

{kind=link}
An Oracle to Amazon Aurora PostgreSQL-Compatible Edition or Amazon RDS for PostgreSQL migration into the AWS Cloud can be a multistage process with different technologies and skills involved, starting from the assessment stage to the cutover stage. For more information about the migration process, see Database Migration—What Do You Need to Know Before You Start? and the following posts on best practices, including the migration process and infrastructure considerations, source database considerations, and target database considerations for the PostgreSQL environment.
Oracle database provides features and utilities like UTL_FILE and EXTERNAL tables to interact with files on the operating system. These features are often used in database code because of the simple PL/SQL interface and versatile usage. In contrast, Aurora PostgreSQL is a managed database offering, so it’s not possible to access files on the database server via SQL commands or utilities.
In this post, we cover the steps to integrate Amazon Simple Storage Service (Amazon S3) and Aurora PostgreSQL and create PL/pgSQL wrapper functions to interact with the files. With this solution, we can create and consume files in Amazon S3 from Aurora PostgreSQL using native PL/pgSQL calls, similar to the Oracle UTL_FILE utility. Although we focus on Aurora PostgreSQL you can use the same solution with Amazon RDS for PostgreSQL.
Prerequisites
To build such a solution, you need to be familiar with the following AWS services:
Amazon CloudWatch – A service that provides you with data and actionable insights to monitor your applications, respond to system-wide performance changes, optimize resource utilization, and get a unified view of operational health.
AWS Identity and Access Management – IAM lets you create and manage AWS users and groups, and use permissions to allow and deny their access to AWS resources.
AWS Lambda – A service that lets you run code without provisioning or managing servers. You pay only for the compute time you consume.
Aurora PostgreSQL – A service that allows you to create PostgreSQL-compatible relational database built for the cloud.
AWS Secrets Manager – This service enables you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle.
Amazon Simple Notification Service – Amazon SNS is a fully managed messaging service for both application-to-application (A2A) and application-to-person (A2P) communication.
Amazon S3 – An object storage service that offers industry-leading scalability, data availability, security, and performance.
Solution overview
The solution is divided into two sections:
Create IAM policies and roles – IAM policies and roles provide a secure way to grant access to S3 buckets to Aurora PostgreSQL without long-term credentials.
Integrate Amazon S3 and Aurora PostgreSQL – Before we can access Amazon S3 from Aurora PostgreSQL, we need to attach a role granting the required permissions to Aurora PostgreSQL along with the aws_s3 extension, which creates the required PL/pgSQL functions.
The following diagram gives a general overview of the integration and roles played by various services in this solution.
{kind=link}
We perform the following high-level steps:
Create two bucket policies, one for read and other one for write. These policies grant the required permissions on the S3 bucket.
Create two roles, one with a read policy and one with a write policy, and assign those roles to Aurora PostgreSQL.
Create the aws_s3 extension in Aurora PostgreSQL.
Place files in the S3 bucket, which are loaded into tables in Aurora PostgreSQL via PL/pgSQL commands.
Create IAM policies and roles
In this section, we set up the policies and roles required to gain access to an S3 bucket from Aurora PostgreSQL.
Create two IAM policies to grant access to the S3 bucket and objects in it (replace s3testauroradummy with the actual bucket name in your environment).
The following is the JSON code for the policy S3IntRead:
“Version”: “2012-10-17”,
“Statement”: [
{
“Sid”: “S3integrationtest”,
“Effect”: “Allow”,
“Action”: [
“s3:GetObject”,
“s3:ListBucket”
],
“Resource”: [
“arn:aws:s3:::s3testauroradummy/*”,
“arn:aws:s3:::s3testauroradummy”
]
}
]
}
The following is the JSON code for the policy S3IntWrite:
“Version”: “2012-10-17”,
“Statement”: [
{
“Sid”: “S3integrationtest”,
“Effect”: “Allow”,
“Action”: [
“s3:PutObject”,
“s3:ListBucket”
],
“Resource”: [
“arn:aws:s3:::s3testauroradummy/*”,
“arn:aws:s3:::s3testauroradummy”
]
}
]
}
Now you create roles for Aurora PostgreSQL and assign the policies you created.
On the IAM console, in the navigation pane, choose Roles.
Choose Create role.
For AWS service, choose RDS.
For Select your use case, choose RDS – Add Role to Database.
{kind=link}
Chose Next: Permissions.
For Attach permissions policies, select the policy you created.
Choose Next: Tags.
Choose Next: Review.
Enter a name for the role (for example, rds-s3-integration-role) and an optional description.
Choose Create role.
You create two roles: one with the read policy and the other with the write policy.
{kind=link}
Integrate Amazon S3 and Aurora PostgreSQL
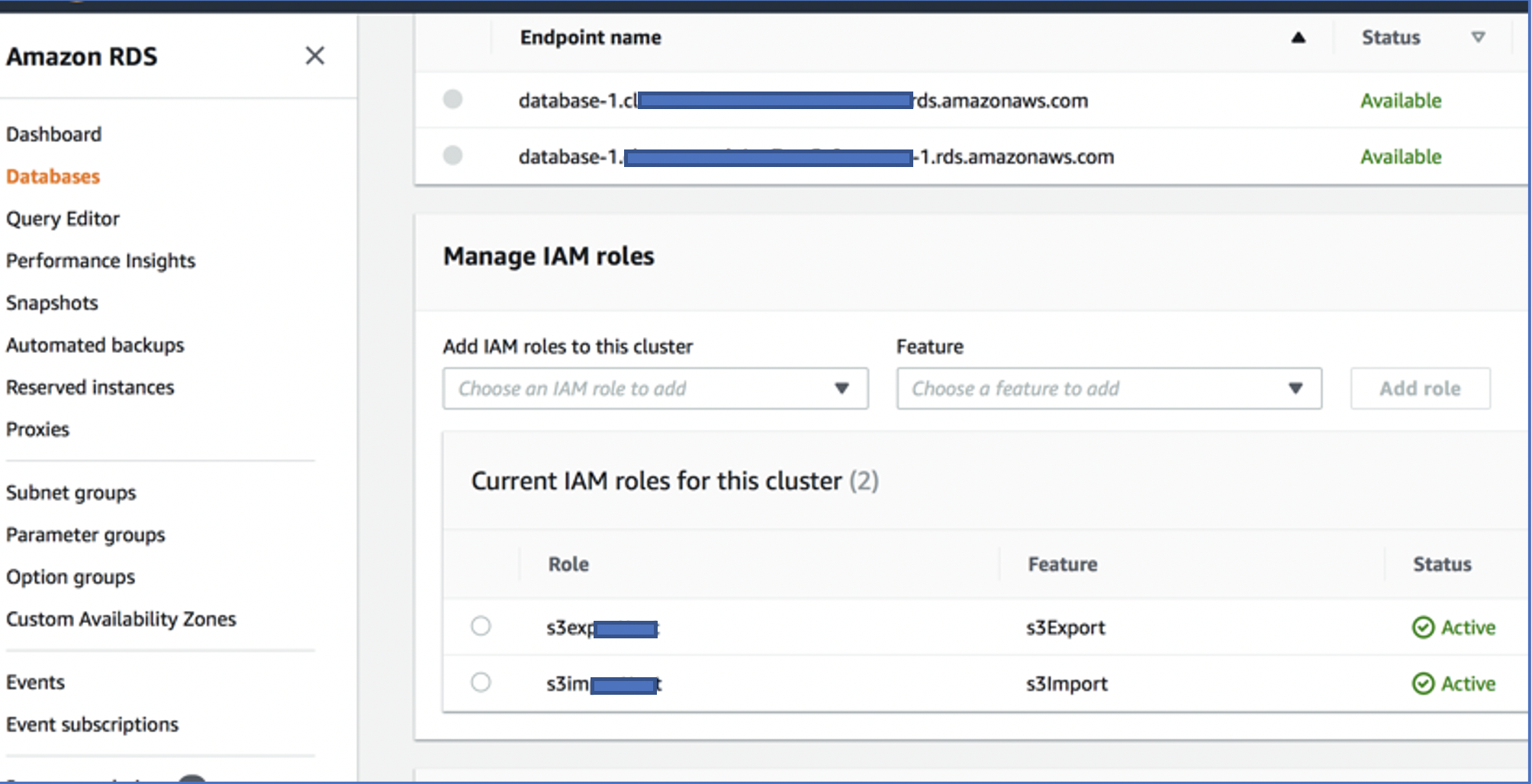
To integrate Amazon S3 and Aurora PostgreSQL, we attach the IAM roles to the target Aurora PostgreSQL cluster, and create supporting extensions.
On the Amazon RDS console, navigate to the Postgres DB cluster to display its details.
On the Connectivity & Security tab, in the Manage IAM roles section, search and choose the read role under Add IAM roles to this instance.
For Feature, choose S3Import.
Choose Add role.
Now you add your second role.
For Add IAM roles to this instance, choose the write role.
For Feature, choose s3Export.
Choose Add role.
{kind=link}
Create the extensions aws_s3 and aws_common with the following code:
The following screenshot shows the output expected.
{kind=link}
Validate Amazon S3 and Aurora PostgreSQL integration
Now that we have created the necessary roles, assigned those to Aurora PostgreSQL, and created the necessary extensions, we’re ready to validate our setup. In the following example code, replace s3testauroradummy with the actual bucket name in your environment (same you used during the policy creation).
Import test
To test import abilities, complete the following steps:
Create the sample CSV file load_test.csv and upload it to Amazon S3:
2:Martha Rivera:35:Technology Architect
Create the table definition as per the CSV file:
id integer,
name varchar,
age smallint,
role varchar
);
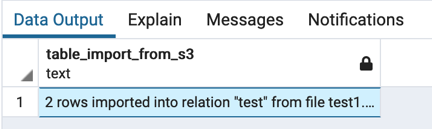
Load the file into the table using the aws_s3.table_import_from_s3 function (don’t forget to replace s3testauroradummy with your own bucket name):
( ‘test’,
”,
‘DELIMITER AS ”:”’,
aws_commons.create_s3_uri
( ‘s3testauroradummy’,
‘load_test.csv’ ,
‘us-east-1’)
);
The following screenshot shows the output expected.
{kind=link}
The aws_s3.table_import_from_s3 function uses the following options:
table_name text,
column_list text,
options text,
aws_commons.create_s3_uri(
bucket text,
file_path text,
region text
) ) ;
Export test
To test export abilities, complete the following steps:
Create a test table:
id integer,
name varchar,
age smallint,
role varchar,
designation varchar
);
Populate data into the test table:
Export the data from the test table in Amazon S3 using the aws_s3.query_export_to_s3 function (don’t forget to replace s3testauroradummy with your own bucket name):
The following screenshot shows the output expected.
{kind=link}
The aws_s3.query_export_to_s3 function uses following options
query text,
aws_commons.create_s3_uri(
bucket text,
file_path text,
region text),
options text
)
Log in to the Amazon S3 console verify that the test file is created in the right path and S3 bucket.
Now that we have validated our ability to export and import files, let’s create a few wrapper functions similar to UTL_FILE from Oracle to minimize code changes during migration.
Create wrapper functions
The following wrapper functions provide a way to encapsulate Amazon S3 and Aurora PostgreSQL integration behind simple PL/pgSQL calls. These wrapper functions also reduce changes required in applications that need to interact with files in Amazon S3. Keep in mind that wrapper functions are created assuming a single S3 bucket is involved. In the following example code, replace s3testauroradummy with the bucket in your environment.
Create the utl_file_utility schema, which we use to consolidate our wrapper functions:
Create the type file_type, which we use to return file information like the path and name, similar to the Oracle file handler:
p_path character varying,
p_file_name character varying
);
Create a table to store the current state of a file operation:
Create an init function to initialize common variables like bucket and Region (don’t forget to replace s3testauroradummy with your own bucket name):
)
RETURNS void
LANGUAGE ‘plpgsql’
COST 100
VOLATILE
AS $BODY$
BEGIN
perform set_config
( format( ‘%s.%s’,’UTL_FILE_UTILITY’, ‘region’ )
, ‘us-east-1’::text
, false );
perform set_config
( format( ‘%s.%s’,’UTL_FILE_UTILITY’, ‘s3bucket’ )
, ‘s3testauroradummy’::text
, false );
END;
$BODY$;
The preceding function uses the set_config command to set the Region and bucket name one time and use them across different functions. If required, in the future we can change both the Region and parameter by changing one function instead of multiple ones.
Create the is_open function to check if an operation is already going on the file:
p_file_name character varying,
p_path character varying)
RETURNS boolean
LANGUAGE ‘plpgsql’
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
DECLARE
v_cnt int;
BEGIN
/* check if utl_file_utility.file_status has an entry */
SELECT count(*) into v_cnt
FROM utl_file_utility.file_status
WHERE file_name = p_file_name
AND file_path = p_path
AND upper(status) = ‘OPEN’
AND pid in ( select pid from pg_stat_activity );
IF v_cnt > 0
THEN
return true;
ELSE
return false;
end IF;
EXCEPTION
when others then
raise notice ‘error raised in is_open %’,sqlerrm;
RAISE;
END;
$BODY$;
Now we create the wrapper function fopen to create a file in Amazon S3 based on the input mode requested. The fopen function creates a temporary table and, based on the mode, it proceeds further.
For mode ‘A’/append, it looks for the mentioned file name in the S3 bucket. If the file name is present, it loads the file into temporary tables; if not, it creates an empty file in Amazon S3.
If the input mode is ‘W’/Write, it creates an empty file in the S3 bucket. For read mode, it reads the file from Amazon S3 and puts the data into a temporary table.
Create the fopen wrapper function with the following code:
p_file_name character varying,
p_path character varying,
p_mode character DEFAULT ‘W’::bpchar,
OUT p_file_type utl_file_utility.file_type,
OUT p_status boolean)
RETURNS record
LANGUAGE ‘plpgsql’
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
declare
v_sql character varying;
v_cnt_stat integer;
v_cnt integer;
v_tabname character varying;
v_filewithpath character varying;
v_region character varying;
v_bucket character varying;
v_file_status boolean;
BEGIN
/*initialize common variable */
PERFORM utl_file_utility.init();
v_region := current_setting( format( ‘%s.%s’, ‘UTL_FILE_UTILITY’, ‘region’ ) );
v_bucket := current_setting( format( ‘%s.%s’, ‘UTL_FILE_UTILITY’, ‘s3bucket’ ) );
/* set tabname*/
v_tabname := substring(p_file_name,1,case when strpos(p_file_name,’.’) = 0 then length(p_file_name) else strpos(p_file_name,’.’) – 1 end );
v_filewithpath := case when NULLif(p_path,”) is null then p_file_name else concat_ws(‘/’,p_path,p_file_name) end ;
raise notice ‘v_bucket %, v_filewithpath % , v_region %’, v_bucket,v_filewithpath, v_region;
p_status := FALSE ;
/* create temp table */
v_sql := concat_ws(”,’create temp table if not exists ‘, v_tabname,’ (col1 text)’);
execute v_sql;
/* APPEND MODE HANDLING; RETURN EXISTING FILE DETAILS IF PRESENT ELSE CREATE AN EMPTY FILE */
IF p_mode = ‘A’ THEN
begin
PERFORM aws_s3.table_import_from_s3
( v_tabname,
”,
‘DELIMITER AS ”^”’,
aws_commons.create_s3_uri
( v_bucket,
v_filewithpath ,
v_region)
);
exception
when others then
raise notice ‘File load issue : %’,sqlerrm;
IF sqlerrm not like ‘%file does not exist%’ then
raise;
end IF;
end;
execute concat_ws(”,’select count(*) from ‘,v_tabname) into v_cnt;
IF v_cnt > 0
then
p_file_type.p_path := v_filewithpath;
p_file_type.p_file_name := p_file_name;
p_status := TRUE;
else
PERFORM aws_s3.query_export_to_s3(‘select ””’,
aws_commons.create_s3_uri(v_bucket, v_filewithpath, v_region)
);
p_file_type.p_path := v_filewithpath;
p_file_type.p_file_name := p_file_name;
p_status := TRUE;
end IF;
ELSEIF p_mode = ‘W’ THEN
PERFORM aws_s3.query_export_to_s3(‘select ””’,
aws_commons.create_s3_uri(v_bucket, v_filewithpath, v_region)
);
p_file_type.p_path := v_filewithpath;
p_file_type.p_file_name := p_file_name;
p_status := TRUE;
/*open file in read mode and load into temp table */
ELSEIF p_mode = ‘R’ THEN
begin
PERFORM aws_s3.table_import_from_s3
( v_tabname,
”,
‘DELIMITER AS ”^”’,
aws_commons.create_s3_uri
( v_bucket,
v_filewithpath ,
v_region)
);
p_status := TRUE;
exception
when others then
raise notice ‘File read issue : %’,sqlerrm;
raise;
end;
END IF;
/*create an entry into file status control table */
INSERT INTO utl_file_utility.file_Status(file_name,status,file_path,pid)
VALUES(p_file_name,’open’,p_path,pg_backend_pid());
EXCEPTION
when others then
p_file_type.p_path := v_filewithpath;
p_file_type.p_file_name := p_file_name;
raise notice ‘fopen error,% ‘,sqlerrm;
PERFORM utl_file_utility.cleanup(p_file_name,p_path) ;
raise;
END;
$BODY$;
Next, we create the wrapper function put_line to write data into a temporary table in Aurora PostgreSQL. We use the temporary table to capture all the data and write into Amazon S3 in one step instead of performing multiple writes, which improves performance.
Create the wrapper function put_line with the following code:
p_file_name character varying,
p_path character varying,
p_line text)
RETURNS boolean
LANGUAGE ‘plpgsql’
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
/*************************************************************************** Write line
**************************************************************************/
declare
v_ins_sql varchar;
v_cnt INTEGER;
v_filewithpath character varying;
v_tabname character varying;
v_bucket character varying;
v_region character varying;
BEGIN
PERFORM utl_file_utility.init();
v_tabname := substring(p_file_name,1,case when strpos(p_file_name,’.’) = 0 then length(p_file_name) else strpos(p_file_name,’.’) – 1 end );
/* INSERT INTO TEMP TABLE */
v_ins_sql := concat_ws(”,’INSERT INTO ‘,v_tabname,’ VALUES(”’,p_line,”’)’);
execute v_ins_sql;
RETURN TRUE;
EXCEPTION
when others then
raise notice ‘put_line Error Message : %’,sqlerrm;
PERFORM utl_file_utility.cleanup(p_file_name,p_path) ;
raise;
END;
$BODY$;
Create the wrapper function fclose to extract data from the temporary table and write to Amazon S3:
p_file_name character varying,
p_path character varying)
RETURNS boolean
LANGUAGE ‘plpgsql’
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
DECLARE
v_filewithpath character varying;
v_bucket character varying;
v_region character varying;
v_tabname character varying;
v_sql character varying;
BEGIN
PERFORM utl_file_utility.init();
/* setting region, bucket , tabname and path */
v_region := current_setting( format( ‘%s.%s’, ‘UTL_FILE_UTILITY’, ‘region’ ) );
v_bucket := current_setting( format( ‘%s.%s’, ‘UTL_FILE_UTILITY’, ‘s3bucket’ ) );
v_tabname := substring(p_file_name,1,case when strpos(p_file_name,’.’) = 0 then length(p_file_name) else strpos(p_file_name,’.’) – 1 end );
v_filewithpath := case when NULLif(p_path,”) is null then p_file_name else concat_ws(‘/’,p_path,p_file_name) end ;
raise notice ‘v_bucket %, v_filewithpath % , v_region %’, v_bucket,v_filewithpath, v_region ;
/* check for blank file write */
v_sql := concat_ws(”,’select count(1) from ‘,v_tabname);
execute v_sql into v_cnt ;
if v_cnt > 0 then
/* exporting to s3 */
perform aws_s3.query_export_to_s3
(concat_ws(”,’select * from ‘,v_tabname,’ order by ctid asc’),
aws_commons.create_s3_uri(v_bucket, v_filewithpath, v_region)
);
else
perform aws_s3.query_export_to_s3
(‘select ””’,
aws_commons.create_s3_uri(v_bucket, v_filewithpath, v_region)
);
end if;
/* drop temp table as file is closed*/
v_sql := concat_ws(”,’drop table ‘,v_tabname);
execute v_sql;
/*updating the file status */
UPDATE utl_file_utility.file_Status
set status = ‘closed’
WHERE file_name = p_file_name
AND file_path = p_path;
RETURN TRUE;
EXCEPTION
when others then
raise notice ‘fclose error : %’,sqlerrm;
PERFORM utl_file_utility.cleanup(p_file_name,p_path) ;
execute v_sql;
RAISE;
END;
$BODY$;
Create the function get_line to read the file from Amazon S3 and return data to a record variable:
p_file_name character varying,
p_path character varying,
p_buffer text)
RETURNS text
LANGUAGE ‘plpgsql’
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
DECLARE
v_tabname varchar;
v_sql varchar;
BEGIN
/* identify table name */
v_tabname := substring(p_file_name,1,case when strpos(p_file_name,’.’) = 0 then length(p_file_name) else strpos(p_file_name,’.’) – 1 end );
v_sql := concat_ws(”,’select string_agg(col1,E”n”) from ‘,v_tabname);
execute v_sql into p_buffer;
return p_buffer;
EXCEPTION
when others then
raise notice ‘error get_line %’,sqlerrm;
PERFORM utl_file_utility.cleanup(p_file_name,p_path) ;
RAISE;
END;
$BODY$;
Create the wrapper function fgetattr to get bytes uploaded to Amazon S3:
p_file_name character varying,
p_path character varying)
RETURNS bigint
LANGUAGE ‘plpgsql’
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
DECLARE
v_filewithpath character varying;
v_bucket character varying;
v_region character varying;
v_tabname character varying;
l_file_length bigint ;
l_fs utl_file_utility.file_type ;
BEGIN
PERFORM utl_file_utility.init();
v_region := current_setting( format( ‘%s.%s’, ‘UTL_FILE_UTILITY’, ‘region’ ) );
v_bucket := current_setting( format( ‘%s.%s’, ‘UTL_FILE_UTILITY’, ‘s3bucket’ ) );
v_tabname := substring(p_file_name,1,case when strpos(p_file_name,’.’) = 0 then length(p_file_name) else strpos(p_file_name,’.’) – 1 end );
v_filewithpath := case when NULLif(p_path,”) is null then p_file_name else concat_ws(‘/’,p_path,p_file_name) end ;
/* exporting to s3 */
SELECT bytes_uploaded into l_file_length from aws_s3.query_export_to_s3
(concat_ws(”,’select * from ‘,v_tabname,’ order by ctid asc’),
aws_commons.create_s3_uri(v_bucket, v_filewithpath, v_region)
);
RETURN l_file_length;
EXCEPTION
when others then
raise notice ‘error fgetattr %’,sqlerrm;
RAISE;
END;
$BODY$;
Create the function cleanup to update file status and drop the temporary table created to store data:
p_file_name character varying,
p_path character varying)
RETURNS boolean
LANGUAGE ‘plpgsql’
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
DECLARE
v_tabname varchar;
v_sql varchar ;
BEGIN
/*identify table name */
v_tabname := substring(p_file_name,1,case when strpos(p_file_name,’.’) = 0 then length(p_file_name) else strpos(p_file_name,’.’) – 1 end );
/*dropping the temp table */
v_sql := concat_ws(”,’drop table if exists ‘,v_tabname);
execute v_sql ;
/*updating the file status */
UPDATE utl_file_utility.file_Status
set status = ‘closed’
WHERE file_name = p_file_name
AND file_path = p_path;
RETURN TRUE ;
EXCEPTION
when others then
raise notice ‘error in cleanup : % ‘,sqlerrm;
RAISE;
END;
$BODY$;
Test wrapper functions
Let’s go through few scenarios to see these wrapper functions in action.
The following anonymous code block opens a file in Amazon S3 in write mode and adds data to it:
declare
l_file_name varchar := ‘s3inttest’ ;
l_path varchar := ‘integration_test’ ;
l_mode char(1) := ‘W’;
l_fs utl_file_utility.file_type ;
l_status boolean;
l_record record;
l_is_open boolean;
begin
select * from utl_file_utility.is_open(l_file_name, l_path ) into l_is_open ;
raise notice ‘is_open : l_is_open % ‘, l_is_open ;
if l_is_open is false then
select * from utl_file_utility.fopen( l_file_name, l_path , l_mode ) into l_record;
raise notice ‘fopen : l_fs : % , % ‘, l_record.p_file_type, l_record.p_status;
select * from utl_file_utility.put_line( l_file_name, l_path ,’this is test file:in s3bucket: for test purpose’ ) into l_status ;
raise notice ‘put_line : l_status %’, l_status;
select * from utl_file_utility.fclose( l_file_name , l_path ) into l_status ;
raise notice ‘fclose : l_status %’, l_status;
else
raise notice ‘file is already open, please run utl_file_utility.cleanup’ ;
end if;
end;
$$
The following anonymous code adds additional data to the file created in the previous code:
declare
l_file_name varchar := ‘s3inttest’ ;
l_path varchar := ‘integration_test’ ;
l_mode char(1) := ‘A’;
l_fs utl_file_utility.file_type ;
l_status boolean;
l_record record;
l_is_open boolean;
begin
select * from utl_file_utility.is_open(l_file_name, l_path ) into l_is_open ;
raise notice ‘is_open : l_is_open % ‘, l_is_open ;
if l_is_open is false then
select * from utl_file_utility.fopen( l_file_name, l_path , l_mode ) into l_record ;
raise notice ‘fopen : l_fs : % , % ‘, l_record.p_file_type, l_record.p_status;
select * from utl_file_utility.put_line( l_file_name, l_path ,’this is test file:in s3bucket: for test purpose : append 1’ ) into l_status ;
raise notice ‘put_line : l_status %’, l_status;
select * from utl_file_utility.put_line( l_file_name, l_path ,’this is test file:in s3bucket : for test purpose : append 2′ ) into l_status ;
raise notice ‘put_line : l_status %’, l_status;
select * from utl_file_utility.fclose( l_file_name , l_path ) into l_status ;
raise notice ‘fclose : l_status %’, l_status;
else
raise notice ‘file is already open, please run utl_file_utility.cleanup’ ;
end if;
end;
$$
The following code reads a file from the S3 bucket:
declare
l_file_name varchar := ‘s3inttest’ ;
l_path varchar := ‘integration_test’ ;
l_mode char(1) := ‘R’;
l_fs utl_file_utility.file_type ;
l_status boolean;
l_record record;
l_is_open boolean;
l_buffer text;
begin
select * from utl_file_utility.is_open(l_file_name, l_path ) into l_is_open ;
raise notice ‘is_open : l_is_open % ‘, l_is_open ;
if l_is_open is false then
select * from utl_file_utility.fopen( l_file_name, l_path , l_mode ) into l_record;
raise notice ‘fopen : l_fs : % , % ‘, l_record.p_file_type, l_record.p_status;
select * from utl_file_utility.get_line(l_file_name ,l_path ,’2048’) into l_buffer;
raise notice ‘get_line : l_buffer %’, l_buffer;
select * from utl_file_utility.fclose( l_file_name , l_path ) into l_status ;
raise notice ‘fclose : l_status %’, l_status;
else
raise notice ‘file is already open, please run utl_file_utility.cleanup’ ;
end if;
end;
$$
Export data into multiple files based on a file size threshold with the following code:
declare
l_initial_file_name varchar := ‘filesizetest’ ;
l_file_name varchar ;
l_path varchar := ‘integration_test’ ;
l_mode char(1) := ‘W’;
l_fs utl_file_utility.file_type ;
l_status boolean;
l_data record;
l_file_length bigint := 0 ;
l_rename_size bigint := 200 ; — bytes
i integer := 0 ;
l_record record;
l_is_open boolean;
begin
l_file_name := l_initial_file_name ;
select * from utl_file_utility.is_open(l_file_name, l_path ) into l_is_open ;
raise notice ‘is_open : l_is_open % ‘, l_is_open ;
if l_is_open is false then
select * from utl_file_utility.fopen( l_file_name, l_path , l_mode ) into l_record ;
raise notice ‘fopen : l_fs : % , % ‘, l_record.p_file_type, l_record.p_status;
i := 1 ; — used as an extension to create new file name
for l_data in SELECT concat_ws(‘,’,md5(RANDOM()::TEXT), md5(RANDOM()::TEXT), CASE WHEN RANDOM() < 0.5 THEN ‘male’ ELSE ‘female’ END) FROM generate_series(1, 10) loop
raise notice ‘l_record %’, l_record ;
select * from utl_file_utility.put_line( l_file_name, l_path , l_data::text ) into l_status ;
raise notice ‘put_line : l_status %’, l_status;
/* get file stats */
select * from utl_file_utility.fgetattr( l_file_name, l_path) into l_file_length;
raise notice ‘bytes_uploaded : l_file_length %’, l_file_length;
if l_file_length >= l_rename_size then
/* close exsiting file as threshold is breached */
select * from utl_file_utility.fclose( l_file_name , l_path ) into l_status ;
raise notice ‘fclose : l_status %’, l_status;
/* create a new file name to prevent file overwrite */
i := i + 1 ;
l_file_name := concat(l_initial_file_name,’_’,i)::varchar ;
/* run fopen as new file name is created */
select * from utl_file_utility.fopen( l_file_name, l_path , l_mode ) into l_record ;
raise notice ‘fopen : l_fs : % , % ‘, l_record.p_file_type, l_record.p_status;
end if;
end loop;
select * from utl_file_utility.fclose( l_file_name , l_path ) into l_status ;
raise notice ‘fclose : l_status %’, l_status;
else
raise notice ‘file is already open, please run utl_file_utility.cleanup’ ;
end if;
end;
$$
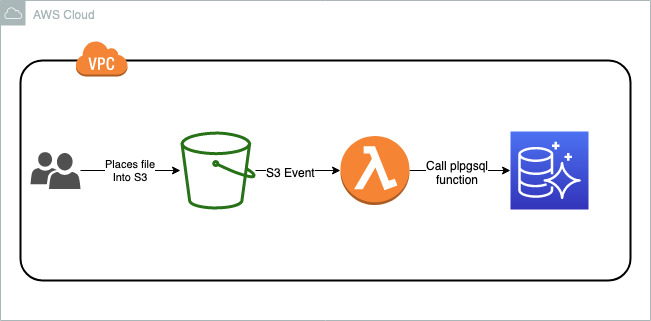
Automated load of data via Lambda function
We can write a Lambda function to automatically load data into Aurora PostgreSQL. We can call this Lambda function from an application to do a scheduled load, or configure it to get triggered based on Amazon S3 event notifications.
The following diagram illustrates this workflow.
{kind=link}
The Lambda function has a runtime limit of 15 minutes; if needed, you can divide your code and use AWS Step Functions.
Considerations
Consider the following when using this solution:
Amazon S3 and Aurora PostgreSQL integration is not a replacement for Oracle UTL_FILE, but an alternative approach.
Cross-Region export isn’t possible with this integration, which means you can’t have a bucket in us-east-1 while a PostgreSQL instance is present in ap-southeast-1.
For simplicity, we restricted ourselves to one S3 bucket. This assumption might not be true in your environment; you can use a reference table using an S3 bucket name, file name, and path as attributes, and a function to take input of the file name and path and return the S3 bucket.
This test code is a proof of concept and is provided as is. Take the time to test, make changes, and validate the code to meet your requirements.
Conclusion
This post demonstrated how to integrate Amazon S3 and Aurora PostgreSQL to provide a way to interact with files similar to Oracle’s UTL_FILE utility. We also created wrapper functions to minimize possible application or database code changes required during migration. Lastly, we discussed possible automation via Lambda to load tables into a database. Try out this solution, and leave your feedbacks, thoughts and ideas in the comments.
About the Author
Rakesh Raghav is a Consultant with the AWS Proserve Team in India, helping customers with successful cloud adoption and migration journey. He is passionate about building innovative solutions to accelerate database journey to cloud.
{kind=link}
Anuradha Chintha is an Associate Consultant with Amazon Web Services. She works with customers to build scalable, highly available and secure solutions in the AWS cloud. Her focus area is homogenous and heterogeneous database migrations.
{kind=link}
Read MoreAWS Database Blog