

{kind=link}
This post was co-written with Kevin O’Brien, Senior Data Scientist in Careem’s Integrity Team.
Dubai-based Careem became the Middle East’s first unicorn when it was acquired by Uber for $3.1 billion in 2019. A pioneer of the region’s ride-hailing economy, Careem is now expanding its services to include mass transportation, delivery, and payments as an everyday super app.
But its size and popularity—it has around 50 million customer accounts—have also made it a prime target for fraudsters constantly looking for new loopholes to exploit and different ways to hijack genuine accounts.
In this post, we share how Careem detects identity fraud using graph-based deep learning and Amazon Neptune.
The challenge
Due to Careem’s massive popularity, fraudsters are constantly looking for new loopholes to exploit, create identity-faked accounts (first-party fraud), and different ways to hijack genuine accounts—also known as account takeover (third-party fraud). In Careem’s data science and analytics backed Integrity team, they needed more advanced ways to detect and stop losses from fraud that may be damaging to both their revenue and brand reputation. This solution would ideally cover both first- and third-party fraud.
Traditionally, tackling these different kinds of fraudulent activities was a never-ending game of cat and mouse. Careem’s Integrity team would often create rules or machine learning (ML) models for each specific type of fraud, but this was sometimes problematic on two levels:
It only allowed them to identify and block an account after the fraud had been committed and detected, which means the money had already been lost
Fraudsters were quickly able to find a new loophole to exploit once an existing fraud pattern had been detected
As a result, instead of continuously creating overly specific tools to detect very specific fraud patterns, they wanted to build an intelligent system that was almost a blanket detection mechanism over all users, wherever they were performing actions on the platform.
The new approach
Careem needed to be proactive rather than reactive. A smarter and faster way to detect fraudulent activities and stop them before the act was committed was required.
After much experimentation, Careem decided to focus on the identity of users, and came up with a powerful way to outsmart any efforts of identity fraud. They opted to use a graph structure as a way of mapping different aspects and data points of each user’s identity together, and more importantly, characteristics shared across the identities of different users. This would allow them to detect potentially fraudulent patterns in real time across user and account activity.
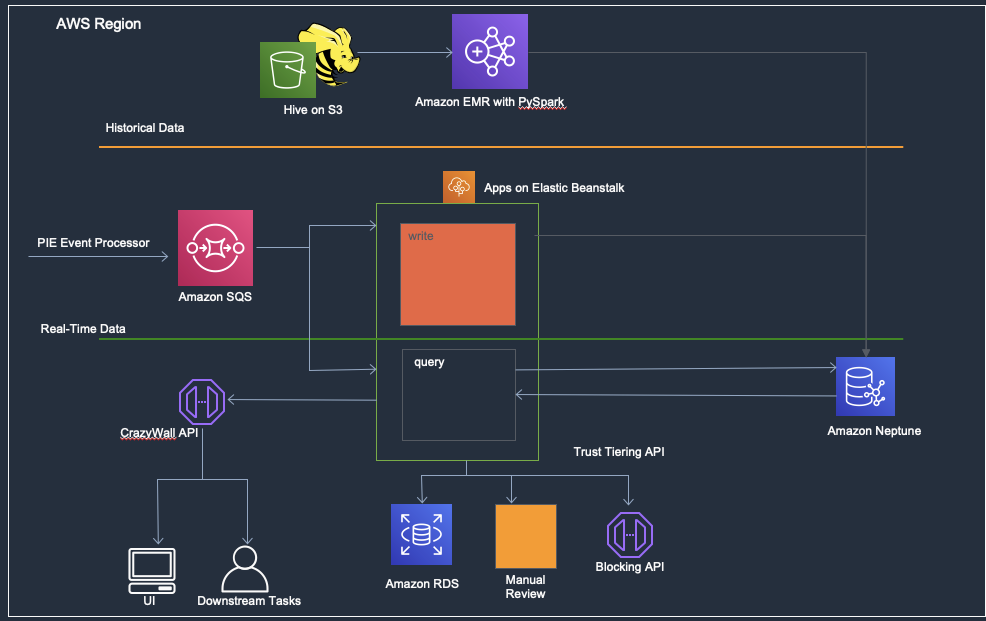
Architecture overview
Before we dive deep into how Careem used Neptune an identity graph for fraud detection, let’s look at the current architecture underpinning the solution. Careem chose AWS and its automated real-time analysis and monitoring capabilities due to the existing integrated cloud setup they already had.
Data ingestion
Data ingestion comprises two stages: a one-time extract, transform, and load (ETL) for all historical data, and a live streaming service of real-time data.
Historical data – Careem uses Apache Hive running on Amazon Simple Storage Service (Amazon S3) to extract data and push it to Amazon EMR with PySpark. Amazon EMR pushes this historical data to Neptune.
Real-time data – Careem uses their existing event processor to feed the data from all actions performed by users through Amazon Simple Queue Service (Amazon SQS). These events are consumed by a Python interface running on AWS Elastic Beanstalk, which takes these events and writes them to Neptune in real time.
Data querying
The data ingested from these sources is then queried, again using the Python interface running on Elastic Beanstalk. A simple set of logical rules is used to process the data returned for a query on a particular user, and a decision is made on whether the action performed was likely to be done by a fraudster. Based on the value of the user’s historical transaction, the fraudulent account is either blocked automatically, if it’s a low-value customer, or sent for manual review, if they’re a high-value customer.
Data consumption
The Integrity team at Careem developed a data consumption API that is used by the other teams at Careem to query users in the graph to retrieve data about their identities.
{kind=link}
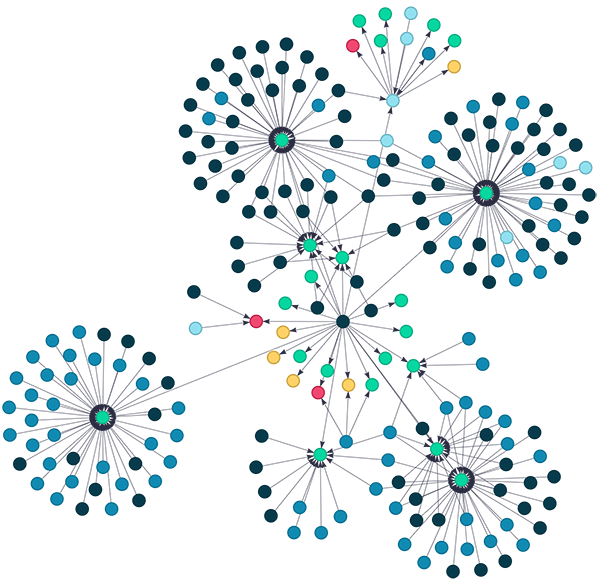
Implementing the graph data model on Neptune
The basic building blocks of any directed graph are vertices (or nodes) and edges. A vertex is an object that represents an entity in your data. For example, a customer can be a node, and the features and information about this customer are called node properties. An edge represents a connection between different nodes. For example, we may have an edge with a label called has_device that connects a customer node to a device node. A large collection of different nodes and edges are called a graph, as illustrated in the following diagram.
{kind=link}
One type of graph architecture is called an identity graph. Identity graphs provide a single unified view of different identities by linking multiple node identifiers such as device IDs, IP addresses, emails, or credit cards to a known person or anonymous profile using privacy-compliant methods. Typically, identity graphs are part of a larger identity resolution architecture. Identity resolution is the process of matching a human identity across a set of devices used by the same person or a household of persons for the purposes of building a representative identity, or known attributes. We can then use this identity graph to find patterns in our data that could indicate fraud activities. We can evaluate identities in the context of other identities or transactions and determine if constellations of data in the graph represent fraudulent activity.
The task we are solving in this case is called node classification. Node classification is a supervised ML approach whereby we predict the categorical feature of a node property. In this case, we decided to build a graph model to predict the is_fraud property of customer nodes using Amazon Neptune ML. Neptune ML is a feature in Neptune that makes it easy to build and train ML models on large graphs using graph neural networks (GNNs). It uses Amazon SageMaker and the Deep Graph Library (DGL) to scale the training and tuning of the graph model.
Data labeling strategy and maturity
In addition to building the graph from different data sources, we needed a robust data labeling and data maturity strategy for the supervised learning task. Data maturity is the process of making sure that the fraud labels have had sufficient time to mature. In other words, enough time has passed to ensure legitimate and fraud records have been correctly and accurately identified. The maturity period can vary depending on the business. For example, for chargeback fraud, it can take somewhere between 30 days and 2 months to accurately identify fraudulent events.
Careem’s customer nodes in the graph were labeled as fraudulent if they had historically been blocked for fraud either manually or by another one of Careem’s automated fraud detection systems that are rule based. These labels are added to the graph either in the historical ETL, for users who are already blocked, or in live streaming, which blocks users in real time. They ensured the maturity of these labels by only using fraud labels for blocked users who hadn’t contacted customer care requesting for their block to be reviewed within a period of time after being blocked.
One issue that arose was that there were many fraudulent accounts that had gone undetected. The volume of these mislabeled customer nodes was substantial enough to affect training performance of the model. To combat this, a strict set of heuristics, based on domain knowledge of the platform, was applied to the customers in the graph, which allowed a large number of these labels to be corrected using a script in the training dataset with high confidence. This allowed more accurate learning of the model due to a reduction in noisy labels.
Collaboration with AWS on Neptune ML
Throughout this project, Careem’s Integrity team worked closely with the AWS ML Specialist and Neptune ML teams to develop this project with maximum efficiency and effectiveness. This included first-hand, on-call support and troubleshooting, as well as working together to build, scale, and optimize our graph.
In addition, Careem has a large volume of properties on the edges in their graph, which were previously not being used in the model’s training and predictions. Careem provided input on the development of a modified version of the RGCN architecture in Neptune ML, which uses edge properties from the graph to learn representations, not just node properties alone, which is what the traditional RGCN model does. Throughout this process, the Neptune ML team also worked on critical features that enabled Careem to train and optimize the graph at scale. These features include multi-GPU training, custom performance metrics, training instance size estimation, scalable and parallel processing, and hyperparameters custom tuning. All of these features are available now in the latest Neptune ML release, which became generally available as of July 2021.
Looking to the future
Careem is currently working with the AWS team to build and train a deep learning model to more accurately detect fraud on their user identity graph. Testing results for the initial phase are looking promising so far, with a precision of around 85% and a recall of over 50%. In other words, the model is able to correctly identify over 50% of all users that have ever historically been blocked for fraud on the platform, with an accuracy of 85%. All of this without knowing anything about the user’s transaction history, bookings, food and grocery orders, and other details—just data about their identity.
Work is now being done to deploy this trained model to production, allowing it to detect fraud in cases such as when a fraudster sets up a new account or compromises the account of an existing genuine user. This will all be done as users perform actions in real time.
In the future, Careem also plans to add Captains (what Careem’s drivers are known as) to the graph to similarly detect fraudulent Captains, or even fraudulent activity produced by collusion between users and Captains. To learn more about Amazon Neptune ML, visit the website.
About the Authors
Kevin O’Brien is a Senior Data Scientist at Careem. He is a member of the Integrity team, whose goal is to detect and prevent fraud on the platform, through data science and analytics. Kevin leads the Identity Risk squad of the Integrity team.
{kind=link}
Waleed (Will) Badr is a Principal AI/ML Specialist Solutions Architect who works as part of the global Amazon Machine Learning team. Will has an extensive experience in fraud detection and prevention systems and is passionate about using technology in innovative ways to positively impact the community.
{kind=link}
Kamran Habib is a Senior Solutions Architect who works with our Digital Native Business (DNB) customers in the Middle East and North Africa (MENA) region. Kamran’s technical expertise focuses on Containers, Networking and Security and he is passionate about solving customer’s business problems with innovative technical solutions. In his spare time, he enjoys travel, listening to podcasts and cricket.
{kind=link}
Read MoreAWS Machine Learning Blog