

{kind=link}
Amazon SageMaker is a fully managed service for data science and machine learning (ML) workflows. It helps data scientists and developers prepare, build, train, and deploy high-quality ML models quickly by bringing together a broad set of capabilities purpose-built for ML.
In 2021, AWS announced the integration of NVIDIA Triton Inference Server in SageMaker. You can use NVIDIA Triton Inference Server to serve models for inference in SageMaker. By using an NVIDIA Triton container image, you can easily serve ML models and benefit from the performance optimizations, dynamic batching, and multi-framework support provided by NVIDIA Triton. Triton helps maximize the utilization of GPU and CPU, further lowering the cost of inference.
In some scenarios, users want to deploy multiple models. For example, an application for revising English composition always includes several models, such as BERT for text classification and GECToR to grammar checking. A typical request may flow across multiple models, like data preprocessing, BERT, GECToR, and postprocessing, and they run serially as inference pipelines. If these models are hosted on different instances, the additional network latency between these instances increases the overall latency. For an application with uncertain traffic, deploying multiple models on different instances will inevitably lead to inefficient utilization of resources.
Consider another scenario, in which users develop multiple models with different versions, and each model uses a different training framework. A common practice is to use multiple containers, each of which deploys a model. But this will cause increased workload and costs for development, operation, and maintenance. In this post, we discuss how SageMaker and NVIDIA Triton Inference Server can solve this problem.
Solution overview
Let’s look at how SageMaker inference works. SageMaker invokes the hosting service by running a Docker container. The Docker container launches a RESTful inference server (such as Flask) to serve HTTP requests for inference. The inference server loads the model and listens to port 8080 providing external service. The client application sends a POST request to the SageMaker endpoint, SageMaker passes the request to the container, and returns the inference result from the container to the client.
In our architecture, we use NVIDIA Triton Inference Server, which provides concurrent runs of multiple models from different frameworks, and we use a Flask server to process client-side requests and dispatch these requests to the backend Triton server. While launching a Docker container, the Triton server and Flask server are started automatically. The Triton server loads multiple models and exposes ports 8000, 8001, and 8002 as gRPC, HTTP, and metrics server. The Flask server listens to 8080 ports and parses the original request and payload, and then invokes the local Triton backend via model name and version information. For the client side, it adds the model name and model version in the request in addition to the original payload, so that Flask is able to route the inference request to the correct model on Triton server.
The following diagram illustrates this process.
A complete API call from the client is as follows:
The client assembles the request and initiates the request to a SageMaker endpoint.
The Flask server receives and parses the request, and gets the model name, version, and payload.
The Flask server assembles the request again and routes to the corresponding endpoint of the Triton server according to the model name and version.
The Triton server runs an inference request and sends responses to the Flask server.
The Flask server receives the response message, assembles the message again, and returns it to the client.
The client receives and parses the response, and continues to subsequent business procedures.
In the following sections, we introduce the steps needed to prepare a model and build the TensorRT engine, prepare a Docker image, create a SageMaker endpoint, and verify the result.
Prepare models and build the engine
We demonstrate hosting three typical ML models in our solution: image classification (ResNet50), object detection (YOLOv5), and a natural language processing (NLP) model (BERT-base). NVIDIA Triton Inference Server supports multiple formats, including TensorFlow 1. x and 2. x, TensorFlow SavedModel, TensorFlow GraphDef, TensorRT, ONNX, OpenVINO, and PyTorch TorchScript.
The following table summarizes our model details.
Model Name
Model Size
Format
ResNet50
52M
Tensor RT
YOLOv5
38M
Tensor RT
BERT-base
133M
ONNX RT
NVIDIA provides detailed documentation describing how to generate the TensorRT engine. To achieve best performance, the TensorRT engine must be built over the device. This means the build time and runtime require the same computer capacity. For example, a TensorRT engine built on a g4dn instance can’t be deployed on a g5 instance.
You can generate your own TensorRT engines according to your needs. For test purposes, we prepared sample codes and deployable models with the TensorRT engine. The source code is also available on GitHub.
Next, we use an Amazon Elastic Compute Cloud (Amazon EC2) G4dn instance to generate the TensorRT engine with the following steps. We use YOLOv5 as an example.
Launch a G4dn.2xlarge EC2 instance with the Deep Learning AMI (Ubuntu 20.04) in the us-east-1 Region.
Open a terminal window and use the ssh command to connect to the instance.
Run the following commands one by one:
Create a config.pbtxt file:
Create the following file structure and put the generated files in the appropriate location:
Test the TensorRT engine
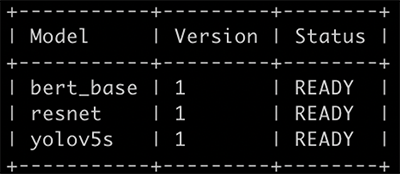
Before we deploy to SageMaker, we start a Triton server to verify these three models are configured correctly. Use the following command to start a Triton server and load the models:
If you receive the following prompt message, it means the Triton server is started correctly.
{kind=link}
Enter nvidia-smi in the terminal to see GPU memory usage.
Client implementation for inference
The file structure is as follows:
serve – The wrapper that starts the inference server. The Python script starts the NGINX, Flask, and Triton server.
predictor.py – The Flask implementation for /ping and /invocations endpoints, and dispatching requests.
wsgi.py – The startup shell for the individual server workers.
base.py – The abstract method definition that each client requires to implement their inference method.
client folder – One folder per client:
resnet
bert_base
yolov5
nginx.conf – The configuration for the NGINX primary server.
We define an abstract method to implement the inference interface, and each client implements this method:
The Triton server exposes an HTTP endpoint on port 8000, a gRPC endpoint on port 8001, and a Prometheus metrics endpoint on port 8002. The following is a sample ResNet client with a gRPC call. You can implement the HTTP interface or gRPC interface according to your use case.
In this architecture, the NGINX, Flask, and Triton servers should be started at the beginning. Edit the serve file and add a line to start the Triton server.
Build a Docker image and push the image to Amazon ECR
The Docker file code looks as follows:
The following table shows the cost for sharing one endpoint for three models using the preceding architecture. The total cost is about $676.8/month. From this result, we can conclude that you can save 30% in costs while also having 24/7 service from your endpoint.
Model Name
Endpoint Running /Day
Instance Type
Cost/Month (us-east-1)
ResNet, YOLOv5, BERT
24 hours
ml.g4dn.2xlarge
0.94 * 24 * 30 = $676.8
Summary
In this post, we introduced an improved architecture in which multiple models share one endpoint in SageMaker. Under some conditions, this solution can help you save costs and improve resource utilization. It is suitable for business scenarios with low concurrency and latency-insensitive requirements.
To learn more about SageMaker and AI/ML solutions, refer to Amazon SageMaker.
References
Use Triton Inference Server with Amazon SageMaker
Achieve low-latency hosting for decision tree-based ML models on NVIDIA Triton Inference Server on Amazon SageMaker
Deploy fast and scalable AI with NVIDIA Triton Inference Server in Amazon SageMaker
NVIDIA Triton Inference Server
YOLOv5
Export to ONNX
amazon-sagemaker-examples/sagemaker-triton GitHub repo
Amazon SageMaker Pricing
About the authors
Zheng Zhang is a Senior Specialist Solutions Architect in AWS, he focuses on helping customers accelerate model training, inference and deployment for machine learning solutions. He also has rich experience in large-scale distributed training, design AI/ML solutions.
{kind=link}
Yinuo He is an AI/ML specialist in AWS. She has experiences in designing and developing machine learning based products to provide better user experiences. She now works to help customers succeed in their ML journey.
{kind=link}
Read MoreAWS Machine Learning Blog