

{kind=link}
Data scientists can spend up to 80% of their time preparing data for machine learning (ML) projects. This preparation process is largely undifferentiated and tedious work, and can involve multiple programming APIs and custom libraries. Announced at AWS re:Invent 2020, Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare data for ML from weeks to minutes. With Data Wrangler, you can simplify the process of data preparation and feature engineering. You can complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization, from a single visual interface. For more information about how to prepare your datasets for ML training, inference, or other use cases, see Introducing Amazon SageMaker Data Wrangler, a Visual Interface to Prepare Data for Machine Learning.
Data Wrangler natively connects data sources such as Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift, and Snowflake. Data Wrangler also integrates to multiple SageMaker features like SageMaker Clarify, Feature Store, and Pipelines. The Data Wrangler UI has been launched as part of SageMaker Studio, which is the primary IDE for SageMaker. You can explore your data within the Data Wrangler UI and create a data flow (.flow file) that defines an exportable series of ML data preparation steps, ready for integration with training and inference ML workflows. After you create a preprocessing flow based on your sample data, you need a way to transfer the pipeline logic into your production workflow to handle incoming data periodically.
This post demonstrates how to schedule your data preparation to run automatically using AWS Lambda and an existing Data Wrangler .flow file. Lambda is a serverless compute service that lets you run your code with the right execution power and zero administration.
Steps required to schedule your Data Wrangler flow to run regularly:
Export your Data Wrangler .flow file as a SageMaker processing script.
Create a Lambda function from the processing script.
Schedule the Lambda function defined in the previous step to run using Amazon EventBridge.
Optionally, you can parameterize the Data Wrangler .flow file based on the modularity required (which we demonstrate in this post).
This post assumes you have an existing .flow file from your processing step using Data Wrangler.
Export your Data Wrangler .flow file
We use an existing .flow file that was generated from two data sources (Amazon S3 and Athena) for demonstration purposes. You can use any existing .flow file to follow along with this post.
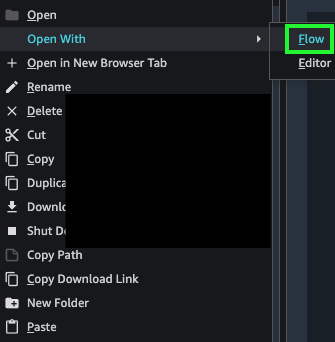
Choose the .flow file (right click).
On the Open With menu, choose Flow.
On the Export tab, choose Save to S3.
{kind=link}
The notebook can run the processing job and save the output to an Amazon S3 location.
{kind=link}
Data Wrangler exports the entire processing steps into a notebook. The notebook can run the processing job and save the output to an Amazon S3 location. To run this processing job on a regular basis, let’s say daily, monthly, or quarterly, we need to set up a Lambda function and schedule it for the required frequency. Lambda lets you run code without provisioning or managing servers.
The first step to prepare the Lambda function is to export the notebook into an executable Python file.
{kind=link}
After we have the Python script, we can modify the script to create a Lambda function.
Open the .py script and remove comments that were automatically generated from the notebook, and rename the script lambda_function.py.
Bring all the import statements at the beginning of the script and add one helper function to the script, lambda_handler().
{kind=link}
This is the main Python function for the Lambda function that is used to schedule the .flow file.
{kind=link}
See the following code:
Wrap the auto-generated code within a function, run_flow().
{kind=link}
This is to call the function we defined in the previous step.
Modify one line where iam_role is defined. We need to find the SageMaker execution role and update iam_role with the ARN for that role.
Add one more line at the end of run_flow() function as the following:
{kind=link}
{kind=link}
See the following code:
Create a Lambda function
Now that we have the required Python script, we can create a Lambda function. For instructions on creating a function using the Python runtime, see Building Lambda functions with Python. For more information about getting started with Lambda, see Run a Serverless “Hello, World!” with AWS Lambda.
The Lambda runtime dependency can be any package, module, or other assembly dependency that isn’t included with the Lambda runtime environment for your function’s code. If your code has a dependency on standard Python math or logging libraries or Boto3, you don’t need to include the libraries in your .zip file. However, some ML-related packages, for example Pandas, NumPy, and SageMaker, need to be packaged within the Lambda .zip file.
Run the following commands to include the SageMaker package within the Lambda .zip file:
Now you can use this .zip file to create a Lambda function.
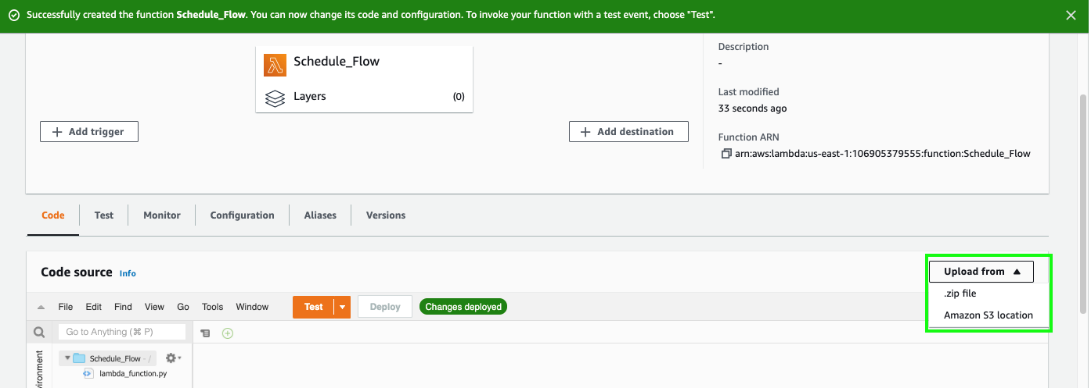
On the Lambda console, create a function with the option Author from scratch.
Upload your .zip file.
{kind=link}
{kind=link}
You can fulfill the requirement for NumPy within the Lambda runtime environment via Lambda layers.
Add a base Python3.8 Scipy1x layer provided by AWS, which can be found via the Lambda function console.
{kind=link}
Schedule your Lambda function using EventBridge
After you create and test your Lambda function, it’s time to schedule your function using EventBridge. EventBridge is a serverless event bus service that makes it easy to connect your applications with data from a variety of sources. For this post, we schedule data to be processed every hour and saved to a specific S3 bucket.
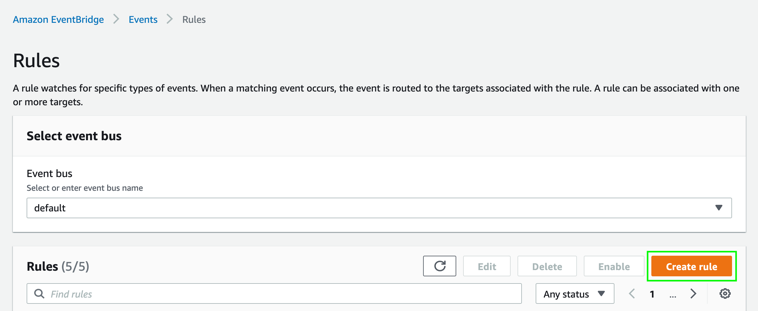
On the Amazon EventBridge console, on the Rules page, choose Create rule.
For Name, enter a name.
For Description, enter an optional description.
For Define pattern, select Schedule.
Set the fixed rate to every 1 hour.
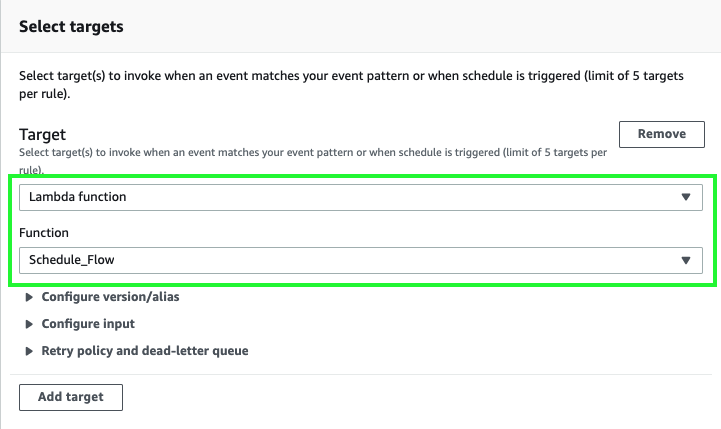
For Target, choose Lambda function.
For Function, choose Schedule_Flow.
{kind=link}
{kind=link}
{kind=link}
Alternatively, we can deploy the Lambda function and schedule using EventBridge with a serverless template file (see the following code). For an example on deploying a serverless template, see Amazon EventBridge Scheduled to AWS Lambda. The required template file and an example lambda_function.py are available on the GitHub repo.
Additional parameterization of the .flow file
Direct export of the .flow file works on the same data source and same query. But you can parameterize the exported script from the .flow file to handle changes in a data source, for example, to point to a different S3 bucket or different file, or change the query to pull incremental data from other data sources. In our preceding example code, we had the following query pull data from an Athena table:
We can easily generate this query string with an additional step using the generate_query() function.
{kind=link}
We can call this generate_query() function within the run_flow() function to create a new query during runtime.
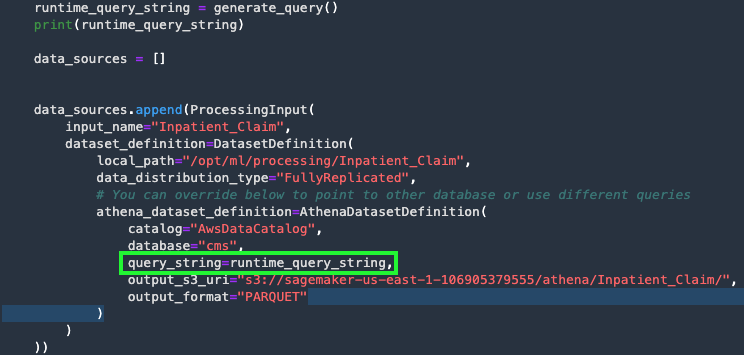{kind=link}
We can also specify the output S3 bucket instead of using the default one, and parameterize the other auto-generated output paths if needed.
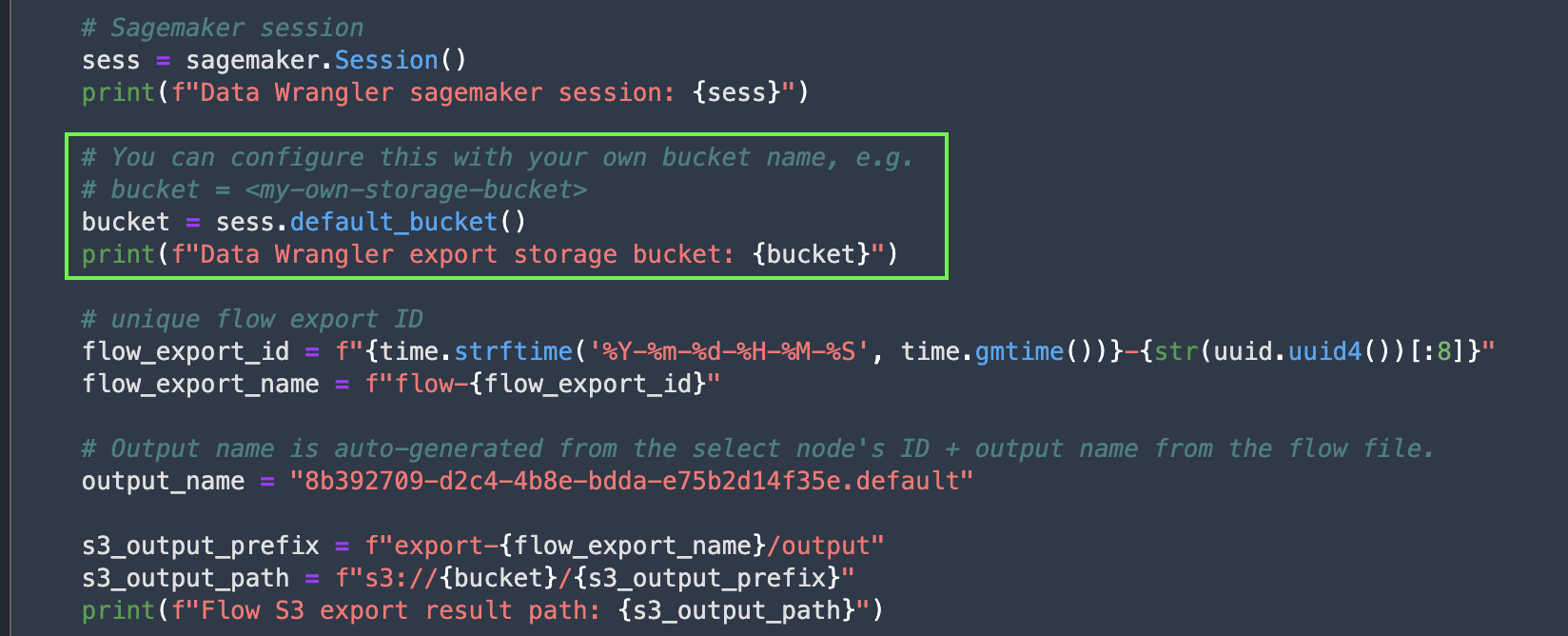{kind=link}
Clean up
When you’re finished, we recommend deleting all the AWS resources created in this demo to avoid additional recurring costs.
Delete the EventBridge rule.
Delete the Lambda function.
Delete the .flow files and output files in the S3 bucket.
Shut down Data Wrangler.
Conclusion
In this post, we demonstrated how to automate a Data Wrangler flow to run on a schedule using a Lambda function with EventBridge. Additionally, we showed how we can parameterize the .flow file for different data sources or make changes in the query using custom functions within the Lambda function script. Most importantly, we showed how to automate an entire ML preprocessing workflow with a limited number of lines (about 10) of code.
To get started with Data Wrangler, see Introducing Amazon SageMaker Data Wrangler, a Visual Interface to Prepare Data for Machine Learning. You can also explore advanced topics like cross-account access for Data Wrangler or connecting to Snowflake as a data source. For the latest information on Data Wrangler, see the product page.
Data Wrangler makes it easy to prepare, process, explore without much experience with scripting languages like Python or Spark. With native connection to Feature Store, Processing, and Pipelines, the end-to-end ML model development and deployment is more user-friendly and intuitive.
Disclaimer
For our ML use case, we used the public data from cms.gov to create our demo .flow file to show an example where real data can come at regular intervals with a similar data model requiring a scheduled preprocessing job.
Citation
Centers for Medicare & Medicaid Services. (2018). 2019 Health Insurance Exchange Public Use Files (Medicare Claims Synthetic Public Use Files) [Data file and code book]. Retrieved from https://www.cms.gov/Research-Statistics-Data-and-Systems/Downloadable-Public-Use-Files/SynPUFs/DE_Syn_PUF
“Medicare Claims Synthetic Public Use Files” is made available under the Open Database License. Any rights in individual contents of the database are licensed under the Database Contents License.
About the Authors
Jayeeta Ghosh is a Data Scientist within ML ProServe, who works on AI/ML projects for AWS customers and helps solve customer business problems across industries using deep learning and cloud expertise.
{kind=link}
Chenyang (Peter) Liu is a Senior Software Engineer on the Amazon SageMaker Data Wrangler team. He is passionate about low-code machine learning systems with state-of-art techniques. In his spare time, he is a foodie and enjoys road trips.
Read MoreAWS Machine Learning Blog