

{kind=link}
Database migrations typically consist of converting the database schema and loading the data from the source database to the target database. After the migration, developers still need to change the application to use the target database drivers, and they often need to rewrite the application code to make it all work. With Babelfish for Aurora PostgreSQL, you can migrate applications from SQL Server with minimum schema changes; Babelfish lets the PostgreSQL engine understand the SQL Server dialect natively. For more information about this feature and Babelfish for Aurora PostgreSQL, see Working with Babelfish for Aurora PostgreSQL.
Babelfish doesn’t support certain SQL Server language features. For this reason, Amazon provides assessment tools to do a line-by-line analysis of your SQL statements and determine if any of them are unsupported by Babelfish.
In this post, we demonstrate how to use the AWS Schema Conversion Tool (AWS SCT) assessment report to provide this analysis. You don’t need to use AWS SCT for schema conversion—Babelfish understands the SQL Server dialect natively. Rather, AWS SCT is only used for building an assessment report.
Babelfish assessment tools
You have two options for assessment tools for Babelfish. One option is the open-source Compass tool. The other option is the assessment report built into AWS SCT. Both tools use the same logic file for evaluation, so choose the tool that you prefer.
Prerequisites
Our use case for this post involves migrating the Northwind database to Babelfish for Aurora PostgreSQL using AWS SCT. Download the DDL and create this sample database in your SQL Server instance which will be used as a source database for this post.
To follow along with this solution, you must install and configure AWS SCT having access to the source SQL Server database. For instructions, refer to Installing AWS SCT.
Create a Babelfish cluster using PostgreSQL version 13.6 or later (and connect to the Babelfish database using SQL Server Management Studio (SSMS) or sqlcmd, refer to Getting started with Babelfish for Aurora PostgreSQL.
Solution overview
This project configuration process includes the following high-level steps:
Configure JDBC drivers in AWS SCT global settings.
Create the source database connection and virtual target.
Map the source schema with the Babelfish virtual target.
Generate an assessment report.
Analyze the assessment report and review action items.
Create the Babelfish cluster.
Create database objects and load the Babelfish database.
Validate the migrated data and test the functionality.
Configure JDBC drivers in AWS SCT global settings
AWS SCT requires JDBC drivers to connect to your source and target databases. To configure the driver path in AWS SCT, complete the following steps:
Download and install JDBC drivers. For a list of supported drivers, refer to Installing the required database drivers.
Navigate to the global settings on the Settings page of the AWS SCT.
Choose Drivers in the navigation pane, and add the file path to the JDBC driver for your source and target database engines. For this post, we add the SQL Server driver.
{kind=link}
Create the source database connection and virtual target
With AWS SCT version 656, a target connection is optional. This version includes a new feature called a virtual target. A virtual target allows you to run assessments without having to create a target database first.
To add the source database connections, complete the following steps:
Start the AWS SCT.
On the File menu, choose New Project.
Enter a name for your project, in this case Babelfish Assessment, which is stored locally on your computer.
Choose OK to create your AWS SCT project.
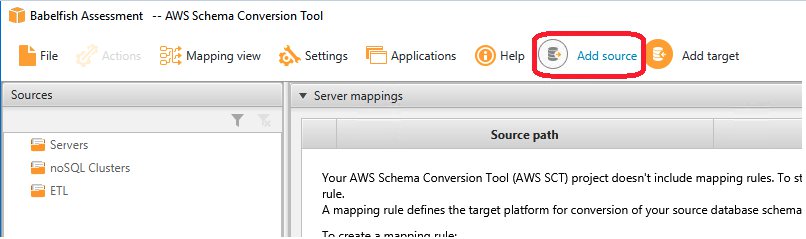
Choose Add source to add a new source database to your AWS SCT project.
Choose the source database vendor (for this post, SQL Server).
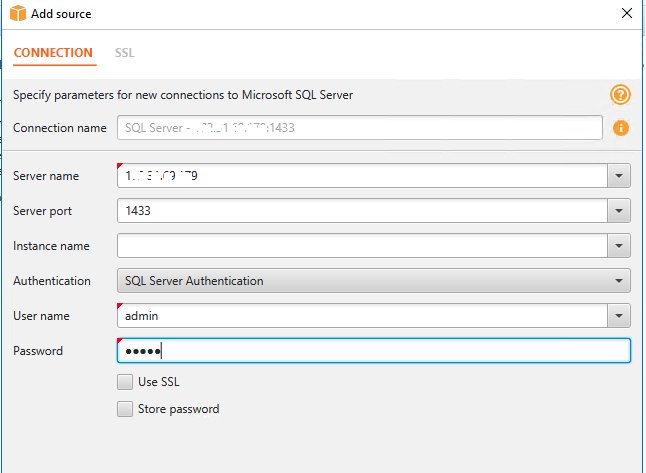
Provide the connection details.
Choose Connect.
As a security best practice, choose Configure SSL.
AWS SCT uses Secure Sockets Layer (SSL) to encrypt your data over the wire and safely store your database credentials using a client certificate. For more information, refer to Connecting to SQL Server as a source.
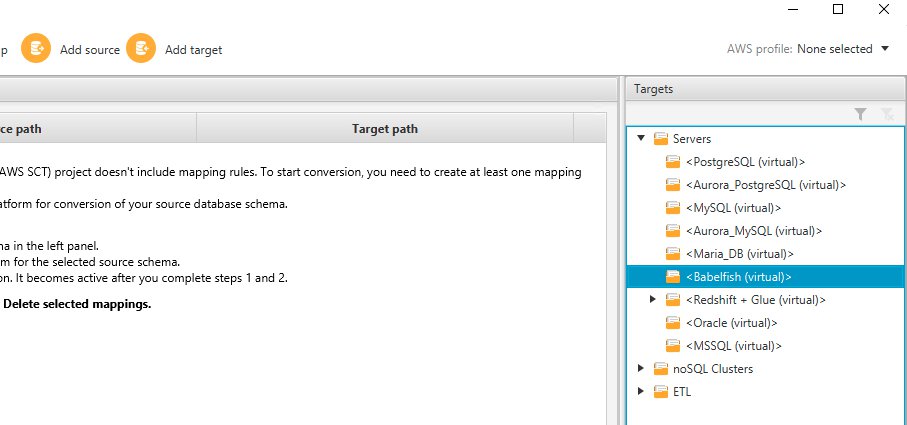
Choose the source database and schema in the left pane.
To add your virtual target, in the right pane, choose Servers and choose <Babelfish (virtual)>.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Map source and target schemas
In the source tree, choose one or more schemas for mapping (right-click). Choose Create mapping to create the mapping for the intended target database platform.
{kind=link}
After you create the mappings, the mapping view is available. Select your server mappings and choose Main view.
{kind=link}
Generate the assessment report
After you create your mappings, you can generate an assessment report.
Expand the Northwind database in the Servers list.
Select the desired schemas.
Choose schemas (right-click) and choose Create report.
{kind=link}
Analyze the assessment report and review action items
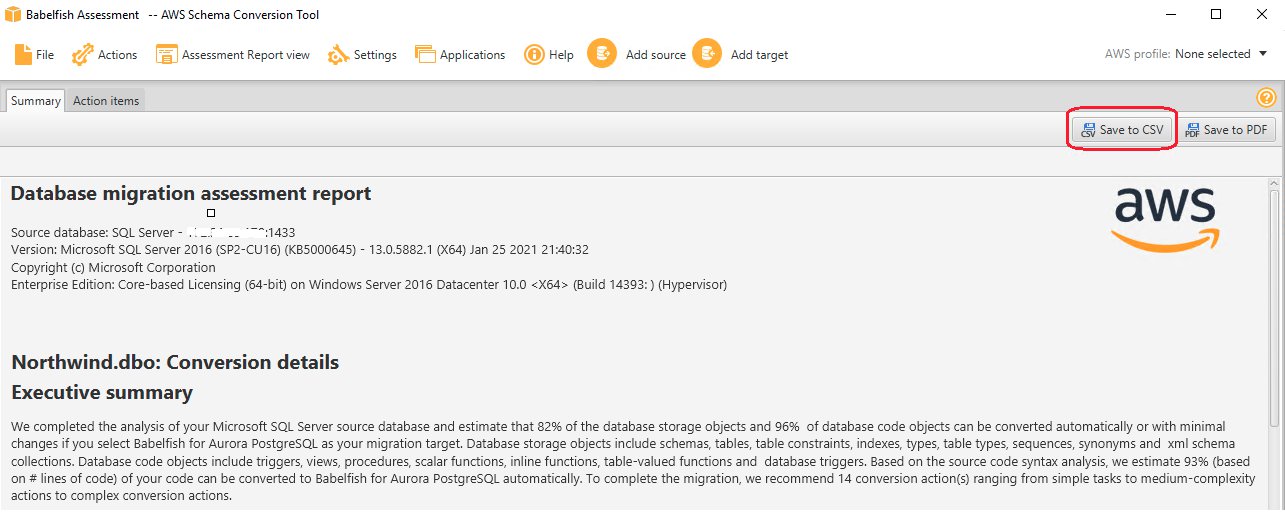
The assessment report provides a summary of your schema conversion details for items that aren’t supported by the latest version of Babelfish. You can use this report to evaluate the database code and storage objects that are supported by Babelfish, and what else you need to complete the conversion. You can save a local copy of the database migration assessment report as either a PDF or CSV file for viewing outside of AWS SCT or sharing with others.
{kind=link}
When you choose Save to CSV, AWS SCT creates three CSV files. For more information about each of the files, see Saving the assessment report.
{kind=link}
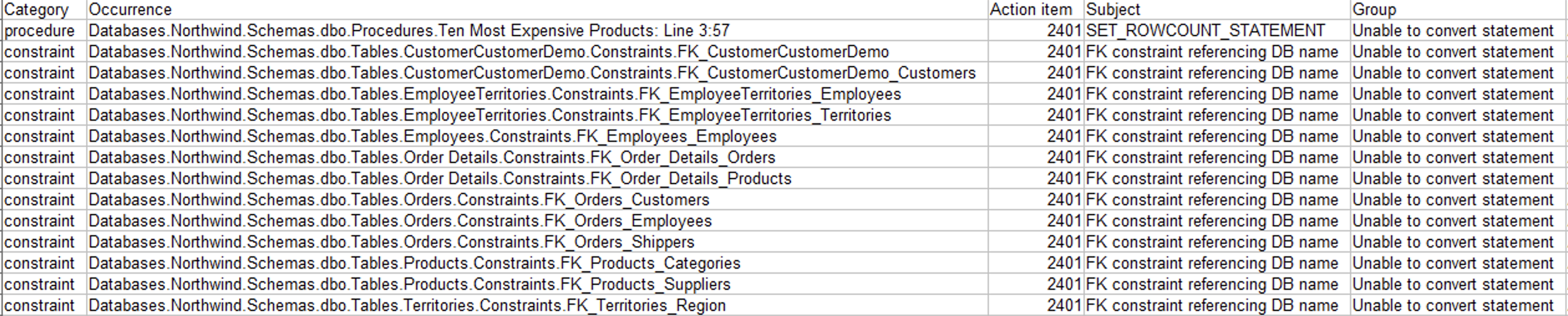
The following table below shows the category of the action items. For example, AWS SCT found 7 procedures in the schema and it is telling you that you can run 6 of them without any code changes in Babelfish for Aurora PostgreSQL, but 1 of them does require updates.
{kind=link}
The following example shows the summary of the action items.
{kind=link}
In our case, AWS SCT completed the analysis of our SQL Server source database and estimated that 82% of the database storage objects and 96% of database code objects are compatible through Babelfish for Aurora PostgreSQL. Database storage objects include schemas, tables, table constraints, indexes, types, and others. Database code objects include triggers, views, procedures, scalar functions, inline functions, table-valued functions, and database triggers. Based on the source code syntax analysis, AWS SCT estimated 93% (based on number of lines of code) of our code can be converted to Babelfish for Aurora PostgreSQL automatically. To complete the migration, work on the remaining conversion actions, ranging from simple tasks to medium-complexity actions to complex conversion actions.
{kind=link}
{kind=link}
In this case, choose Objects with complex actions in the database code objects, which shows the respective action items. AWS SCT indicates objects with complex actions by adding an exclamation mark with a red background.
In the following example, the SET ROWCOUNT statement is not supported by the current version of Babelfish for Aurora PostgreSQL.
{kind=link}
Choose the issue, which shows the SQL for the respective issue in the bottom pane.
{kind=link}
In this case, we remove the SET ROWCOUNT statement and update the SQL. You can validate the remaining observations in the same fashion and then use the updated DDL to populate the Babelfish database.
You can edit database code objects in place using AWS SCT, as shown in the following screenshot. However, you can’t edit database storage objects using AWS SCT. After you complete the action items related to database code objects, save the SQL file in stages, and work on the database storage object action items using any SQL editor.
{kind=link}
Save your converted schema to a file
You can save your converted schema as SQL scripts in a text file. With this approach, you can modify the generated SQL scripts from AWS SCT to address items related to database storage objects. You can then run your updated scripts on your Babelfish database.
To choose the format of the SQL script, complete the following steps:
On the Settings menu, choose Project settings.
Choose Save scripts.
For Vendor, choose SQL Server.
For Save SQL scripts to, choose Single file per stage.
Choose OK to save the settings.
To save the converted code to a SQL script, choose the intended schema on the target tree (right-click), and choose Save as SQL.
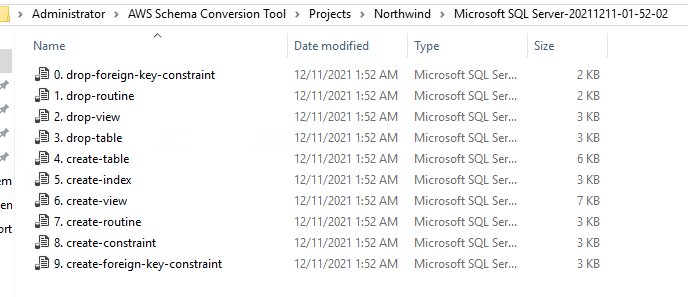
Select the directory to save the SQL files. In this case, we save them in C:UsersAdministratorAWS Schema Conversion ToolProjectsNorthwindMicrosoft SQL Server-20211211-01-52-02.
{kind=link}
{kind=link}
{kind=link}
Create database objects and load the Babelfish database
In the following example, we use registered servers in SSMS for ease of use. For more information, refer to Create a New Registered Server (SQL Server Management Studio).
{kind=link}
After you add the newly created Babelfish endpoint to the registered servers, right-click on the Babelfish endpoint and choose New Query.
{kind=link}
We create a new database named Northwind using the following command, because the SQL files saved from AWS SCT don’t have the create database command:
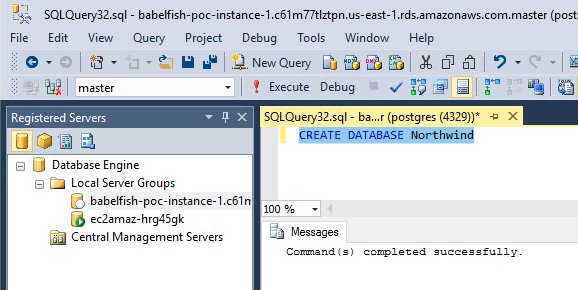{kind=link}
Because it’s an empty database, we ignore the drop-* SQL files generated from AWS SCT and start with the create table script. Open the create-table.sql file in a new query and make sure to connect to your Babelfish endpoint and run this script.
{kind=link}
Now the tables are created in a Babelfish-enabled database. Let’s create the primary key for these tables. Open the create-constraint.sql file and run against the Babelfish endpoint.
{kind=link}
Once the tables and primary key constraints are created, let’s start with the data load using SSIS. On successful data load, you will run the remaining SQL files generated by AWS SCT.
Run the remaining SQL files generated from AWS SCT
We have run the create-table.sql and create-constraint.sql scripts (generated by AWS SCT) to create the tables and constraints in the Babelfish-enabled database. Let’s run the remaining scripts using SSMS query editor connected to a Babelfish endpoint. Run the following scripts to create the remaining database objects:
create-index.sql
create-view.sql
create-routine.sql
create-foreign-key-constraint.sql
Validate the migrated data and test the functionality
After you run the DDL and DML, let’s confirm that we can see the same results between the TDS and PostgreSQL endpoints:
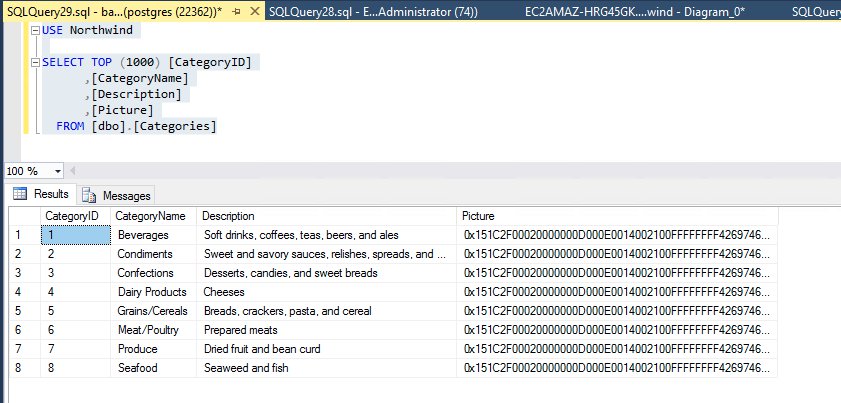{kind=link}
We run the same query with the PostgreSQL endpoint using pgAdmin.
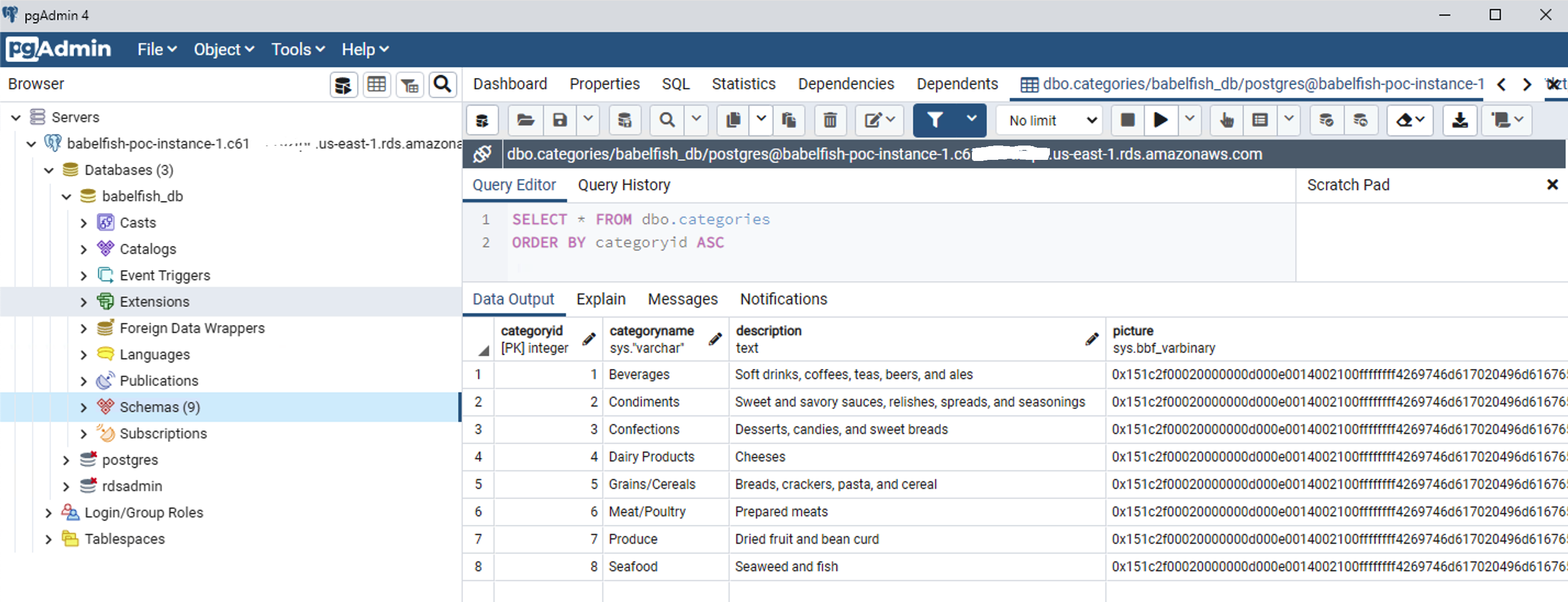{kind=link}
Summary
In this post, we walked through the steps involved in migrating a SQL Server application to Babelfish for Aurora PostgreSQL using AWS SCT. The AWS SCT assessment report helps you understand and make informed decisions regarding the level of complexity and necessary components to complete the migration. Because most of the SQL features in the demo application are supported by Babelfish, you could migrate this application to PostgreSQL with minimal effort.
If you have any questions, comments, or suggestions, leave a comment in the comments section.
About the Author
Ramesh Kumar Venkatraman is a Solutions Architect at AWS who is passionate about containers and databases. He works with AWS customers to design, deploy and manage their AWS workloads and architectures. In his spare time, he loves to play with his two kids and follows cricket.
{kind=link}
Read MoreAWS Database Blog