

{kind=link}
AWS Database Migration Service (AWS DMS) is a managed service that you can use to migrate data from various source data engines to supported targets. When migrating data from an Oracle source to PostgreSQL-compatible target, you often encounter special data type transformation scenarios that require using the rich set of transformation rules AWS DMS provides. One such example is the Oracle RAW data type which you can use to store Globally Unique Identifier (GUID) data to the Universally Unique Identifier (UUID) data type in PostgreSQL, because by default AWS DMS converts the Oracle RAW data type to BYTEA in PostgreSQL.
In this post, we show you two methods to perform data type conversion with AWS DMS: using materialized views and using expressions in your transformation rules.
Solution overview
AWS DMS allows you to use SQLite operators and SQLite functions within a transformation rule to compute column values that you can apply to any selected schema, table, or view. In addition, AWS DMS supports expressions, which means using SQLite operators or functions to define the data in a column. In this post, we provide examples of how to use SQLite operators and SQLite functions in transformation rules to convert Oracle GUID in RAW data type columns to UUID data type format on PostgreSQL.
We describe two methods in this post: using materialized views and using expressions in your transformation rules, which work for other data types or similar use cases. We provide CloudFormation template and scripts that can be deployed to test the solutions.
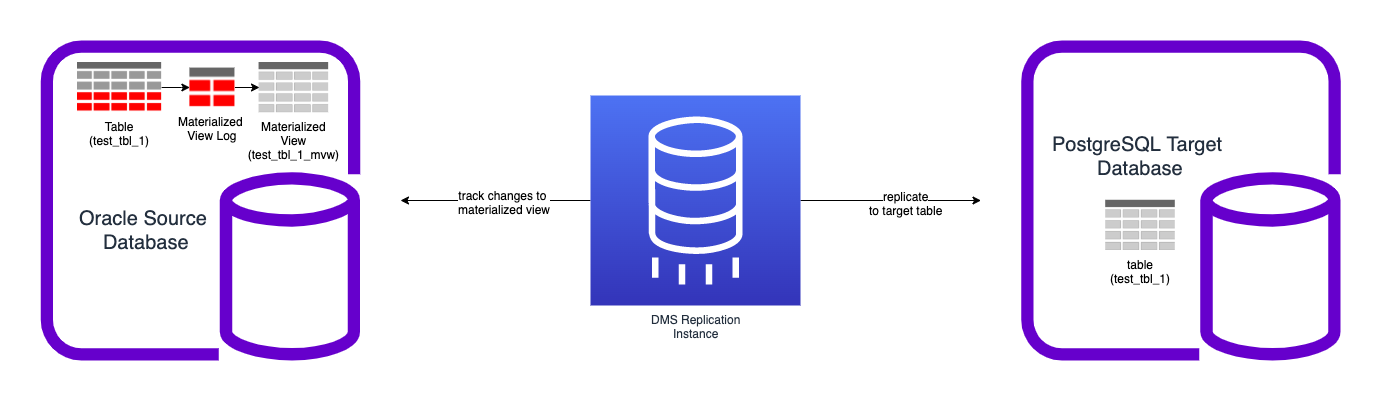
Method 1: Materialized view approach
This involves using materialized view to first convert GUID data to UUID format on the Oracle source itself, then using an AWS DMS task to load the data directly from the materialized view to the PostgreSQL target.
{kind=link}
Method 2: Expressions in AWS DMS table-mapping approach
We use SQLite operators like Concatenate, SQLite functions like substring (SUBSTR), hexadecimal functions (HEX), and lowercase (LOWER) functions to break the GUID data into several groups separated by hyphens, specifically a group of 8 digits followed by three groups of 4 digits followed by a group of 12 digits, for a total of 32 digits representing the 128 bits.
{kind=link}
The common workaround for such edge conversion requirements is to first transform the data at the source using a view, then create an AWS DMS task to load the data as presented by the view created at the source. Unlike materialized views, which are disk based (data is stored in a table and updated periodically based on the query definition), using the view approach is limited to full load only and doesn’t provide the ongoing data replication option needed for AWS DMS continuous data replication to the target database.
Prerequisites
The following are the prerequisites for this example:
Access to an AWS account with IAM policy
Familiarity with the following AWS services:
AWS CloudFormation
AWS Command Line Interface (AWS CLI)
AWS DMS
IAM
Amazon Relational Database Service (Amazon RDS) for Oracle
Amazon Relational Database Service (Amazon RDS) for PostgreSQL
Amazon Virtual Private Cloud (Amazon VPC)
Familiarity with Oracle SQL*Plus client.
Familiarity with PostgreSQL psql client.
Set up the environment
The following CloudFormation template provisions an Amazon VPC with an RDS for Oracle instance under the License Included (LI) model, an RDS for PostgreSQL instance, an Amazon Elastic Compute Cloud (Amazon EC2) instance, AWS DMS replication instance, AWS DMS endpoints, and AWS DMS replication tasks for the examples discussed in this post.
You can use your existing Oracle database or use your existing RDS for Oracle Bring Your Own License (BYOL) instance. With BYOL you must have the appropriate Oracle Database license (with Software Update License and Support) for the DB instance class and Oracle Database edition you wish to run. You must also follow Oracle’s policies for licensing Oracle Database software in the cloud computing environment. For more information, see Oracle licensing options.
Create a key pair if you don’t have one already.
{kind=link}
Save the file; you need it to connect to the Amazon EC2 host in later steps.
Download the CloudFormation template from the GitHub repository.
On the AWS CloudFormation console, create a stack with the CloudFormation template dms-template.yaml
For Stack name, enter a name.
For DBPassword, enter a password. Remember this password for database connection.
For Ec2HostKeyPair, enter an existing key pair.
Accept the remaining defaults.
Acknowledge AWS CloudFormation might create IAM resources with customer names and choose Create stack. The deployment takes 20-30 minutes to complete.
{kind=link}
Ensure the CloudFormation stack completed successfully by checking the AWS CloudFormation console.
{kind=link}
On the Databases page of the Amazon RDS console, you can confirm that both the RDS for Oracle instance and RDS for PostgreSQL instance are created and available.
{kind=link}
On the AWS DMS console, you can check that both AWS DMS endpoints are created and shows a successful status.
{kind=link}
{kind=link}
Configure Oracle database
In order for AWS DMS to capture ongoing transactions from the Oracle database, complete the following steps:
Connect to the EC2 host deployed by the CloudFormation stack:
{kind=link}
Connect to the Oracle source database using the alias ora-src already configured in .bash_profile:
{kind=link}
Enable minimal supplemental logging:
{kind=link}
Grant the required privileges to the user (sports) used in the AWS DMS Oracle source endpoint connection.
For this post, you can use the file create-dbuser-dms-rds-oracle.sql. In this example, the sports user already exists, so the script just grants the privileges. If you use a different user other than sports in this example, make the same changes in the AWS DMS Oracle source endpoint.
{kind=link}
Migrate the Oracle GUID type to UUID type on PostgreSQL
When migrating from Oracle to PostgreSQL, you might need to migrate Oracle GUID to UUID format on PostgreSQL. In Oracle, the SYS_GUID function generates and returns a globally unique identifier (RAW value) made up of 16 bytes (for example, D2F86F59C2C32687E0530100007F0FD4). On most platforms, the generated identifier consists of a host identifier, a process or thread identifier of the process or thread invoking the function, and a non repeating value (sequence of bytes) for that process or thread. The UUID data type stores UUIDs and is written as a sequence of lowercase hexadecimal digits, in several groups separated by hyphens, specifically a group of 8 digits followed by three groups of 4 digits followed by a group of 12 digits, for a total of 32 digits representing the 128 bits (for example, d2f86f59-c2c3-2687-e053-0100007f0fd4).
Method 1: Materialized view with fast a refresh on commit
This approach involves using materialized views to first convert GUID data to UUID format on the Oracle source itself, then using an AWS DMS task to load the data directly from the materialized view to the PostgreSQL target. This method has the advantage of not requiring any additional steps to transform data between AWS DMS and the PostgreSQL target. However, there are some disadvantages: It requires changes to the Oracle source database, and it requires the creation of additional objects within the Oracle source database.
To use this method, complete the following steps:
Create the TEST_TBL_1 table on the Oracle source and insert sample records:
{kind=link}
Create a materialized view log on SPORTS.TEST_TBL_1 (required for fast refresh), create the materialized view SPORTS.TEST_TBL_1_MVW (converting GUID data into UUID format), and enable supplemental logging on the materialized view:
The column T_COL2 is now VARCHAR2 and the values are now in UUID format for migration.
{kind=link}
Enable supplemental logging based on the primary key for the materialized view table SPORTS.TEST_TBL_1_MVW:
{kind=link}
Connect to the PostgreSQL target using the pgs-tgt alias already configured in .bash_profile:
{kind=link}
In order to migrate the data in the column T_COL2 to UUID on the PostgreSQL target, pre-create the target table with column T_COL2 as UUID type
{kind=link}
Next, we start the DMS task sports-ora2pgs-guid-uuid-using-mviews with mapping rules to load from the Oracle materialized view (TEST_TBL_1_MVW) to the PostgreSQL target table (TEST_TABL_1). The task is created with full load and ongoing replication, and TRUNCATE_BEFORE_LOAD for table preparation because we already created the target table.
On the AWS DMS console, start the task sports-ora2pgs-guid-uuid-using-mviews.
{kind=link}
The CloudFormation stack used the following mapping rules when creating the task:
DMS task settings – task-settings.json
DMS table-mapping – table-mapping-guid-uuid-using-mviews.json
See the following code:
In this scenario we only need to convert the name of the source Materialized View (TEST_TBL_1_VW) to the corresponding target table (test_tbl_1). That’s what the following code highlighted in red does.
Connect to the PostgreSQL target and check if the first two records were loaded by the AWS DMS task:
{kind=link}
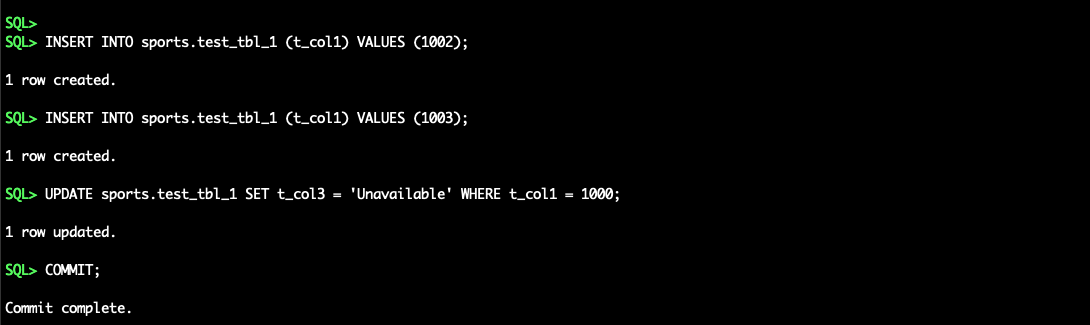
You can now test the replication by running some inserts, updates, or deletes into SPORTS.TEST_TBL_1 in Oracle source database:
{kind=link}
Check if the materialized view is also updated:
{kind=link}
Check the PostgreSQL target if the AWS DMS task successfully replicated these changes in the source to the target table on PostgreSQL:
{kind=link}
In summary, this approach has the advantage of not requiring additional steps to transform data between AWS DMS and the PostgreSQL target. However, it requires changes to the Oracle source database and the creation of additional objects within the Oracle source database.
Method 2: Expressions in AWS DMS table mapping rules
This approach involves using SQLite functions in the AWS DMS task table mapping rules to transform the GUID data loaded from Oracle to UUID format before inserting it into the PostgreSQL target table.
The advantage of this method is that no new objects are needed on the Oracle source database to transform the data between AWS DMS and the PostgreSQL target. It requires familiarity with SQLite functions. Additionally, as of this writing, it requires additional post-migration steps on the PostgreSQL target.
To use this method, complete the following steps:
Create the TEST_TBL_2 table on the Oracle source and insert sample records:
{kind=link}
Enable supplemental logging for the table TEST_TBL_2:
{kind=link}
Next, we create the table on the target PostgreSQL with UUID data type. As of this writing, AWS DMS doesn’t support the update-column action, so for this post we use a two-step approach. First, we use the add-column action to add a new column T_COL2_TMP. We then use T_COL2_TMP in the table mapping rules to store the UUID formatted value. When migration is complete, we then drop the original T_COL2 and rename T_COL2_TMP to T_COL2.
Connect to the target RDS for PostgreSQL instance using the alias pgs-tgt already configured in .bash_profile:
Create the target table. For this post, we add column T_COL2_TMP, which stores the converted UUID values from the Oracle source columns T_COL2:
{kind=link}
{kind=link}
The CloudFormation stack already created the AWS DMS task sports-ora2pgs-guid-uuid-using-expression. AWS DMS supports expressions, which means using SQLite operators or functions to define the data in a column. In rule-id 2, we use the SQLite substring (SUBSTR), hexadecimal function (HEX), and lowercase (LOWER) functions to break the GUID data into several groups separated by hyphens, specifically a group of 8 digits followed by three groups of 4 digits followed by a group of 12 digits, for a total of 32 digits representing the 128 bits.
The CloudFormation stack used the following mapping rules when creating the task:
DMS task settings – task-settings.json
DMS table-mapping – table-mapping-guid-uuid-using-expression.json.
Create the rules with the following code:
On the AWS DMS console, start the task sports-ora2pgs-guid-uuid-using-expression.
Check the PostgreSQL target to confirm the first three records were loaded by the AWS DMS task.
{kind=link}
The original T_COL2 is loaded as BYTEA, which is the AWS DMS default mapping (Oracle RAW data type is mapped to BYTEA on PostgreSQL). However, column T_COL2_TMP is loaded with UUID format based on the expression used in the table mapping rule-id 2.
{kind=link}
You can now test the replication by running some inserts, updates, or deletes into SPORTS.TEST_TBL_2 in the Oracle source database:
{kind=link}
Check the PostgreSQL target to confirm the data is replicated:
{kind=link}
As part of the cutover strategy or when migration is completed, stop the AWS DMS task sports-ora2pgs-guid-uuid-using-expression via the AWS DMS console.
On the PostgreSQL target, after the AWS DMS task is stopped, you can drop T_COL2 and rename T_COL2_TMP back to T_COL2:
{kind=link}
{kind=link}
In the future, when AWS DMS supports update-column, we can update existing columns without using add-column as a workaround option.
Clean up resources
Stop AWS DMS tasks and clean up by deleting the stack to avoid ongoing charges.
Stop the AWS DMS tasks after testing
Delete CloudFormation stack
{kind=link}
{kind=link}
Conclusion
In this post, we showed how you can use Oracle’s materialized views and AWS DMS transformations with SQLite functions to transform GUID data to UUID data type in PostgreSQL. You can adapt the solution in this post for other data type transformations when using AWS DMS for data migration in general.
If you have any comments or questions on this post, please share them in the comments.
About the Authors
Eli Doe is a Migration Specialist SA with Amazon Web Services. He works with customers and partners providing technical assistance and designing customer solutions on cloud migration projects, helping customers migrate and modernize their existing databases to the AWS Cloud.
{kind=link}
Suvendu Kumar Patra is a Senior Data Architect with Amazon Web Services. He helps customers with their data strategy and migration journey, leveraging his years of industry and cloud experience.
{kind=link}
Read MoreAWS Database Blog