

{kind=link}
Last Updated on September 9, 2021
Attention is a concept that is scientifically studied across multiple disciplines, including psychology, neuroscience and, more recently, machine learning. While all disciplines may have produced their own definitions for attention, there is one core quality they can all agree on: attention is a mechanism for making both biological and artificial neural systems more flexible.
In this tutorial, you will discover an overview of the research advances on attention.
After completing this tutorial, you will know:
The concept of attention that is of significance to different scientific disciplines.
How attention is revolutionizing machine learning, specifically in the domains of natural language processing and computer vision.
Let’s get started.
{kind=link}
A Bird’s Eye View of Research on Attention
Photo by Chris Lawton, some rights reserved.
Tutorial Overview
This tutorial is divided into two parts; they are:
The Concept of Attention
Attention in Machine Learning
Attention in Natural Language Processing
Attention in Computer Vision
The Concept of Attention
Research on attention finds its origin in the field of psychology.
The scientific study of attention began in psychology, where careful behavioral experimentation can give rise to precise demonstrations of the tendencies and abilities of attention in different circumstances.
– Attention in Psychology, Neuroscience, and Machine Learning, 2020.
Observations derived from such studies could help researchers infer the mental processes underlying such behavioral patterns.
While the different fields of psychology, neuroscience and, more recently, machine learning, have all produced their own definitions of attention, there is one core quality that is of great significance to all:
Attention is the flexible control of limited computational resources.
– Attention in Psychology, Neuroscience, and Machine Learning, 2020.
With this in mind, the following sections review the role of attention in revolutionizing the field of machine learning.
Attention in Machine Learning
The concept of attention in machine learning is very loosely inspired by the psychological mechanisms of attention in the human brain.
The use of attention mechanisms in artificial neural networks came about — much like the apparent need for attention in the brain — as a means of making neural systems more flexible.
– Attention in Psychology, Neuroscience, and Machine Learning, 2020.
The idea is to be able to work with an artificial neural network that can perform well on tasks where the input may be of variable length, size or structure, or even handle several different tasks. It is in this spirit that attention mechanisms in machine learning are said to inspire themselves from psychology, rather than because they replicate the biology of the human brain.
In the form of attention originally developed for ANNs, attention mechanisms worked within an encoder-decoder framework and in the context of sequence models …
– Attention in Psychology, Neuroscience, and Machine Learning, 2020.
The task of the encoder is to generate a vector representation of the input, whereas the task of the decoder is to transform this vector representation into an output. The attention mechanism connects the two.
There have been different propositions of neural network architectures that implement attention mechanisms, which are also tied to the specific applications in which they find their use. Natural Language Processing (NLP) and computer vision are among the most popular applications.
Attention in Natural Language Processing
An early application for attention in NLP was that of machine translation, where the goal was to translate an input sentence in a source language, to an output sentence in a target language. Within this context, the encoder would generate a set of context vectors, one for each word in the source sentence. The decoder, on the other hand, would read the context vectors to generate an output sentence in the target language, one word at a time.
In the traditional encoder-decoder framework without attention, the encoder produced a fixed-length vector that was independent of the length or features of the input and static during the course of decoding.
– Attention in Psychology, Neuroscience, and Machine Learning, 2020.
Representing the input by a fixed-length vector was especially problematic for long sequences or sequences that were complex in structure, since the dimensionality of their representation was forced to be the same as for shorter or simpler sequences.
For example, in some languages, such as Japanese, the last word might be very important to predict the first word, while translating English to French might be easier as the order of the sentences (how the sentence is organized) is more similar to each other.
– Attention in Psychology, Neuroscience, and Machine Learning, 2020.
This created a bottleneck, whereby the decoder has limited access to the information provided by the input – that which is available within the fixed-length encoding vector. On the other hand, preserving the length of the input sequence during the encoding process, could make it possible for the decoder to utilize its most relevant parts in a flexible manner.
The latter is how the attention mechanism operates.
Attention helps determine which of these vectors should be used to generate the output. Because the output sequence is dynamically generated one element at a time, attention can dynamically highlight different encoded vectors at each time point. This allows the decoder to flexibly utilize the most relevant parts of the input sequence.
– Page 186, Deep Learning Essentials, 2018.
One of the earliest works in machine translation that sought to address the bottleneck problem created by fixed-length vectors, was by Bahdanau et al. (2014). In their work, Bahdanau et al. employed the use of Recurrent Neural Networks (RNNs) for both encoding and decoding tasks: the encoder employs a bi-directional RNN to generate a sequence of annotations that each contain a summary of both preceding and succeeding words, and which can be mapped into a context vector through a weighted sum; the decoder then generates an output based on these annotations and the hidden states of another RNN. Since the context vector is computed by a weighted sum of the annotations, then Bahdanau et al.’s attention mechanism is an example of soft attention.
Another of the earliest works was by Sutskever et al. (2014), who, alternatively, made use of multilayered Long Short-Term Memory (LSTM) to encode a vector representing the input sequence, and another LSTM to decode the vector into a target sequence.
Luong et al. (2015) introduced the idea of global versus local attention. In their work, they described a global attention model as one that, when deriving the context vector, considers all the hidden states of the encoder. The computation of the global context vector is, therefore, based upon a weighted average of all the words in the source sequence. Luong et al. mention that this is computationally expensive, and could potentially make global attention difficult to be applied to long sequences. Local attention is proposed to address this problem, by focusing on a smaller subset of the words in the source sequence, per target word. Luong et al. explain that local attention trades-off the soft and hard attentional models of Xu et al. (2016) (we will refer to this paper again in the next section), by being less computationally expensive than the soft attention, but easier to train than the hard attention.
More recently, Vaswani et al. (2017) proposed an entirely different architecture that has steered the field of machine translation into a new direction. Termed by the name of Transformer, their architecture dispenses of any recurrence and convolutions entirely, but implements a self-attention mechanism. Words in the source sequence are first encoded in parallel to generate key, query and value representations. The keys and queries are combined to generate attention weightings that capture how each word relates to the others in the sequence. These attention weightings are then used to scale the values, in order to retain focus on the important words and drown out the irrelevant ones.
The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
– Attention Is All You Need, 2017.
{kind=link}
At the time, the proposed Transformer architecture established a new state-of-the-art on English-to-German and English-to-French translation tasks, and was reportedly also faster to train than architectures based on recurrent or convolutional layers. Subsequently, the method called BERT by Devlin et al. (2019) built on Vaswani et al.’s work by proposing a multi-layer bi-directional architecture.
As we shall be seeing shortly, the uptake of the Transformer architecture was not only rapid in the domain of NLP, but in the computer vision domain too.
Attention in Computer Vision
In computer vision, attention has found its way into several applications, such as in the domains of image classification, image segmentation and image captioning.
If we had to reframe the encoder-decoder model to the task of image captioning, as an example, then the encoder can be a Convolutional Neural Network (CNN) that captures the salient visual cues in the images into a vector representation, whereas the decoder can be an RNN or LSTM that transforms the vector representation into an output.
Also, as in the neuroscience literature, these attentional processes can be divided into spatial and feature-based attention.
– Attention in Psychology, Neuroscience, and Machine Learning, 2020.
In spatial attention, different spatial locations are attributed different weights, however these same weights are retained across all feature channels at the different spatial locations.
One of the fundamental image captioning approaches working with spatial attention has been proposed by Xu et al. (2016). Their model incorporates a CNN as an encoder that extracts a set of feature vectors (or annotation vectors), with each vector corresponding to a different part of the image to allow the decoder to focus selectively on specific image parts. The decoder is an LSTM that generates a caption based on a context vector, the previous hidden state, and the previously generated words. Xu et al. investigate the use of hard attention as an alternative to soft attention in computing their context vector. Here, soft attention places weights softly on all patches of the source image, whereas hard attention attends to a single patch alone while disregarding the rest. They report that, in their work, hard attention performs better.
{kind=link}
Model for Image Caption Generation
Taken from “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”
Feature attention, in comparison, permits individual feature maps to be attributed their own weight values. One such example, also applied to image captioning, is the encoder-decoder framework of Chen et al. (2018), which incorporates spatial and channel-wise attentions in the same CNN.
Similarly to how the Transformer has quickly become the standard architecture for NLP tasks, it has also been recently taken up and adapted by the computer vision community.
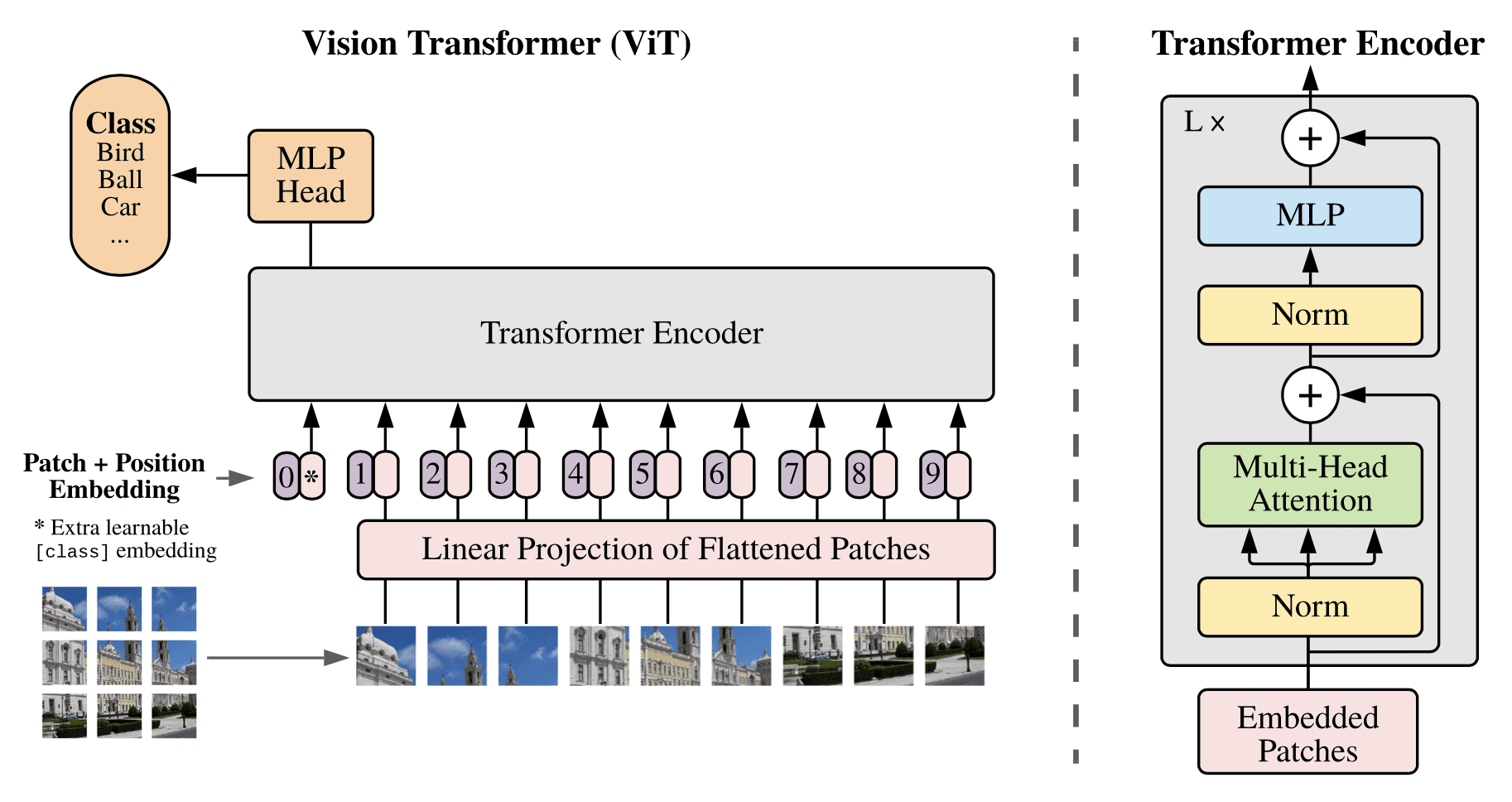
The earliest work to do so was proposed by Dosovitskiy et al. (2020), who applied their Vision Transformer (ViT) to an image classification task. They argued that the long-standing reliance on CNNs for image classification was not necessary, and the same task could be accomplished by a pure transformer. Dosovitskiy et al. reshape an input image into a sequence of flattened 2D image patches, which they subsequently embed by a trainable linear projection to generate the patch embeddings. These patch embeddings together with their position embeddings, to retain positional information, are fed into the encoder part of the Transformer architecture, whose output is subsequently fed into a Multilayer Perceptron (MLP) for classification.
{kind=link}
The Vision Transformer Architecture
Taken from “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”
Inspired by ViT, and the fact that attention-based architectures are an intuitive choice for modelling long-range contextual relationships in video, we develop several transformer-based models for video classification.
– ViViT: A Video Vision Transformer, 2021.
Arnab et al. (2021), subsequently extended the ViT model to ViViT, which exploits the spatiotemporal information contained within videos for the task of video classification. Their method explores different approaches of extracting the spatiotemporal data, such as by sampling and embedding each frame independently, or by extracting non-overlapping tubelets (an image patch that spans across several image frames, creating a tube) and embedding each one in turn. They also investigate different methods of factorising the spatial and temporal dimensions of the input video, for increased efficiency and scalability.
{kind=link}
Further to its first application for image classification, the Vision Transformer is already being applied to several other computer vision domains, such as to action localization, gaze estimation, and image generation. This surge of interest among computer vision practitioners suggests an exciting near future, where we’ll be seeing more adaptations and applications of the Transformer architecture.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
Deep Learning Essentials, 2018.
Papers
Attention in Psychology, Neuroscience, and Machine Learning, 2020.
Neural Machine Translation by Jointly Learning to Align and Translate, 2014.
Sequence to Sequence Learning with Neural Networks, 2014.
Effective Approaches to Attention-based Neural Machine Translation, 2015.
Attention Is All You Need, 2017.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2019.
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, 2016.
SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning, 2018.
An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale, 2020.
ViViT: A Video Vision Transformer, 2021.
Example Applications:
Relation Modeling in Spatio-Temporal Action Localization, 2021.
Gaze Estimation using Transformer, 2021.
ViTGAN: Training GANs with Vision Transformers, 2021.
Summary
In this tutorial, you discovered an overview of the research advances on attention.
Specifically, you learned:
The concept of attention that is of significance to different scientific disciplines.
How attention is revolutionizing machine learning, specifically in the domains of natural language processing and computer vision.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post A Bird’s Eye View of Research on Attention appeared first on Machine Learning Mastery.
Read MoreMachine Learning Mastery