

{kind=link}
Do you want to monitor your business metrics and detect anomalies in your existing streaming data pipelines? Amazon Lookout for Metrics is a service that uses machine learning (ML) to detect anomalies in your time series data. The service goes beyond simple anomaly detection. It allows developers to set up autonomous monitoring for important metrics to detect anomalies and identify their root cause in a matter of few clicks, using the same technology used by Amazon internally to detect anomalies in its metrics—all with no ML experience required. However, one limitation you may face if you have an existing Amazon Kinesis Data Streams data pipeline is not being able to directly run anomaly detection on your data streams using Lookout for Metrics. As of this writing, Lookout for Metrics doesn’t have native integration with Kinesis Data Streams to ingest streaming data and run anomaly detection on it.
In this post, we show you how to solve this problem by using an AWS Glue Spark streaming extract, transform, and load (ETL) script to ingest and organize streaming data in Amazon Simple Storage Service (Amazon S3) and using a Lookout for Metrics live detector to detect anomalies. If you have an existing Kinesis Data Streams pipeline that ingests ecommerce data, for example, you can use the solution to detect anomalies such as unexpected dips in revenue, high rates of abandoned shopping carts, increases in new user signups, and many more.
Included in this post is a sample streaming data generator to help you get started quickly. The included GitHub repo provides step-by-step deployment instructions, and uses the AWS Cloud Development Kit (AWS CDK) to simplify and automate the deployment.
Lookout for Metrics allows users to set up anomaly detectors in both continuous and backtest modes. Backtesting allows you to detect anomalies on historical data. This feature is helpful when you want to try out the service on past data or validate against known anomalies that occurred in the past. For this post, we use continuous mode, where you can detect anomalies on live data as they occur. In continuous mode, the detector monitors an input S3 bucket for continuous data and runs anomaly detection on new data at specified time intervals. For the live detector to consume continuous time series data from Amazon S3 correctly, it needs to know where to look for data for the current time interval, therefore, it requires continuous input data in S3 buckets organized by time interval.
Overview of solution
The solution architecture consists of the following components:
Streaming data generator – To help you get started quickly, we provide Python code that generates sample time series data and writes to a Kinesis data stream at a specified time interval. The provided code generates sample data for an ecommerce schema (platform, marketplace, event_time, views, revenue). You can also use your own data stream and data, but you must update the downstream processes in the architecture to process your schema.
Kinesis Data Streams to Lookout for Metrics – The AWS Glue Spark streaming ETL code is the core component of the solution. It contains logic to do the following:
Ingest streaming data
Micro-batch data by time interval
Filter dimensions and metrics columns
Deliver filtered data to Amazon S3 grouped by timestamp
Lookout for Metrics continuous detector – The AWS Glue streaming ETL code writes time series data as CSV files to the S3 bucket, with objects organized by time interval. The Lookout for Metrics continuous detector monitors the S3 bucket for live data and runs anomaly detection at the specified time interval (for example, every 5 minutes). You can view the detected anomalies on the Lookout for Metrics dashboard.
The following diagram illustrates the solution architecture.
{kind=link}
AWS Glue Spark streaming ETL script
The main component of the solution is the AWS Glue serverless streaming ETL script. The script contains the logic to ingest the streaming data and write the output, grouped by time interval, to an S3 bucket. This makes it possible for Lookout for Metrics to use streaming data from Kinesis Data Streams to detect anomalies. In this section, we walk through the Spark streaming ETL script used by AWS Glue.
The AWS Glue Spark streaming ETL script performs the following steps:
Read from the AWS Glue table that uses Kinesis Data Streams as the data source.
The following screenshot shows the AWS Glue table created for the ecommerce data schema.
{kind=link}
Ingest the streaming data from the AWS Glue table (table_name parameter) batched by time window (stream_batch_time parameter) and create a data frame for each micro-batch using create_data_frame.from_catalog(), as shown in the following code:
Perform the following processing steps for each batch of data (data frame) ingested:
Select only the required columns and convert the data frame to the AWS Glue native DynamicFrame.
As shown in the preceding example code, select only the columns marketplace, event_time, and views to write to output CSV files in Amazon S3. Lookout for Metrics uses these columns for running anomaly detection. In this example, marketplace is the optional dimension column used for grouping anomalies, views is the metric to be monitored for anomalies, and event_time is the timestamp for time series data.
Populate the time interval in each streaming record ingested:
In the preceding code, we provide the custom function populateTimeInterval, which determines the appropriate time interval for the given data point based on its event_time timestamp column.
The following table includes example time intervals determined by the function for a 5-minute frequency.
Input timestamp
Start of time interval determined by populateTimeInterval function
2021-05-24 19:18:28
2021-05-24 19:15
2021-05-24 19:21:15
2021-05-24 19:20
The following table includes example time intervals determined by the function for a 10-minute frequency.
Input timestamp
Start of time interval determined by populateTimeInterval function
2021-05-24 19:18:28
2021-05-24 19:10
2021-05-24 19:21:15
2021-05-24 19:20
The write_dynamic_frame() function uses the time interval (as determined in the previous step) as the partition key to write output CSV files to the appropriate S3 prefix structure:
For example, the following screenshot shows that the ETL script writes output to the S3 folder structure organized by 5-minute time intervals.
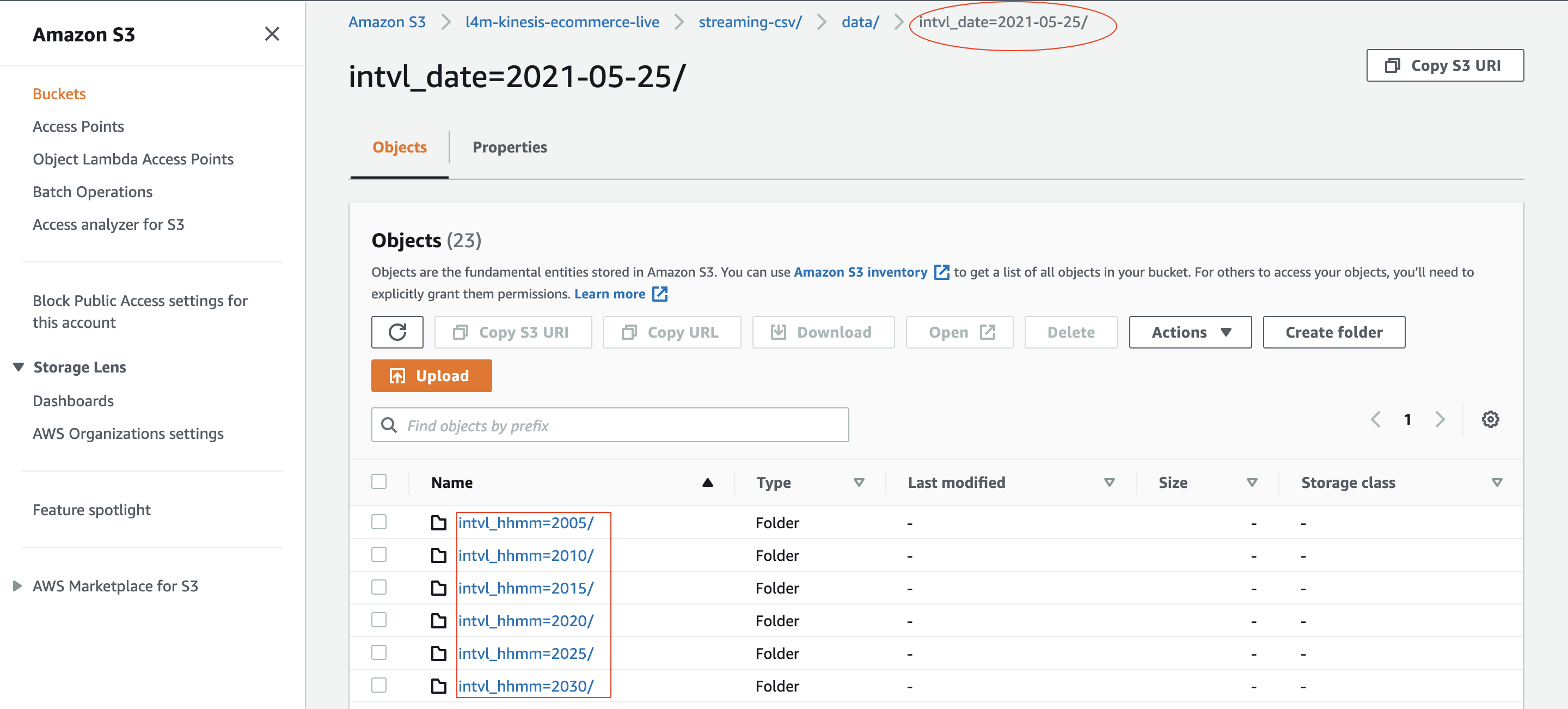{kind=link}
For additional details on partitions for ETL outputs, see Managing Partitions for ETL Output in AWS Glue.
You can set up a live detector using Amazon S3 as a continuous data source to start detecting the anomalies in streaming data. For detailed instructions, see GitHub repo.
Prerequisites
You need the following to deploy the solution:
An AWS account with permissions to deploy the solution using AWS CDK
A workstation or development environment with the following installed and configured:
npm
Typescript
AWS CDK
AWS account credentials
You can find detailed instructions in the “Getting Started” section of the GitHub repo.
Deploy the solution
Follow the step-by-step instructions in the GitHub repo to deploy the solution components. AWS CDK templates are provided for each of the solution components, organized in their own directory structure within the GitHub repo. The templates deploy the following resources:
Data generator – The Lambda function, Amazon EventBridge rule, and Kinesis data stream
Connector for Lookout for Metrics – The AWS Glue Spark streaming ETL job and S3 bucket
Lookout for Metrics continuous detector – Our continuous detector
Clean up
To avoid incurring future charges, delete the resources by deleting the stacks deployed by the AWS CDK.
Conclusion
In this post, we showed how you can detect anomalies in streaming data sources using a Lookout for Metrics continuous detector. The solution used serverless streaming ETL with AWS Glue to prepare the data for Lookout for Metrics anomaly detection. The reference implementation used an ecommerce sample data schema (platform, marketplace, event_time, views, revenue) to demonstrate and test the solution.
You can easily extend the provided data generator code and ETL script to process your own schema and sample data. Additionally, you can adjust the solution parameters such as anomaly detection frequency to match your use case. With minor changes, you can replace the sample data generator with an existing Kinesis Data Streams streaming data source.
To learn more about Amazon Lookout for Metrics, see Introducing Amazon Lookout for Metrics: An anomaly detection service to proactively monitor the health of your business and the Lookout for Metrics Developer Guide. For additional information about streaming ETL jobs with AWS Glue, see Crafting serverless streaming ETL jobs with AWS Glue and Adding Streaming ETL Jobs in AWS Glue.
About the Author
Babu Srinivasan is a Sr. Solutions Architect at AWS, with over 24 years of experience in IT and the last 6 years focused on the AWS Cloud. He is passionate about AI/ML. Outside of work, he enjoys woodworking and entertains friends and family (sometimes strangers) with sleight of hand card magic.
{kind=link}
Read MoreAWS Machine Learning Blog