

{kind=link}
When OpenAI released the third generation of their machine learning (ML) model that specializes in text generation in July 2020, I knew something was different. This model struck a nerve like no one that came before it. Suddenly I heard friends and colleagues, who might be interested in technology but usually don’t care much about the latest advancements in the AI/ML space, talk about it. Even the Guardian wrote an article about it. Or, to be precise, the model wrote the article and the Guardian edited and published it. There was no denying it – GPT-3 was a game changer.
After the model had been released, people immediately started to come up with potential applications for it. Within weeks, many impressive demos were created, which can be found on the GPT-3 website. One particular application that caught my eye was text summarization – the capability of a computer to read a given text and summarize its content. It’s one of the hardest tasks for a computer because it combines two fields within the field of natural language processing (NLP): reading comprehension and text generation. Which is why I was so impressed by the GPT-3 demos for text summarization.
You can give them a try on the Hugging Face Spaces website. My favorite one at the moment is an application that generates summaries of news articles with just the URL of the article as input.
In this two-part series, I propose a practical guide for organizations so you can assess the quality of text summarization models for your domain.
Tutorial overview
Many organizations I work with (charities, companies, NGOs) have huge amounts of texts they need to read and summarize – financial reports or news articles, scientific research papers, patent applications, legal contracts, and more. Naturally, these organizations are interested in automating these tasks with NLP technology. To demonstrate the art of the possible, I often use the text summarization demos, which almost never fail to impress.
But now what?
The challenge for these organizations is that they want to assess text summarization models based on summaries for many, many documents – not one at a time. They don’t want to hire an intern whose only job is to open the application, paste in a document, hit the Summarize button, wait for the output, assess whether the summary is good, and do that all over again for thousands of documents.
I wrote this tutorial with my past self from four weeks ago in mind – it’s the tutorial I wish I had back then when I started on this journey. In that sense, the target audience of this tutorial is someone who is familiar with AI/ML and has used Transformer models before, but is at the beginning of their text summarization journey and wants to dive deeper into it. Because it’s written by a “beginner” and for beginners, I want to stress the fact that this tutorial is a practical guide – not the practical guide. Please treat it as if George E.P. Box had said:
{kind=link}
In terms of how much technical knowledge is required in this tutorial: It does involve some coding in Python, but most of the time we just use the code to call APIs, so no deep coding knowledge is required, either. It’s helpful to be familiar with certain concepts of ML, such as what it means to train and deploy a model, the concepts of training, validation, and test datasets, and so on. Also having dabbled with the Transformers library before might be useful, because we use this library extensively throughout this tutorial. I also include useful links for further reading for these concepts.
Because this tutorial is written by a beginner, I don’t expect NLP experts and advanced deep learning practitioners to get much of this tutorial. At least not from a technical perspective – you might still enjoy the read, though, so please don’t leave just yet! But you will have to be patient with regards to my simplifications – I tried to live by the concept of making everything in this tutorial as simple as possible, but not simpler.
Structure of this tutorial
This series stretches over four sections split into two posts, in which we go through different stages of a text summarization project. In the first post (section 1), we start by introducing a metric for text summarization tasks – a measure of performance that allows us to assess whether a summary is good or bad. We also introduce the dataset we want to summarize and create a baseline using a no-ML model – we use a simple heuristic to generate a summary from a given text. Creating this baseline is a vitally important step in any ML project because it enables us to quantify how much progress we make by using AI going forward. It allows us to answer the question “Is it really worth investing in AI technology?”
In the second post, we use a model that already has been pre-trained to generate summaries (section 2). This is possible with a modern approach in ML called transfer learning. It’s another useful step because we basically take an off-the-shelf model and test it on our dataset. This allows us to create another baseline, which helps us see what happens when we actually train the model on our dataset. The approach is called zero-shot summarization, because the model has had zero exposure to our dataset.
After that, it’s time to use a pre-trained model and train it on our own dataset (section 3). This is also called fine-tuning. It enables the model to learn from the patterns and idiosyncrasies of our data and slowly adapt to it. After we train the model, we use it to create summaries (section 4).
To summarize:
Part 1:
Section 1: Use a no-ML model to establish a baseline
Part 2:
Section 2: Generate summaries with a zero-shot model
Section 3: Train a summarization model
Section 4: Evaluate the trained model
The entire code for this tutorial is available in the following GitHub repo.
What will we have achieved by the end of this tutorial?
By the end of this tutorial, we won’t have a text summarization model that can be used in production. We won’t even have a good summarization model (insert scream emoji here)!
What we will have instead is a starting point for the next phase of the project, which is the experimentation phase. This is where the “science” in data science comes in, because now it’s all about experimenting with different models and different settings to understand whether a good enough summarization model can be trained with the available training data.
And, to be completely transparent, there is a good chance that the conclusion will be that the technology is just not ripe yet and that the project will not be implemented. And you have to prepare your business stakeholders for that possibility. But that’s a topic for another post.
Section 1: Use a no-ML model to establish a baseline
This is the first section of our tutorial on setting up a text summarization project. In this section, we establish a baseline using a very simple model, without actually using ML. This is a very important step in any ML project, because it allows us to understand how much value ML adds over the time of the project and if it’s worth investing in it.
The code for the tutorial can be found in the following GitHub repo.
Data, data, data
Every ML project starts with data! If possible, we always should use data related to what we want to achieve with a text summarization project. For example, if our goal is to summarize patent applications, we should also use patent applications to train the model. A big caveat for an ML project is that the training data usually needs to be labeled. In the context of text summarization, that means we need to provide the text to be summarized as well as the summary (the label). Only by providing both can the model learn what a good summary looks like.
In this tutorial, we use a publicly available dataset, but the steps and code remain exactly the same if we use a custom or private dataset. And again, if you have an objective in mind for your text summarization model and have corresponding data, please use your data instead to get the most out of this.
The data we use is the arXiv dataset, which contains abstracts of arXiv papers as well as their titles. For our purpose, we use the abstract as the text we want to summarize and the title as the reference summary. All the steps of downloading and preprocessing the data are available in the following notebook. We require an AWS Identity and Access Management (IAM) role that permits loading data to and from Amazon Simple Storage Service (Amazon S3) in order to run this notebook successfully. The dataset was developed as part of the paper On the Use of ArXiv as a Dataset and is licensed under the Creative Commons CC0 1.0 Universal Public Domain Dedication.
The data is split into three datasets: training, validation, and test data. If you want to use your own data, make sure this is the case too. The following diagram illustrates how we use the different datasets.
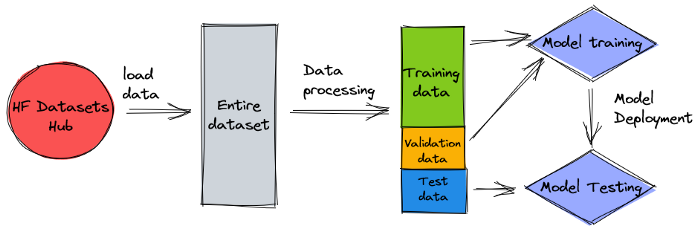{kind=link}
Naturally, a common question at this point is: How much data do we need? As you can probably already guess, the answer is: it depends. It depends on how specialized the domain is (summarizing patent applications is quite different from summarizing news articles), how accurate the model needs to be to be useful, how much the training of the model should cost, and so on. We return to this question at a later point when we actually train the model, but the short of it is that we have to try out different dataset sizes when we’re in the experimentation phase of the project.
What makes a good model?
In many ML projects, it’s rather straightforward to measure a model’s performance. That’s because there is usually little ambiguity around whether the model’s result is correct. The labels in the dataset are often binary (True/False, Yes/No) or categorical. In any case, it’s easy in this scenario to compare the model’s output to the label and mark it as correct or incorrect.
When generating text, this becomes more challenging. The summaries (the labels) we provide in our dataset are only one way to summarize text. But there are many possibilities to summarize a given text. So, even if the model doesn’t match our label 1:1, the output might still be a valid and useful summary. So how do we compare the model’s summary with the one we provide? The metric that is used most often in text summarization to measure the quality of a model is the ROUGE score. To understand the mechanics of this metric, refer to The Ultimate Performance Metric in NLP. In summary, the ROUGE score measures the overlap of n-grams (contiguous sequence of n items) between the model’s summary (candidate summary) and the reference summary (the label we provide in our dataset). But, of course, this is not a perfect measure. To understand its limitations, check out To ROUGE or not to ROUGE?
So, how do we calculate the ROUGE score? There are quite a few Python packages out there to compute this metric. To ensure consistency, we should use the same method throughout our project. Because we will, at a later point in this tutorial, use a training script from the Transformers library instead of writing our own, we can just peek into the source code of the script and copy the code that computes the ROUGE score:
By using this method to compute the score, we ensure that we always compare apples to apples throughout the project.
This function computes several ROUGE scores: rouge1, rouge2, rougeL, and rougeLsum. The “sum” in rougeLsum refers to the fact that this metric is computed over a whole summary, whereas rougeL is computed as the average over individual sentences. So, which ROUGE score we should use for our project? Again, we have to try different approaches in the experimentation phase. For what it’s worth, the original ROUGE paper states that “ROUGE-2 and ROUGE-L worked well in single document summarization tasks” while “ROUGE-1 and ROUGE-L perform great in evaluating short summaries.”
Create the baseline
Next up we want to create the baseline by using a simple, no-ML model. What does that mean? In the field of text summarization, many studies use a very simple approach: they take the first n sentences of the text and declare it the candidate summary. They then compare the candidate summary with the reference summary and compute the ROUGE score. This is a simple yet powerful approach that we can implement in a few lines of code (the entire code for this part is in the following notebook):
We use the test dataset for this evaluation. This makes sense because after we train the model, we also use the same test dataset for the final evaluation. We also try different numbers for n: we start with only the first sentence as the candidate summary, then the first two sentences, and finally the first three sentences.
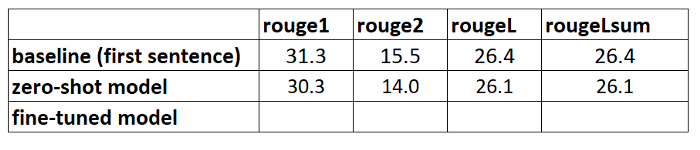
The following screenshot shows the results for our first model.
{kind=link}
The ROUGE scores are highest, with only the first sentence as the candidate summary. This means that taking more than one sentence makes the summary too verbose and leads to a lower score. So that means we will use the scores for the one-sentence summaries as our baseline.
It’s important to note that, for such a simple approach, these numbers are actually quite good, especially for the rouge1 score. To put these numbers in context, we can refer to Pegasus Models, which shows the scores of a state-of-the-art model for different datasets.
Conclusion and what’s next
In Part 1 of our series, we introduced the dataset that we use throughout the summarization project as well as a metric to evaluate summaries. We then created the following baseline with a simple, no-ML model.
{kind=link}
In the next post, we use a zero-shot model – specifically, a model that has been specifically trained for text summarization on public news articles. However, this model won’t be trained at all on our dataset (hence the name “zero-shot”).
I leave it to you as homework to guess on how this zero-shot model will perform compared to our very simple baseline. On the one hand, it will be a much more sophisticated model (it’s actually a neural network). On the other hand, it’s only used to summarize news articles, so it might struggle with the patterns that are inherent to the arXiv dataset.
About the Author
Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning and leads the Natural Language Processing (NLP) community within AWS. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers being successful in their AI/ML journey on AWS and has worked with organizations in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. In his spare time Heiko travels as much as possible.
{kind=link}
Read MoreAWS Machine Learning Blog