

{kind=link}
Based in Dubai, Ounass is the Middle East’s leading ecommerce platform for luxury goods. Scouring the globe for leading trends, Ounass’s expert team reports on the latest fashion updates, coveted insider information, and exclusive interviews for customers to read and shop. With more than 230,000 unique catalog items spanning multiple brands and several product classes—including fashion, beauty, jewelry, and home—and more than 120,000 unique daily sessions, Ounass collects a wealth of browsing data.
In this post, we (a joint team of an Ounass data scientist and an AWS AI/ML Solutions Architect), discuss how to build a scalable architecture using Amazon SageMaker that continuously deploys a Word2vec-Nearest Neighbors (Word2vec-NN) item-based recommender system using clickstream data. We dive into defining the components that make up this architecture and the tools used to operate it. Running this recommender system in A/B tests, Ounass saw an average revenue uplift of 849% with respect to recommendations serving Ounass’s most popular items.
Word2vec is a natural language processing (NLP) technique that uses a deep learning (DL) model to learn vector representations of words from a corpus of text. Every word in the corpus used for training the model is mapped to a unique array of numbers known as a word vector or a word embedding. These embeddings are learned so that they encode a degree of semantic similarity between words. For instance, the similarity between the embeddings of “cat” and “dog” would be greater than that between the embeddings of “cat” and “car” because the first pair of words are more likely to appear in similar contexts.
At the time of writing, Ounass is accessible through the following platforms: iOS, Android, and web. As visitors browse the product details pages (PDPs) of Ounass Web, we want to serve them relevant product recommendations without requiring them to log in. Such item-based recommendations were previously generated using a rule-based recommender system that was tedious to maintain and handcrafted rules that were difficult to tune.
{kind=link}
Ounass needs an efficient, robust, scalable, and maintainable solution that adapts to the ever-changing customer preferences. The objective of introducing such a solution is to increase the level of personalization and simplify product discovery for visitors by using the browsing data collected in millions of sessions. To measure success, we use metrics such as conversion rate uplift and revenue uplift.
Compute item embeddings with Word2vec
When a visitor starts a browsing session on Ounass, we assume that they do it with the intent of either purchasing or discovering a particular product or set of related products. For instance, when a user visits our platform with the intent of purchasing a red dress, they would probably look for similar outfits that appeal to their taste. The sequence of items browsed during a session is assumed to encode the user’s stylistic preferences.
As we collect the data from millions of sessions, each session carries with it a unique context that we can use to learn vector representations of items. In analogy to NLP, we treat a browsing session as a sentence and item codes as words in that sentence. As shown in the following figure, this approach allows us to build a corpus of items in which similar items are more likely to appear in similar contexts.
Similarly to the example sentence, which is likely to end with the suggested words, the shown bags are more likely to appear after the sequence of products in the shown session.
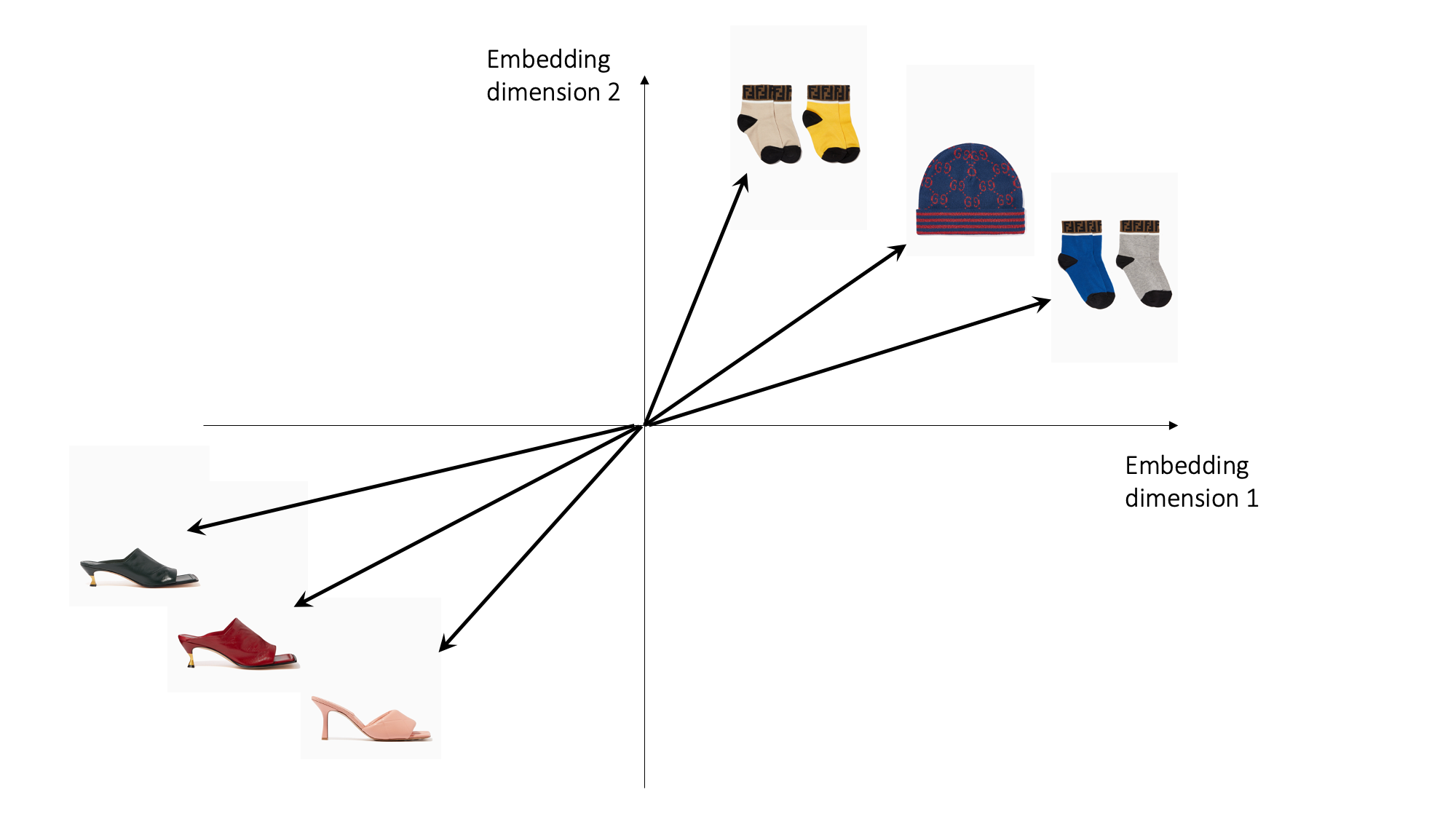
The Word2vec algorithm is trained on this corpus to learn the embeddings of all corpus items, which we refer to as the vocabulary. An item embedding is assumed to encode a numerical representation that captures the context in which the item was browsed. Item embeddings that occur in similar contexts are more likely to have neighboring embeddings, whereas items that rarely appear in similar contexts are more likely to have distant embeddings. As illustrated in the following figure, the wool hat has an embedding that is distant from that of the pink shoe, but is the closest neighbor to the embeddings of the two cotton socks.
We adopted the Word2vec-NN approach for two main reasons:
{kind=link}
In contrast to classical recommendation systems like collaborative filtering or supervised DL-based recommenders, this approach doesn’t require any visitor identifier at inference time and allows handling sessions by visitors who choose to disable cookie tracking.
The learned item embeddings can be rolled up [1] to build session-level embeddings by computing a simple or time-weighted average of the item embeddings that are browsed within a session. Because we’re representing sessions with embeddings that can be computed dynamically through averaging, we can constantly update these embeddings and serve recommendations that adapt to a session’s browsing context. Furthermore, when a user identifier is allowed, session-level embeddings can also be rolled up to compute user-level embeddings.
Word2vec hyperparameters
To compute the item embeddings, we trained the batch skip-gram variant of Word2vec [2] on the items corpus with a batch size of 128 and selected the following hyperparameters:
min_count –Items that appear less than min_count times in the training data are discarded. We set this value to 2.
Epochs – The number of complete passes through the training data, set to 110.
sampling_threshold – The threshold for the occurrence of items. Items that appear with higher frequency in the training data are randomly down-sampled. This value is set to 10-4. This is done in order to shrink down the contribution of items that appear frequently in the corpus of items. In analogy to NLP, such items correspond to articles like “the.” They might appear frequently in the corpus without necessarily carrying any session-level contextual information.
vector_dim – The dimension of the computed item embeddings, set to 50.
negative_samples – The number of negative samples for the negative sample sharing strategy, which we set to 6.
window_size – The size of the context window. The context window is the number of items surrounding the target item used for training. We set the value of window_size to 7.
Generate recommendations with nearest neighbors
After learning item embeddings, recommendations can be served using item or rolled-up user embeddings as follows:
On the platform, when a user browses the PDP of an item, the item’s Stock Keeping Unit (SKU) code is sent to our system, which does the following:
Determines the item’s K nearest neighbors in the embedding space
Serves the SKU code of the K neighboring items as recommendations
We use CRM to pull the sequence of SKUs browsed by an identified user for the last N sessions and send it as input to our system, which does the following:
Builds a user embedding by averaging the embeddings of input SKUs
Computes the user’s K nearest neighbors in the item embedding space
Serves the SKU code of these K neighboring items as recommendations through an email communication
Solution architecture
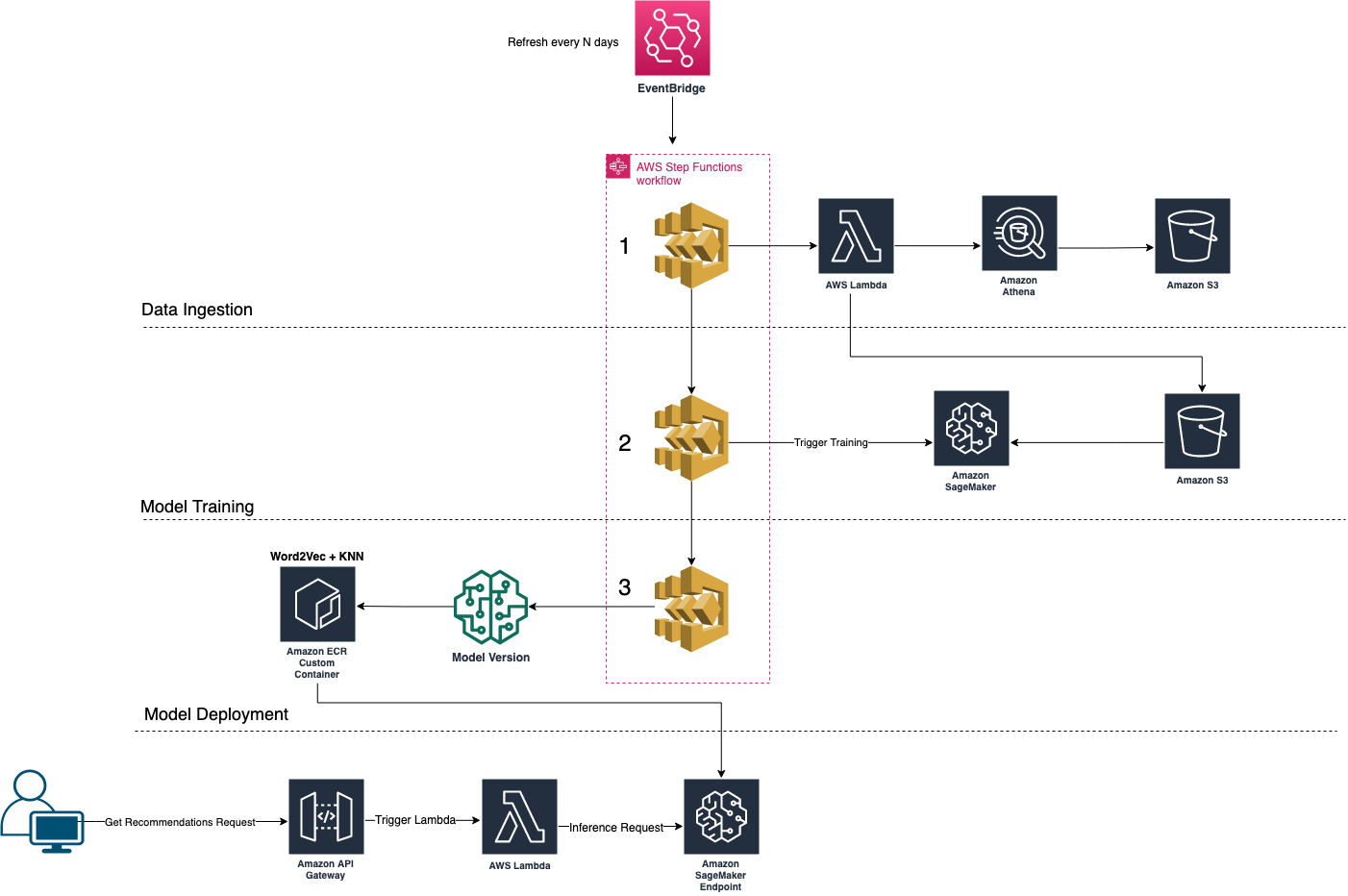
Our aim is to build a machine learning (ML) pipeline to enable continuous integration and continuous delivery (CI/CD) capabilities for the ML development lifecycle and automate the training, update, and release of the model versions. To achieve this, we use the AWS Step Functions Data Science SDK. The following diagram shows the overall end-to-end architecture, from training to inference, that we used to develop the scalable recommender that gets constantly refreshed.
The workflow that we built using AWS Step Functions is divided into three main stages:
{kind=link}
In the first stage, we extract the relevant session history by querying our unstructured data lake using Amazon Athena. The extracted data that contains the corpus of items is then saved in an Amazon Simple Storage Service (Amazon S3) bucket after transforming it into a format that can be consumed by the training algorithm.
In the next stage, we use the SageMaker BlazingText algorithm to train a Word2vec model on the saved corpus of items using a distributed cluster of multiple GPU instances. We decided to use the BlazingText built-in container because it provides a highly optimized and distributed implementation of the Word2vec algorithm.
In the last stage, we configure and deploy a SageMaker endpoint serving the Word2vec-NN recommendations. Because the built-in BlazingText Word2vec deployment serves the embedding representation of an item by default, we built a custom inference Docker container that combines the nearest neighbors (NN) technique with the Word2vec model. When an inference request comes in, we generate the embedding for the SKU, calculate top K nearest items, and return the list back to the user in the response.
We use an Amazon API Gateway layer in conjunction with an AWS Lambda function to handle the HTTPS requests from the front-end application to the SageMaker inference endpoint.
This workflow is automatically triggered periodically to keep the model up to date with the new data and new items. We use Amazon EventBridge to trigger the Step Functions workflow every 3 days to retrain the model with new data and deploy a new version of the model.
Test the solution
To assess the utility of the solution, we ran an A/B test consisting of a series of email communications containing item recommendations. The experiment was run from May 22, 2021, to June 30, 2021. The control group was targeted with communications containing the eight most popular of Ounass’s items at the time. The treatment group was targeted with communications containing Word2vec-NN personalized item recommendations based on the items that a user had browsed 2 days prior to the targeting date. The two groups were carefully sampled from our customer base while accounting for features such as recency, frequency, monetary value, as well as behavioral features pertaining to browsing behavior. To measure success, we selected the incremental revenue uplift generated by the treatment group relative to that of the control group, as illustrated in the following chart.
{kind=link}
The diagram shows a time series chart of the incremental revenue uplift of treatment relative to control. During the experiment period, the uplift fluctuates between 100%–1200%, with an average value of 849% and a standard deviation of about 200%. These results highlight the relevance and utility of the Word2vec-NN recommendations.
Improvements
The developed solution will be improved in different ways:
Firstly, we can handle out-of-vocabulary items and items starting from the cold. The term vocabulary refers to the set of items available in the corpus used to train Word2vec. Any item that isn’t in this vocabulary is known as an out-of-vocabulary (OOV) item. OOV items don’t get assigned an embedding representation. In production, when an OOV item SKU code is served as an input to the Word2vec-NN recommender, the system fails to generate a recommendation.
To handle OOV, we can train an algorithm such as FastText on a corpus consisting of textual item descriptions instead of SKU codes. Such an algorithm can handle OOV items and generate embeddings based on item descriptions. This approach also allows us to generate recommendations for items that don’t appear frequently in the session data because they’re starting from the cold with very few visits. For these items, the Word2vec algorithm would have a hard time computing reliable embedding.
Additionally, we can compute more representative embeddings. Using a multi-modal training with data that combines item descriptions and item images allows us to enrich the embedding representation of items and enables our system to implicitly handle OOV and cold-start items.
Conclusion
In this post, we shared a real-world architecture that you can use to develop a scalable recommender system without the need of a visitor identifier. Incorporating periodic model refresh allows the system to dynamically adapt to users’ changing preferences and generate fresh item embeddings. In the carefully planned A/B test, we observed that the recommendations from the Word2Vec-NN system led to an average revenue uplift of 849% with respect to recommendations serving Ounass’s most popular items. Visit Machine Learning on AWS to learn more about the various machine learning services supporting cloud infrastructure. You can get started with Amazon SageMaker by visiting the webpage.
References
Customer2Vec: Representation learning for customer analytics and personalization
BlazingText algorithm
About the Authors
Elie Kawerk is a Data Scientist and Data Educator at Ounass with extensive experience in developing data science solutions for media, retail, and entertainment. He holds a PhD in computational physics from Sorbonne University, Paris and has held a High Performance Computing research fellowship in the University of Trieste, Italy. His interests include – but are not limited to – metric design, experimentation, causal inference, machine & deep learning, MLOps, and data architecture.
{kind=link}
Will Badr is a Principal AI/ML Specialist SA who works as part of the global Amazon Machine Learning team. Will is passionate about using technology in innovative ways to positively impact the community. In his spare time, he likes to go diving, play soccer and explore the Pacific Islands.
{kind=link}
Read MoreAWS Machine Learning Blog