

{kind=link}
This is a guest post by Lucas Baker, Andrea Duque, and Viet Yen Nguyen of Hypefactors.
At Hypefactors, we build tech for media intelligence and reputation management. The solution is a software as a service (SaaS) product that does large-scale media monitoring of social media, news sites, TV, radio, and reviews across the world. The tracked data is streamed continuously and enriched in real time. This yields insights that can reveal early business opportunities (for example, GameStop hype), track the success of product launches, and preempt disasters.
To this end, over a hundred million network requests are made daily from data pipelines for web crawling, social media firehoses, and other REST-based media data integrations. This yields millions of new articles and posts each day. This data can be segmented into three classes (as illustrated with the following examples):
Owned – Articles or posts written by a company and published on their own website or social media feed.
Paid – Information written by a company and published on third-party websites or social media. This is known colloquially as advertisement.
Earned – Information written by a third party and published on that party’s website or social media.
Owned media
Earned media
Paid media
{kind=link}
{kind=link}
{kind=link}
Differentiating between earned articles and owned or paid ones is of existential importance. Earned information is more independent and therefore interpreted as more trustworthy—no matter if it’s positive or negative for the company. Advertisement, on the other hand, is written by the company and portrays the best interests of the company. Therefore, to accurately track reputation, we must filter out advertisements.
This post goes deeper into our deep learning natural language processing (NLP) based advertisement predictor, how we integrated the predictor into one of our pipelines using Deep Java Library (DJL), and how that change made our architecture simpler and MLOps easier. DJL is an open source Java framework for deep learning created by AWS.
Printed newspapers and magazines: Challenges
We receive thousands of different magazines and newspapers directly from publishing houses in the form of digital files. One of the data teams within Hypefactors has developed a data pipeline, which we call the Print-ETL. The Print-ETL processes the raw data and ingests it into a database. The ingested data is made searchable in a user-friendly way by the Hypefactors web platform.
Processing and realigning data from different data providers is generally challenging. This is also the case with handling different publishing houses as data providers. The challenges are technical, organizational, and a combination thereof. That is partly because media houses are legacy both in their data delivery and data formats.
Organizational challenges include disagreement between different media houses on how media data should be delivered, and the lack of a common schema. A common strategy media houses use is to provide print data via an SFTP server. This can be consumed by periodically connecting and fetching the data. Most of the time we retrieve only the digital PDF files of the editions, but they can also arrive in other formats, such as XML or ZIP. On top of that, files often come with no relevant metadata about the publication. Such metadata is useful, for example, to identify the title of the newspaper or the magazine.
The technical challenges are various. However, when it comes to PDFs, one of the biggest challenges is that a PDF may or may not be vectorized. A vectorized PDF, as opposed to a bitmapped one, is one that contains all the raw data that appears on the page. When a PDF is vectorized, it’s easy to retrieve its text. But when it’s not, all we have are bitmapped images. To make articles searchable for users, the content of a bitmapped PDF needs to be transformed to a text format using optical character recognition (OCR) solutions.
Another big challenge is that PDFs can have any number of pages. Typically, there is no information telling us which pages constitute an article. There can be several articles sharing one PDF page, or several PDF pages containing a single article. Advertisements also appear anywhere—they can cover the whole page, several pages, or just a small section close to an article.
To mitigate these difficulties, we developed elaborate development and operations procedures. These are assisted by automated procedures, such as automated unit and end-to-end testing, as well as automated testing, staging, and production rollouts. Operations therefore play an essential role to keep the overall solution running.
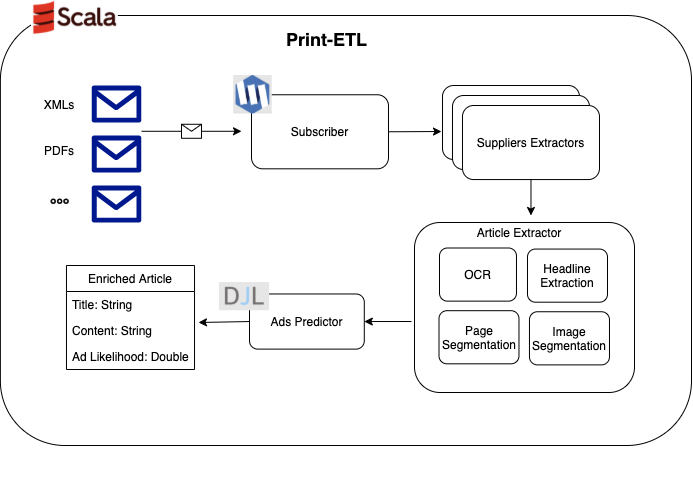
Print-ETL architecture
The data pipeline processes events, in which each event contains a file retrieved from a media house. These events are processed in a distributed and concurrent manner by subscribing to a message topic. We use Monix, a Scala library for asynchronous computation, to process the events with high performance. Ideally, we process data as soon as it arrives, but we don’t have control over when data is released. Therefore, we have periodic peak loads of these events. At other times, there are no events at all. The whole system is deployed in the cloud to make use of its elasticity. Cloud instances are auto scaled proportionally to the number of events received, so naturally the more data we receive, the more resources we use to process that data.
The Print-ETL uses deep learning and other AI techniques to solve most print media challenges and extract the relevant information out of the raw print data. There are several AI and machine learning (ML) models in place. These include computer vision models (for page segmentation) and NLP models (for ad prediction, headline detection, and next sentence prediction).
Today’s practices are that deploying deep learning models incurs complexity by itself. Correspondingly, new practices come into the spotlight for managing the ML lifecycle in production reliably and efficiently—the emerging field of MLOps. In our use case, we use Deep Java Library (DJL) to integrate ML models into our data pipelines written in Scala. We found that this strategy simplifies model deployment and maintenance alike. In this post, we focus on the model we use to filter paid advertisements: the ad predictor.
The following diagram illustrates the Print-ETL architecture.
{kind=link}
First version ad predictor: Serverless inference
We approached the advertisement classification challenge as a supervised binary text classification problem. We fine-tuned a BERT (Bidirectional Encoder Representations from Transformers) pre-trained multilingual base model with a binary classification layer on top of the transformer output. For training, we used a custom-built dataset containing advertisement data that we collected. The input of the model is a sequence of tokens, and the output is a classification score from 0–1, which is the probability of being an ad. This score is calculated by applying a sigmoid function to the linear layer prediction outputs (logits).
On our first iteration, we deployed a standalone ad predictor endpoint on an external service. This made operations harder. Predictions had a higher latency because of network calls and boot up times, causing timeouts and issues resulting from predictor unavailability due to instance interruptions. We also had to auto scale both the data pipeline and the prediction service, which was non-trivial given the unpredictable load of events. However, this strategy also had a few benefits. The service was packaged separately as an API and developed in Python, a language more familiar to data scientists than Scala. Also, the predictor wasn’t integrated into the Print-ETL system, so it wasn’t necessary to be familiar with the system to maintain the predictor.
The following diagram illustrates our BERT model for text classification.
{kind=link}
The following is an example of our ads data.
{kind=link}
Second version with DJL
Our solution to these challenges centered on combining the benefits of two frameworks: Open Neural Network Exchange (ONNX) and Deep Java Library.
With ONNX and DJL, we deployed a new multilingual ad predictor model directly in our pipeline. This replaced our first solution, the serverless ad predictor. The new model was fine-tuned on a new, larger set of data that contained over 450,000 sentences in Danish, English, and Portuguese. They reflect a sample of the production data being processed at the moment.
When deploying the model, DJL enabled us to adopt an API-free strategy. This strategy improved our data processing in myriad ways. For instance, it helped us achieve our latency requirements and use ML inferences in real time. Also, by replacing our standalone ad predictor, we no longer needed to mock an external service API in our tests. That allowed us to simplify our test suite. This in turn led to more test stability. Following our successful deployment, DJL allowed us to integrate other ML models that improved data processing even further.
Let’s go into the details of ONNX and DJL.
ONNX
ONNX is an open-source ecosystem of AI and ML tools designed to provide extensive interoperability between different deep learning frameworks. It manages models from different languages and environments. Their tools and common file format enable us to train a model using one framework, dynamically quantize it using tools from another, and deploy that model using yet another framework. That increased interoperability, along with help from DJL, allowed us to easily integrate our model with the JVM—and consequently our Scala pipeline as well.
More specifically, we used a tool called ONNX Runtime. We converted our original PyTorch model to the standard ONNX file format, and then applied dynamic quantization techniques using ONNX Runtime. This shrunk our original model size by about a factor of four with little to no loss in model performance. It also gave our model a speed boost on CPU-based inferences. In particular, from prior rollouts we had simple, yet cost-effective performance with 8 bits quantization when running a CPU with AVX-512 instructions. We were confident that this strategy would give us the results we were looking for.
Deep Java Library
DJL presented the other half of our solution. DJL is an open-source library that defines a Java-based deep learning framework. DJL abstracts away complexities involved with deep learning deployments, making training and inference a breeze. It’s engine agnostic, and is therefore compatible with a wide variety of deep learning engines. Those engines include PyTorch, TensorFlow, and MXNet, among others. Most importantly for us, DJL supports the ONNX Runtime engine.
Our DJL-based deployment brought several advantages over our original ad predictor deployment. First and foremost, from an engineering perspective, it was simpler. The direct native integration of ad prediction with our Scala data pipeline streamlined our architecture considerably. It allowed us to avoid the computational overhead of serializing and deserializing data, as well as the latency of making network calls to an external service.
Additionally, this meant that there was no longer any need for complicated autoscaling of an external service—the pipeline’s existing autoscaling infrastructure was sufficient to meet all our data processing requirements. Moreover, DJL’s predictor architecture worked well with Monix’s concurrent data processing, allowing us to make multiple inferences simultaneously across different threads.
Those simplifications led us to eliminate our standalone ad predictor service entirely. This eliminated all operational costs associated with running and maintaining that service.
Another consequence of those simplifications was the further streamlining of our test suite. For example, we no longer needed to mock our ad predictor. We could instead directly ensure the correctness and performance of our model on every commit using our continuous integration (CI). Upon every new commit pushed to the Print-ETL, our CI would run our suite of tests, which included tests for the DJL-based ad predictor. This maintains our confidence that our deep learning model works properly whenever we change our code base.
The following screenshot is a snippet of our ad detection CI in action.
{kind=link}
Our testing strategy is now twofold: first, we use tests to determine the validity of our ad predictor model’s output; namely, the model should detect the same ads with the same, or higher, level of accuracy as previous iterations of the model. Second, the model’s robustness is stressed by passing particularly long, short, strange, or fragmented text samples. End-to-end performance tests that take advantage of the ad predictor’s services add a second layer of accountability. This makes sure that current and future deployments of our ad predictor function as intended. If the ad predictor isn’t performing as expected, our tests immediately reflect that incapability. The following code is an example of some sample test cases:
This, in turn, simplified our operations strategy as well. It’s now easier to spot, track, and reproduce inference errors if and when they occur. Such an error immediately tells us which input the model failed to predict on, the exact error message given by ONNX Runtime, along with relevant information for reproducing the error. Also, because our ad predictor is now integrated with our data pipeline, we only need to consult one log stream when analyzing error messages. After the associated bug is reproduced and fixed, we can add a new test case to ensure the same bug doesn’t occur again.
Conclusion and next steps
We have been happy with our DJL-based deployment. Our success with DJL has empowered us to utilize the same strategy to deploy other deep learning models for other purposes, such as headline detection and next sentence prediction. In each of those cases, we experienced similar results as with our ad predictor—deployment was easy, simple, and economical.
In the future, one avenue we would be excited to explore with DJL is GPU-based inference. Our current DJL deployments are exclusively CPU based—partially due to its cost-effectiveness, and partially due to its simplicity when compared to a GPU-based alternative. Given our experiences with DJL, however, we believe that DJL could drastically streamline any GPU-based deployment that we pursue. To learn more and get started on DJL, visit the website. You can also visit the GitHub repo, demo repository, examples, Slack channel, and Twitter for more documentation and examples of DJL!
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Authors
Lukas Baker works in the intersection of data engineering and applied machine learning. At Hypefactors, he occasionally builds a data pipeline and designs and trains a model in between.
{kind=link}
Andrea Duque is an all-round engineer and scientist with a history of connecting the dots with MLOps. At Hypefactors, she designs and rollouts ML-heavy data pipelines end-to-end.
{kind=link}
Viet Yen Nguyen is the CTO of Hypefactors and leads the teams on data science, web app development and data engineering. Prior to Hypefactors, he developed technology for designing mission-critical systems, including the European Space Agency.
{kind=link}
Read MoreAWS Machine Learning Blog