
{kind=link}
Last Updated on September 20, 2022
Before the introduction of the Transformer model, the use of attention for neural machine translation was being implemented by RNN-based encoder-decoder architectures. The Transformer model revolutionized the implementation of attention by dispensing of recurrence and convolutions and, alternatively, relying solely on a self-attention mechanism.
We will first be focusing on the Transformer attention mechanism in this tutorial, and subsequently reviewing the Transformer model in a separate one.
In this tutorial, you will discover the Transformer attention mechanism for neural machine translation.
After completing this tutorial, you will know:
How the Transformer attention differed from its predecessors.
How the Transformer computes a scaled-dot product attention.
How the Transformer computes multi-head attention.
Let’s get started.
{kind=link}
The Transformer Attention Mechanism
Photo by Andreas Gücklhorn, some rights reserved.
Tutorial Overview
This tutorial is divided into two parts; they are:
Introduction to the Transformer Attention
The Transformer Attention
Scaled-Dot Product Attention
Multi-Head Attention
Prerequisites
For this tutorial, we assume that you are already familiar with:
The concept of attention
The attention mechanism
The Bahdanau attention mechanism
The Luong attention mechanism
Introduction to the Transformer Attention
We have, thus far, familiarised ourselves with the use of an attention mechanism in conjunction with an RNN-based encoder-decoder architecture. We have seen that two of the most popular models that implement attention in this manner have been those proposed by Bahdanau et al. (2014) and Luong et al. (2015).
The Transformer architecture revolutionized the use of attention by dispensing of recurrence and convolutions, on which the formers had extensively relied.
… the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.
– Attention Is All You Need, 2017.
In their paper, Attention Is All You Need, Vaswani et al. (2017) explain that the Transformer model, alternatively, relies solely on the use of self-attention, where the representation of a sequence (or sentence) is computed by relating different words in the same sequence.
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
– Attention Is All You Need, 2017.
The Transformer Attention
The main components in use by the Transformer attention are the following:
$mathbf{q}$ and $mathbf{k}$ denoting vectors of dimension, $d_k$, containing the queries and keys, respectively.
$mathbf{v}$ denoting a vector of dimension, $d_v$, containing the values.
$mathbf{Q}$, $mathbf{K}$ and $mathbf{V}$ denoting matrices packing together sets of queries, keys and values, respectively.
$mathbf{W}^Q$, $mathbf{W}^K$ and $mathbf{W}^V$ denoting projection matrices that are used in generating different subspace representations of the query, key and value matrices.
$mathbf{W}^O$ denoting a projection matrix for the multi-head output.
In essence, the attention function can be considered as a mapping between a query and a set of key-value pairs, to an output.
The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
– Attention Is All You Need, 2017.
Vaswani et al. propose a scaled dot-product attention, and then build on it to propose multi-head attention. Within the context of neural machine translation, the query, keys and values that are used as inputs to the these attention mechanisms, are different projections of the same input sentence.
Intuitively, therefore, the proposed attention mechanisms implement self-attention by capturing the relationships between the different elements (in this case, the words) of the same sentence.
Scaled Dot-Product Attention
The Transformer implements a scaled dot-product attention, which follows the procedure of the general attention mechanism that we had previously seen.
As the name suggests, the scaled dot-product attention first computes a dot product for each query, $mathbf{q}$, with all of the keys, $mathbf{k}$. It, subsequently, divides each result by $sqrt{d_k}$ and proceeds to apply a softmax function. In doing so, it obtains the weights that are used to scale the values, $mathbf{v}$.
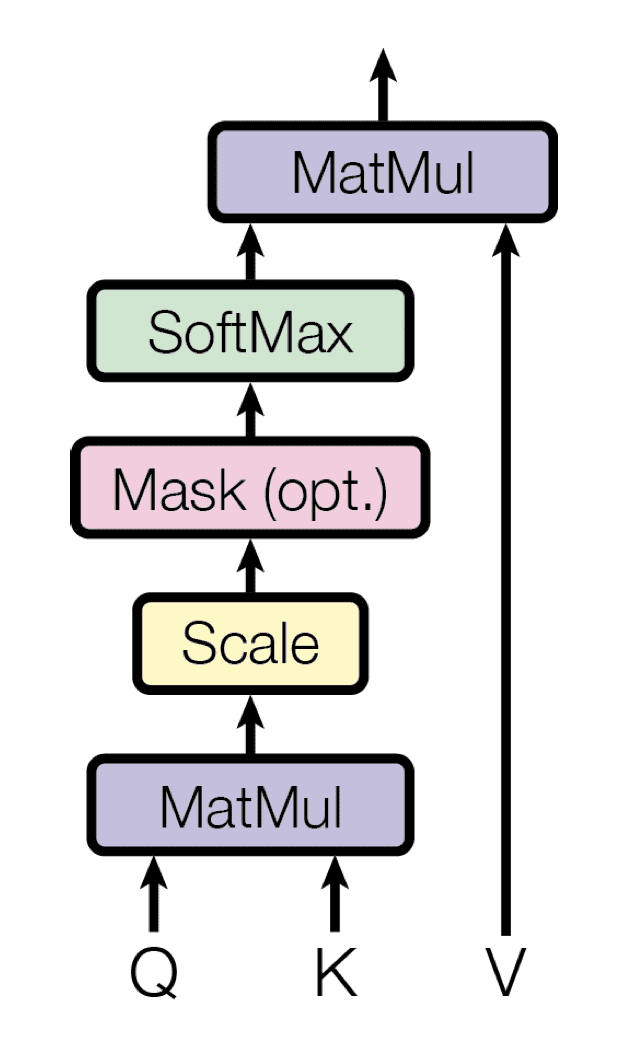{kind=link}
Scaled Dot-Product Attention
Taken from “Attention Is All You Need“
In practice, the computations performed by the scaled dot-product attention can be efficiently applied on the entire set of queries simultaneously. In order to do so, the matrices, $mathbf{Q}$, $mathbf{K}$ and $mathbf{V}$, are supplied as inputs to the attention function:
$$text{attention}(mathbf{Q}, mathbf{K}, mathbf{V}) = text{softmax} left( frac{QK^T}{sqrt{d_k}} right) V$$
Vaswani et al. explain that their scaled dot-product attention is identical to the multiplicative attention of Luong et al. (2015), except for the added scaling factor of $tfrac{1}{sqrt{d_k}}$.
This scaling factor was introduced to counteract the effect of having the dot products grow large in magnitude for large values of $d_k$, where the application of the softmax function would then return extremely small gradients that would lead to the infamous vanishing gradients problem. The scaling factor, therefore, serves to pull the results generated by the dot product multiplication down, hence preventing this problem.
Vaswani et al. further explain that their choice of opting for multiplicative attention instead of the additive attention of Bahdanau et al. (2014), was based on the computational efficiency associated with the former.
… dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
– Attention Is All You Need, 2017.
The step-by-step procedure for computing the scaled-dot product attention is, therefore, the following:
Compute the alignment scores by multiplying the set of queries packed in matrix, $mathbf{Q}$,with the keys in matrix, $mathbf{K}$. If matrix, $mathbf{Q}$, is of size $m times d_k$ and matrix, $mathbf{K}$, is of size, $n times d_k$, then the resulting matrix will be of size $m times n$:
$$
mathbf{QK}^T =
begin{bmatrix}
e_{11} & e_{12} & dots & e_{1n} \
e_{21} & e_{22} & dots & e_{2n} \
vdots & vdots & ddots & vdots \
e_{m1} & e_{m2} & dots & e_{mn} \
end{bmatrix}
$$
Scale each of the alignment scores by $tfrac{1}{sqrt{d_k}}$:
$$
frac{mathbf{QK}^T}{sqrt{d_k}} =
begin{bmatrix}
tfrac{e_{11}}{sqrt{d_k}} & tfrac{e_{12}}{sqrt{d_k}} & dots & tfrac{e_{1n}}{sqrt{d_k}} \
tfrac{e_{21}}{sqrt{d_k}} & tfrac{e_{22}}{sqrt{d_k}} & dots & tfrac{e_{2n}}{sqrt{d_k}} \
vdots & vdots & ddots & vdots \
tfrac{e_{m1}}{sqrt{d_k}} & tfrac{e_{m2}}{sqrt{d_k}} & dots & tfrac{e_{mn}}{sqrt{d_k}} \
end{bmatrix}
$$
And follow the scaling process by applying a softmax operation in order to obtain a set of weights:
$$
text{softmax} left( frac{mathbf{QK}^T}{sqrt{d_k}} right) =
begin{bmatrix}
text{softmax} ( tfrac{e_{11}}{sqrt{d_k}} & tfrac{e_{12}}{sqrt{d_k}} & dots & tfrac{e_{1n}}{sqrt{d_k}} ) \
text{softmax} ( tfrac{e_{21}}{sqrt{d_k}} & tfrac{e_{22}}{sqrt{d_k}} & dots & tfrac{e_{2n}}{sqrt{d_k}} ) \
vdots & vdots & ddots & vdots \
text{softmax} ( tfrac{e_{m1}}{sqrt{d_k}} & tfrac{e_{m2}}{sqrt{d_k}} & dots & tfrac{e_{mn}}{sqrt{d_k}} ) \
end{bmatrix}
$$
Finally, apply the resulting weights to the values in matrix, $mathbf{V}$, of size, $n times d_v$:
$$
begin{aligned}
& text{softmax} left( frac{mathbf{QK}^T}{sqrt{d_k}} right) cdot mathbf{V} \
=&
begin{bmatrix}
text{softmax} ( tfrac{e_{11}}{sqrt{d_k}} & tfrac{e_{12}}{sqrt{d_k}} & dots & tfrac{e_{1n}}{sqrt{d_k}} ) \
text{softmax} ( tfrac{e_{21}}{sqrt{d_k}} & tfrac{e_{22}}{sqrt{d_k}} & dots & tfrac{e_{2n}}{sqrt{d_k}} ) \
vdots & vdots & ddots & vdots \
text{softmax} ( tfrac{e_{m1}}{sqrt{d_k}} & tfrac{e_{m2}}{sqrt{d_k}} & dots & tfrac{e_{mn}}{sqrt{d_k}} ) \
end{bmatrix}
cdot
begin{bmatrix}
v_{11} & v_{12} & dots & v_{1d_v} \
v_{21} & v_{22} & dots & v_{2d_v} \
vdots & vdots & ddots & vdots \
v_{n1} & v_{n2} & dots & v_{nd_v} \
end{bmatrix}
end{aligned}
$$
Multi-Head Attention
Building on their single attention function that takes matrices, $mathbf{Q}$, $mathbf{K}$, and $mathbf{V}$, as input, as we have just reviewed, Vaswani et al. also propose a multi-head attention mechanism.
Their multi-head attention mechanism linearly projects the queries, keys and values $h$ times, each time using a different learned projection. The single attention mechanism is then applied to each of these $h$ projections in parallel, to produce $h$ outputs, which in turn are concatenated and projected again to produce a final result.
{kind=link}
Multi-Head Attention
Taken from “Attention Is All You Need“
The idea behind multi-head attention is to allow the attention function to extract information from different representation subspaces, which would, otherwise, not be possible with a single attention head.
The multi-head attention function can be represented as follows:
$$text{multihead}(mathbf{Q}, mathbf{K}, mathbf{V}) = text{concat}(text{head}_1, dots, text{head}_h) mathbf{W}^O$$
Here, each $text{head}_i$, $i = 1, dots, h$, implements a single attention function characterized by its own learned projection matrices:
$$text{head}_i = text{attention}(mathbf{QW}^Q_i, mathbf{KW}^K_i, mathbf{VW}^V_i)$$
The step-by-step procedure for computing multi-head attention is, therefore, the following:
Compute the linearly projected versions of the queries, keys and values through a multiplication with the respective weight matrices, $mathbf{W}^Q_i$, $mathbf{W}^K_i$ and $mathbf{W}^V_i$, one for each $text{head}_i$.
Apply the single attention function for each head by (1) multiplying the queries and keys matrices, (2) applying the scaling and softmax operations, and (3) weighting the values matrix, to generate an output for each head.
Concatenate the outputs of the heads, $text{head}_i$, $i = 1, dots, h$.
Apply a linear projection to the concatenated output through a multiplication with the weight matrix, $mathbf{W}^O$, to generate the final result.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
Advanced Deep Learning with Python, 2019.
Papers
Attention Is All You Need, 2017.
Neural Machine Translation by Jointly Learning to Align and Translate, 2014.
Effective Approaches to Attention-based Neural Machine Translation, 2015.
Summary
In this tutorial, you discovered the Transformer attention mechanism for neural machine translation.
Specifically, you learned:
How the Transformer attention differed from its predecessors.
How the Transformer computes a scaled-dot product attention.
How the Transformer computes multi-head attention.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post The Transformer Attention Mechanism appeared first on Machine Learning Mastery.
Read MoreMachine Learning Mastery