

{kind=link}
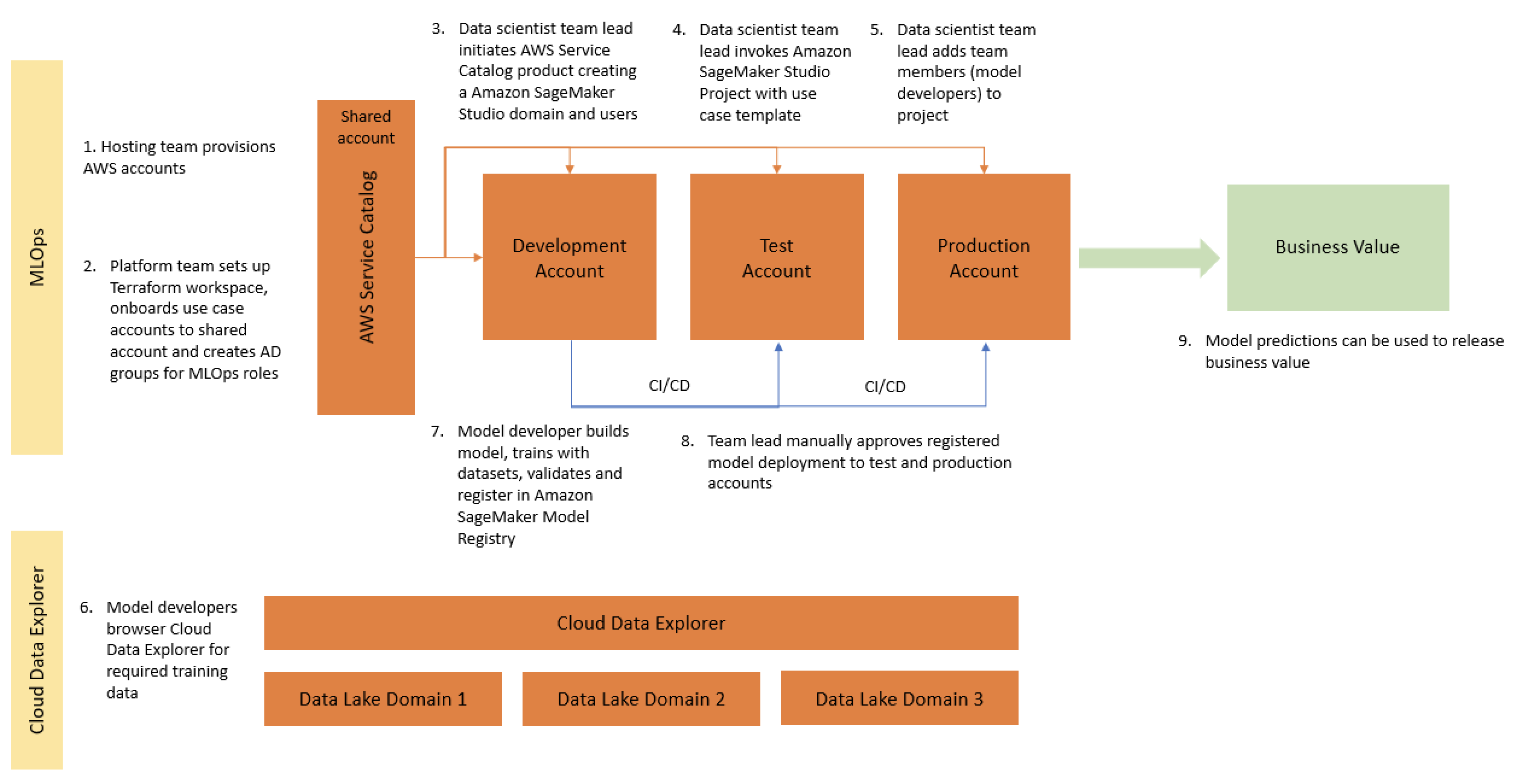
This is the first post of a four-part series detailing how NatWest Group, a major financial services institution, partnered with AWS to build a scalable, secure, and sustainable machine learning operations (MLOps) platform.
This initial post provides an overview of the AWS and NatWest Group joint team implemented Amazon SageMaker Studio as the standard for the majority of their data science environment in just 9 months. The intended audience includes decision-makers that would like to standardize their ML workflows, such as CDAO, CDO, CTO, Head of Innovation, and lead data scientists. Subsequent posts will detail the technical implementation of this solution.
Read the entire series:
Part 1: How NatWest Group built a scalable, secure, and sustainable MLOps platform
Part 2: How NatWest Group built a secure, compliant, self-service MLOps platform using AWS Service Catalog and Amazon SageMaker
Part 3: How NatWest Group built auditable, reproducible, and explainable ML models with Amazon SageMaker
Part 4: How NatWest Group migrated ML models to Amazon SageMaker architectures
MLOps
For NatWest Group, MLOps focuses on realizing the value from any data science activity through the adoption of DevOps and engineering best practices to build solutions and products that have an ML component at their core. It provides the standards, tools, and framework that supports the work of data science teams to take their ideas from the whiteboard to production in a timely, secure, traceable, and repeatable manner.
Strategic collaboration between NatWest Group and AWS
NatWest Group is the largest business and commercial bank in the UK, with a leading retail business. The Group champions potential by supporting 19 million people, families, and businesses in communities throughout the UK and Ireland to thrive by acting as a relationship bank in a digital world.
As the Group attempted to scale their use of advanced analytics in the enterprise, they discovered that the time taken to develop and release ML models and solutions into production was too long. They partnered with AWS to design, build, and launch a modern, secure, scalable, and sustainable self-service platform for developing and productionizing ML-based services to support their business and customers. AWS Professional Services worked with them to accelerate the implementation of AWS best practices for Amazon SageMaker services.
The aims of the collaboration between NatWest Group and AWS were to provide the following:
A federated, self-service, and DevOps-driven approach for infrastructure and application code, with a clear route-to-live that will lead to deployment times being measured in minutes (the current average is 60 minutes) and not weeks.
A secure, controlled, and templated environment to accelerate innovation with ML models and insights using industry best practices and bank-wide shared artifacts.
The ability to access and share data more easily and consistently across the enterprise.
A modern toolset based upon a managed architecture running on demand that would minimize compute requirements, drive down costs, and drive sustainable ML development and operations. This should have the flexibility to accommodate new AWS products and services to meet ongoing use case and compliance requirements.
Adoption, engagement, and training support for data science and engineering teams across the enterprise.
To meet the security requirements of the bank, public internet access is disabled and all data is encrypted with custom keys. As described in Part 2 of this series, a secure instance of SageMaker Studio is deployed to the development account in 60 minutes. When the account setup is complete, a new use case template is requested by the data scientists via SageMaker projects in SageMaker Studio. This process deploys the necessary infrastructure that ensures MLOps capabilities in the development account (with minimal support required from operational teams) such as CI/CD pipelines, unit testing, model testing, and monitoring.
This was to be provided in a common layer of capability, displayed in the following figure.
{kind=link}
The process
The joint AWS-NatWest Group team used an agile five-step process to discover, design, build, test, and deploy the new platform over 9 months:
Discovery – Several information-gathering sessions were conducted to identify the current pain points within their ML lifecycle. These included challenges around data discovery, infrastructure setup and configuration, model building, governance, route-to-live, and the operating model. Working backward, AWS and NatWest Group understood the core requirements, priorities, and dependencies that helped create a common vision, success criteria, and delivery plan for the MLOps platform.
Design – Based on the output from the Discovery phase, the team iterated towards the final design for the MLOps platform by combining best practices and advice from AWS and existing experience of using cloud services within NatWest Group. This was done with a particular focus on ensuring compliance with the security and governance requirements typical within the financial services domain.
Build – The team collaboratively built the Terraform and AWS CloudFormation templates for the platform infrastructure. Feedback was continually gathered from end-users (data scientists, ML and data engineers, platform support team, security and governance, and senior stakeholders) to ensure deliverables matched original goals.
Test – A crucial aspect of the delivery was to demonstrate the platform’s viability on real business analytics and ML use cases. NatWest identified three projects that covered a range of business challenges and data science complexity that would allow the new platform to be tested across dimensions including scalability, flexibility, and accessibility. AWS and NatWest Group data scientists and engineers co-created the baseline environment templates and SageMaker pipelines based upon these use cases.
Launch – Once the capability was proven, the team launched the new platform into the organization, providing bespoke training plans and careful adoption and engagement support to the federated business teams to onboard their own use cases and users.
The scalable ML framework
In a business with millions of customers sitting across multiple lines of business, ML workflows require the integration of data owned and managed by siloed teams using different tools to unlock business value. Because NatWest Group is committed to the protection of its customers’ data, the infrastructure used for ML model development is also subject to high security standards, which adds further complexity and impacts the time-to-value for new ML models. In a scalable ML framework, toolset modernization and standardization are necessary to reduce the efforts required for combining different tools and to simplify the route-to-live process for new ML models.
Prior to engaging with AWS, support for data science activity was controlled by a central platform team that collected requirements, and provisioned and maintained infrastructure for data teams across the organization. NatWest has ambitions to rapidly scale the use of ML in federated teams across the organization, and needed a scalable ML framework that enables developers of new models and pipelines to self-serve the deployment of a modern, pre-approved, standardized, and secure infrastructure. This reduces the dependency on the centralized platform teams and allows for a faster time-to-value for ML model development.
The framework in its simplest terms allows a data consumer (data scientist or ML engineer) to browse and discover the pre-approved data they require to train their model, gain access to that data in a quick and simple manner, use that data to prove their model viability, and release that proven model to production for others to utilize, thereby unlocking business value.
The following figure denotes this flow and the benefits that the framework provides. These include reduced compute costs (due to the managed and on-demand infrastructure), reduced operational overhead (due to the self-service templates), reduced time to spin up and spin down secure compliant ML environments (with AWS Service Catalog products), and a simplified route-to-live.
{kind=link}
At a lower level, the scalable ML framework comprises the following:
Self-service infrastructure deployment – Reduces dependency on centralized teams.
A central Python package management system – Makes pre-approved Python packages available for model development.
CI/CD pipelines for model development and promotion – Decreases time-to-live by including CI/CD pipelines as part of infrastructure as code (IaC) templates.
Model testing capabilities – Unit testing, model testing, integration testing, and end-to-end testing functionalities are automatically available for new models.
Model decoupling and orchestration – Decouples model steps according to computational resource requirements and orchestration of the different steps via Amazon SageMaker Pipelines. This avoids unnecessary compute and makes deployments more robust.
Code standardization – Code quality standardization with Python Enhancement Proposal (PEP8) standards validation via CI/CD pipelines integration.
Quick-start generic ML templates – AWS Service Catalog templates that instantiate your ML modelling environments (development, pre-production, production) and associated pipelines with the click of a button. This is done via Amazon SageMaker Projects deployment.
Data and model quality monitoring – Automatically monitors drift in your data and model quality via Amazon SageMaker Model Monitor. This helps ensure your models perform to operational requirements and within risk appetite.
Bias monitoring – Automatically checks for data imbalances and if changes in the world have introduced bias to your model. This helps the model owners ensure that they make fair and equitable decisions.
To prove SageMaker’s capabilities across a range of data processing and ML architectures, three use cases were selected from different divisions within the banking group. Use case data was obfuscated and made available in a local Amazon Simple Storage Service (Amazon S3) data bucket in the use case development account for the capabilities proving phase. When the model migration was complete, the data was made available via the NatWest cloud-hosted data lake, where it’s read by the production models. The predictions generated by the production models are then written back to the data lake. Future use cases will incorporate Cloud Data Explorer, an accelerator that allows data engineers and scientists to easily search and browse NatWest’s pre-approved data catalog, which accelerates the data discovery process.
As defined by AWS best practices, three accounts (dev, test, prod) are provisioned for each use case. To meet security requirements, public internet access is disabled and all data is encrypted with custom keys. As described in this blog post, a secure instance of SageMaker Studio is then deployed to the development account in a matter of minutes. When the account setup is complete, a new use case template is requested by the data scientists via SageMaker Projects in Studio. This process deploys the necessary infrastructure that ensures MLOps capabilities in the development account (with minimal support required from operational teams) such as CI/CD pipelines, unit testing, model testing, and monitoring.
Each use case was then developed (or refactored in the case of an existing application codebase) to run in a SageMaker architecture as illustrated in this blog post, utilizing SageMaker capabilities such as experiment tracking, model explainability, bias detection, and data quality monitoring. These capabilities were added to each use case pipeline as described in this blog post.
Cloud-first: The solution for sustainable ML model development and deployment
Training ML models using large datasets requires a lot of computational resources. However, you can optimize the amount of energy used by running training workflows in AWS. Studies suggest that AWS typically produces a nearly 80% lower carbon footprint and is five times more energy efficient than the median-surveyed European enterprise data centers. In addition, adopting an on-demand managed architecture for ML workflows, such as what they developed during the partnership, allows NatWest Group to only provision the necessary resources for the work to be done.
For example, in a use case with a big dataset where 10% of the data columns contain actual useful information and are used for the model training, the on-demand architecture orchestrated by SageMaker Pipelines allows for the split of the data preprocessing step into two phases: first, read and filter, and second, feature engineering. That way, a larger compute instance is used for reading and filtering the data, because that requires more computational resources, whereas a smaller instance is used for the feature engineering, which only needs to process 10% of the useful columns. Finally, the inclusion of SageMaker services such as Model Monitor and Pipelines allows for the continuous monitoring of the data quality, avoiding inference on models that have drifted in data and model quality. This further saves energy and computer resources with compute jobs that don’t bring business value.
During the partnership, multiple sustainability optimization techniques were introduced to NatWest’s ML model development and deployment strategy, from the selection of efficient on-demand managed architectures to the compression of data in efficient file formats. Initial calculations suggest considerable carbon emissions reductions when compared to other cloud architectures, supporting NatWest Group’s ambition to be net zero by 2050.
Outcomes
During the 9 months of delivery, NatWest and AWS worked as a team to build and scale the MLOps capabilities across the bank. The overall achievements of the partnership include:
Scaling MLOps capability across NatWest, with over 300 data scientists and data engineers being trained to work in the developed platform
Implementation of a scalable, secure, cost-efficient, and sustainable infrastructure deployment using AWS Service Catalog to create a SageMaker on-demand managed infrastructure
Standardization of the ML model development and deployment process across multiple teams
Reduction of technical debt of existing models and the creation of reusable artifacts to speed up future model development
Reduction of idea-to-value time for data and analytics use cases from 40 to 16 weeks
Reduction for ML use case environment creation time from 35–40 days to 1–2 days, including multiple validations of the use case required by the bank
Conclusion
This post provided an overview of the AWS and NatWest Group partnership that resulted in the implementation of a scalable ML framework and successfully reduced the time-to-live of ML models at NatWest Group.
In a joint effort, AWS and NatWest implemented standards to ensure scalability, security, and sustainability of ML workflows across the organization. Subsequent posts in this series will provide more details on the implemented solution:
Part 2 describes how NatWest Group used AWS Service Catalog and SageMaker to deploy their secure, compliant, and self-service MLOps platform. It is intended to provide details for platform developers such as DevOps, platform engineers, security, and IT teams.
Part 3 provides an overview of how NatWest Group uses SageMaker services to build auditable, reproducible, and explainable ML models. It is intended to provide details for model developers, such as data scientists and ML or data engineers.
Part 4 details how NatWest data science teams migrate their existing models to SageMaker architectures. It is intended to provide details of how to successfully migrate existent models to model developers, such as data scientists and ML or data engineers.
AWS Professional Services is ready to help your team develop scalable and production-ready ML in AWS. For more information, see AWS Professional Services or reach out through your account manager to get in touch.
About the Authors
Maira Ladeira Tanke is a Data Scientist at AWS Professional Services. As a technical lead, she helps customers accelerate their achievement of business value through emerging technology and innovative solutions. Maira has been with AWS since January 2020. Prior to that, she worked as a data scientist in multiple industries focusing on achieving business value from data. In her free time, Maira enjoys traveling and spending time with her family someplace warm.
Andy McMahon is a ML Engineering Lead in the Data Science and Innovation team in NatWest Group. He helps develop and implement best practices and capabilities for taking machine learning products to production across the bank. Andy has several years’ experience leading data science and ML teams and speaks and writes extensively on MLOps (this includes the book “Machine Learning Engineering with Python”, 2021, Packt). In his spare time, he loves running around after his young son, reading, playing badminton and golf, and planning the next family adventure with his wife.
Greig Cowan is a data science and engineering leader in the financial services domain who is passionate about building data-driven solutions and transforming the enterprise through MLOps best practices. Over the past four years, his team have delivered data and machine learning-led products across NatWest Group and have defined how people, process, data, and technology should work together to optimize time-to-business-value. He leads the NatWest Group data science community, builds links with academic and commercial partners, and provides leadership and guidance to the technical teams building the bank’s data and analytics infrastructure. Prior to joining NatWest Group, he spent many years as a scientific researcher in high-energy particle physics as a leading member of the LHCb collaboration at the CERN Large Hadron. In his spare time, Greig enjoys long-distance running, playing chess, and looking after his two amazing children.
Brian Cavanagh is a Senior Global Engagement Manager at AWS Professional Services with a passion for implementing emerging technology solutions (AI, ML, and data) to accelerate the release of value for our customers. Brian has been with AWS since December 2019. Prior to working at AWS, Brian delivered innovative solutions for major investment banks to drive efficiency gains and optimize their resources. Outside of work, Brian is a keen cyclist and you will usually find him competing on Zwift.
Sokratis Kartakis is a Senior Customer Delivery Architect on AI/ML at AWS Professional Services. Sokratis’s focus is to guide enterprise and global customers on their AI cloud transformation and MLOps journey targeting business outcomes and leading the delivery across EMEA. Prior to AWS, Sokratis spent over 15 years inventing, designing, leading, and implementing innovative solutions and strategies in AI/ML and IoT, helping companies save billions of dollars in energy, retail, health, finance and banking, supply chain, motorsports, and more. Outside of work, Sokratis enjoys spending time with his family and riding motorbikes.
Read MoreAWS Machine Learning Blog