

{kind=link}
Amazon SageMaker Data Wrangler reduces the time to aggregate and prepare data for machine learning (ML) from weeks to minutes. With Data Wrangler, you can select and query data with just a few clicks, quickly transform data with over 300 built-in data transformations, and understand your data with built-in visualizations without writing any code.
Additionally, you can create custom transforms unique to your requirements. Custom transforms allow you to write custom transformations using either PySpark, Pandas, or SQL.
Data Wrangler now supports a custom Pandas user-defined function (UDF) transform that can process large datasets efficiently. You can choose from two custom Pandas UDF modes: Pandas and Python. Both modes provide an efficient solution to process datasets, and the mode you choose depends on your preference.
In this post, we demonstrate how to use the new Pandas UDF transform in either mode.
Solution overview
At the time of this writing, you can import datasets into Data Wrangler from Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift, Databricks, and Snowflake. For this post, we use Amazon S3 to store the 2014 Amazon reviews dataset.
The data has a column called reviewText containing user-generated text. The text also contains several stop words, which are common words that don’t provide much information, such as “a,” “an,” and “the.” Removal of stop words is a common preprocessing step in natural language processing (NLP) pipelines. We can create a custom function to remove the stop words from the reviews.
Create a custom Pandas UDF transform
Let’s walk through the process of creating two Data Wrangler custom Pandas UDF transforms using Pandas and Python modes.
Download the Digital Music reviews dataset and upload it to Amazon S3.
Open Amazon SageMaker Studio and create a new Data Wrangler flow.
Under Import data, choose Amazon S3 and navigate to the dataset location.
For File type, choose jsonl.
{kind=link}
A preview of the data should be displayed in the table.
Choose Import to proceed.
After your data is imported, choose the plus sign next to Data types and choose Add transform.
Choose Custom transform.
On the drop-down menu, Python (User-Defined Function).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Now we create our custom transform to remove stop words.
Specify your input column, output column, return type, and mode.
The following example uses Pandas mode. This means the function should accept and return a Pandas series of the same length. You can think of a Pandas series as a column in a table or a chunk of the column. This is the most performant Pandas UDF mode because Pandas can vectorize operations across batches of values as opposed to one at a time. The pd.Series type hints are required in Pandas mode.
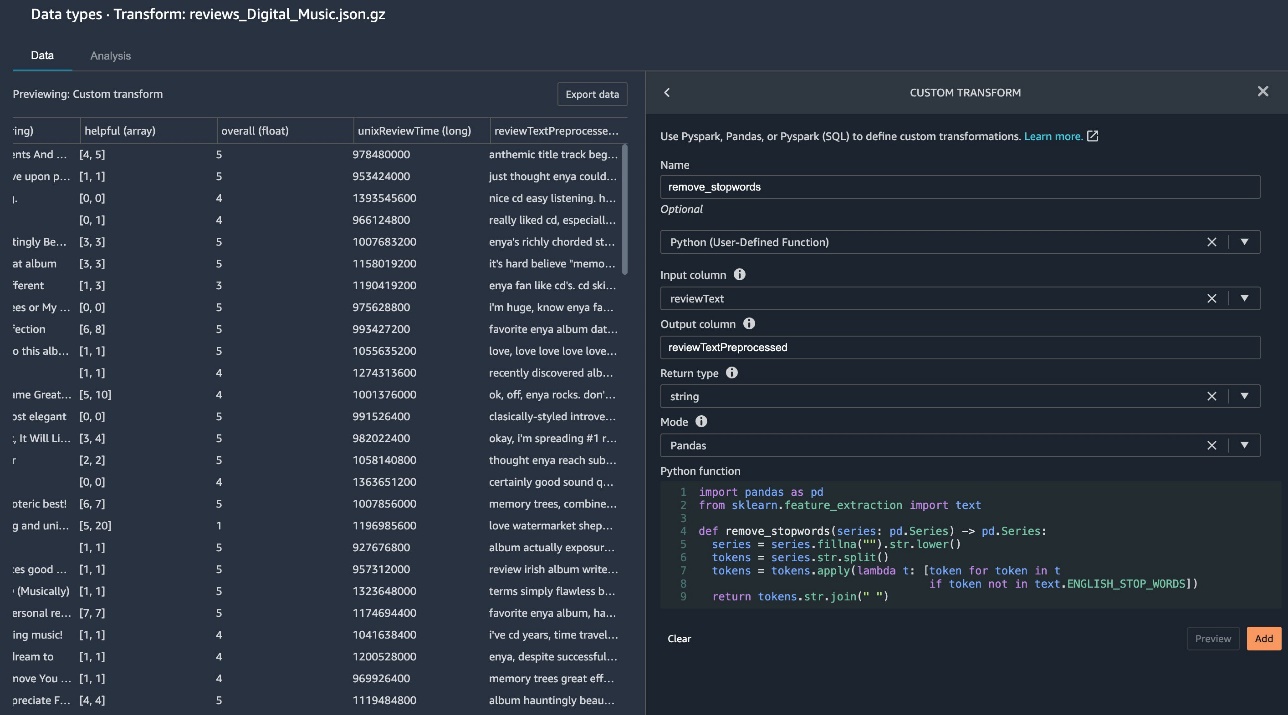{kind=link}
If you prefer to use pure Python as opposed to the Pandas API, Python mode allows you to specify a pure Python function that accepts a single argument and returns a single value. The following example is equivalent to the preceding Pandas code in terms of output. Type hints are not required in Python mode.
{kind=link}
Choose Add to add your custom transform.
Conclusion
Data Wrangler has over 300 built-in transforms, and you can also add custom transformations unique to your requirements. In this post, we demonstrated how to process datasets with Data Wrangler’s new custom Pandas UDF transform, using both Pandas and Python modes. You can use either mode based on your preference. To learn more about Data Wrangler, refer to Create and Use a Data Wrangler Flow.
About the Authors
Ben Harris is a software engineer with experience designing, deploying, and maintaining scalable data pipelines and machine learning solutions across a variety of domains. Ben has built systems for data collection and labeling, image and text classification, sequence-to-sequence modeling, embedding, and clustering, among others.
{kind=link}
Haider Naqvi is a Solutions Architect at AWS. He has extensive Software Development and Enterprise Architecture experience. He focuses on enabling customers to achieve business outcomes with AWS. He is based out of New York.
{kind=link}
Vishal Srivastava is a Technical Account Manager at AWS. With a background in Software Development and Analytics, he primarily works with financial services sector and digital native business customers and supports their cloud journey. In his free time, he loves to travel with his family.
{kind=link}
Read MoreAWS Machine Learning Blog