and you can deploy the best model in just one click.
{kind=link}
In addition, Autopilot generates a data exploration report, where you can visualize and explore your data.
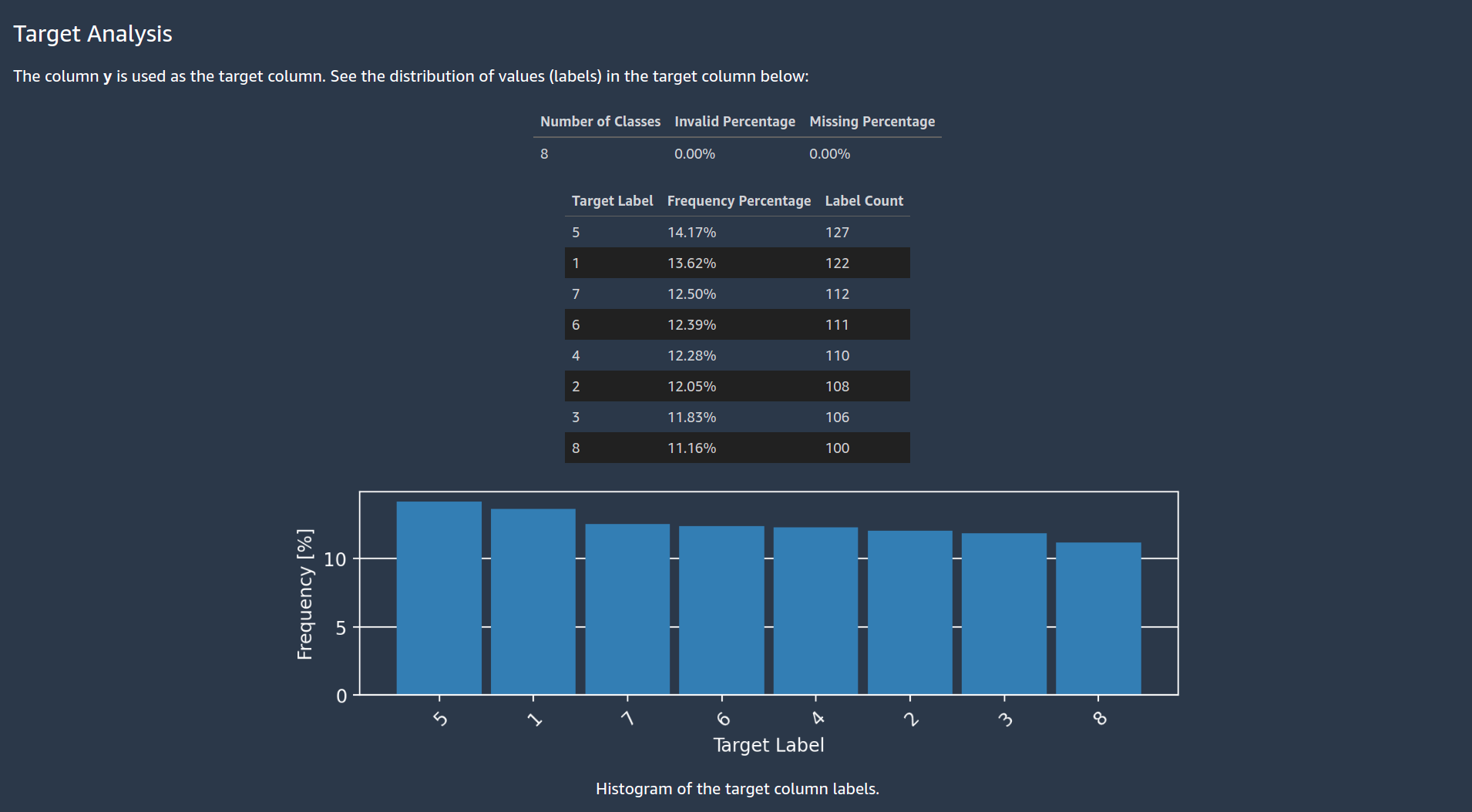{kind=link}
Transparency is foundational for Autopilot. You can inspect and modify generated ML pipelines within the candidate definition notebook. The following screenshot demonstrates how Autopilot recommends a range of pipelines, combining the time series transformer TSFeatureExtractor with different ML algorithms, such as gradient boosted decision trees and linear models. The TSFeatureExtractor extracts hundreds of time series features for you, which are then fed to the downstream algorithms to make predictions. For the full list of time series features, refer to Overview on extracted features.
{kind=link}
Conclusion
In this post, we demonstrated how to use SageMaker Autopilot to solve time series classification and regression problems in just a few clicks.
For more information about Autopilot, see Amazon SageMaker Autopilot. To explore related features of SageMaker, see Amazon SageMaker Data Wrangler.
About the Authors
Nikita Ivkin is an Applied Scientist, Amazon SageMaker Data Wrangler.
{kind=link}
Anne Milbert is a Software Development engineer working on Amazon SageMaker Automatic Model Tuning.
{kind=link}
Valerio Perrone is an Applied Science Manager working on Amazon SageMaker Automatic Model Tuning and Autopilot.
Meghana Satish is a Software Development engineer working on Amazon SageMaker Automatic Model Tuning.
{kind=link}
Ali Takbiri is an AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges on the AWS Cloud.
{kind=link}
Read MoreAWS Machine Learning Blog