

{kind=link}
This is a guest post by Viktor Enrico Jeney, Senior Machine Learning Engineer at Adspert.
Adspert is a Berlin-based ISV that developed a bid management tool designed to automatically optimize performance marketing and advertising campaigns. The company’s core principle is to automate maximization of profit of ecommerce advertising with the help of artificial intelligence. The continuous development of advertising platforms paves the way for new opportunities, which Adspert expertly utilizes for their customers’ success.
Adspert’s primary goal is to simplify the process for users while optimizing ad campaigns across different platforms. This includes the use of information gathered across the various platforms balanced against the optimum budget set on a level above each platform. Adspert’s focus is to optimize a customer’s goal attainment, regardless of what platform is used. Adspert continues to add platforms as necessary to give our customers significant advantages.
In this post, we share how Adspert created the pricing tool from scratch using different AWS services like Amazon SageMaker and how Adspert collaborated with the AWS Data Lab to accelerate this project from design to build in record time.
The pricing tool reprices a seller-selected product on an ecommerce marketplace based on the visibility and profit margin to maximize profits on the product level.
As a seller, it’s essential that your products are always visible because this will increase sales. The most important factor in ecommerce sales is simply if your offer is visible to customers instead of a competitor’s offer.
Although it certainly depends on the specific ecommerce platform, we’ve found that product price is one of the most important key figures that can affect visibility. However, prices change often and fast; for this reason the pricing tool needs to act in near-real time to increase the visibility.
Overview of solution
The following diagram illustrates the solution architecture.
{kind=link}
The solution contains the following components:
Amazon Relational Database Service (Amazon RDS) for PostgreSQL is the main source of data, containing product information that is stored in an RDS for Postgres database.
Product listing changes information arrives in real time in an Amazon Simple Queue Service (Amazon SQS) queue.
Product information stored in Amazon RDS is ingested in near-real time into the raw layer using the change data capture (CDC) pattern available in AWS Database Migration Service (AWS DMS).
Product listing notifications coming from Amazon SQS are ingested in near-real time into the raw layer using an AWS Lambda function.
The original source data is stored in the Amazon Simple Storage Service (Amazon S3) raw layer bucket using Parquet data format. This layer is the single source of truth for the data lake. The partitioning used on this storage supports the incremental processing of data.
AWS Glue extract, transform, and load (ETL) jobs clean the product data, removing duplicates, and applying data consolidation and generic transformations not tied to a specific business case.
The Amazon S3 stage layer receives prepared data that is stored in Apache Parquet format for further processing. The partitioning used on the stage store supports the incremental processing of data.
The AWS Glue jobs created in this layer use the data available in the Amazon S3 stage layer. This includes application of use case-specific business rules and calculations required. The results data from these jobs are stored in the Amazon S3 analytics layer.
The Amazon S3 analytics layer is used to store the data that is used by the ML models for training purposes. The partitioning used on the curated store is based on the data usage expected. This may be different to the partitioning used on the stage layer.
The repricing ML model is a Scikit-Learn Random Forest implementation in SageMaker Script Mode, which is trained using data available in the S3 bucket (the analytics layer).
An AWS Glue data processing job prepares data for the real-time inference. The job processes data ingested in the S3 bucket (stage layer) and invokes the SageMaker inference endpoint. The data is prepared to be used by the SageMaker repricing model. AWS Glue was preferred to Lambda, because the inference requires different complex data processing operations like joins and window functions on a high volume of data (billions of daily transactions). The result from the repricing model invocations are stored in the S3 bucket (inference layer).
The SageMaker training job is deployed using a SageMaker endpoint. This endpoint is invoked by the AWS Glue inference processor, generating near-real-time price recommendations to increase product visibility.
The predictions generated by the SageMaker inference endpoint are stored in the Amazon S3 inference layer.
The Lambda predictions optimizer function processes the recommendations generated by the SageMaker inference endpoint and generates a new price recommendation that focuses on maximizing the seller profit, applying a trade-off between sales volume and sales margin.
The price recommendations generated by the Lambda predictions optimizer are submitted to the repricing API, which updates the product price on the marketplace.
The updated price recommendations generated by the Lambda predictions optimizer are stored in the Amazon S3 optimization layer.
The AWS Glue prediction loader job reloads into the source RDS for Postgres SQL database the predictions generated by the ML model for auditing and reporting purposes. AWS Glue Studio was used to implement this component; it’s a graphical interface that makes it easy to create, run, and monitor ETL jobs in AWS Glue.
Data preparation
The dataset for Adspert’s visibility model is created from an SQS queue and ingested into the raw layer of our data lake in real time with Lambda. Afterwards, the raw data is sanitized by performing simple transformations, like removing duplicates. This process is implemented in AWS Glue. The result is stored in the staging layer of our data lake. The notifications provide the competitors for a given product, with their prices, fulfilment channels, shipping times, and many more variables. They also provide a platform-dependent visibility measure, which can be expressed as a Boolean variable (visible or not visible). We receive a notification any time an offer change happens, which adds up to several million events per month over all our customers’ products.
From this dataset, we extract the training data as follows: for every notification, we pair the visible offers with every non visible offer, and vice versa. Every data point represents a competition between two sellers, in which there is a clear winner and loser. This processing job is implemented in an AWS Glue job with Spark. The prepared training dataset is pushed to the analytics S3 bucket to be used by SageMaker.
Train the model
Our model classifies for each pair of offers, if a given offer will be visible. This model enables us to calculate the best price for our customers, increase visibility based on competition, and maximize their profit. On top of that, this classification model can give us deeper insights into the reasons for our listings being visible or not visible. We use the following features:
Ratio of our price to competitors’ prices
Difference in fulfilment channels
Amount of feedback for each seller
Feedback rating of each seller
Difference in minimum shipping times
Difference in maximum shipping times
Availability of each seller’s product
Adspert uses SageMaker to train and host the model. We use Scikit-Learn Random Forest implementation in SageMaker Script Mode. We also include some feature preprocessing directly in the Scikit-Learn pipeline in the training script. See the following code:
One of the most important preprocessing functions is transform_price, which divides the price by the minimum of the competitor price and an external price column. We’ve found that this is feature has a relevant impact on the model accuracy. We also apply the logarithm to let the model decide based on relative price differences, not absolute price differences.
In the training_script.py script, we first define how to build the Scikit-Learn ColumnTransformer to apply the specified transformers to the columns of a dataframe:
In the training script, we load the data from Parquet into a Pandas dataframe, define the pipeline of the ColumnTranformer and the RandomForestClassifier, and train the model. Afterwards, the model is serialized using joblib:
In the training script, we also have to implement functions for inference:
input_fn – Is responsible for parsing the data from the request body of the payload
model_fn – Loads and returns the model that has been dumped in the training section of the script
predict_fn – Contains our implementation to request a prediction from the model using the data from the payload
predict_proba – In order to draw predicted visibility curves, we return the class probability using the predict_proba function, instead of the binary prediction of the classifier
See the following code:
The following figure shows the impurity-based feature importances returned by the Random Forest Classifier.
{kind=link}
With SageMaker, we were able to train the model on a large amount of data (up to 14 billion daily transactions) without putting load on our existing instances or having to set up a separate machine with enough resources. Moreover, because the instances are immediately shut down after the training job, training with SageMaker was extremely cost-efficient. The model deployment with SageMaker worked without any additional workload. A single function call in the Python SDK is sufficient to host our model as an inference endpoint, and it can be easily requested from other services using the SageMaker Python SDK as well. See the following code:
The model artefact is stored in Amazon S3 by the fit function. As seen in the following code, the model can be loaded as a SKLearnModel object using the model artefact, script path, and some other parameters. Afterwards, it can be deployed to the desired instance type and number of instances.
Evaluate the model in real time
Whenever a new notification is sent for one of our products, we want to calculate and submit the optimal price. To calculate optimal prices, we create a prediction dataset in which we compare our own offer with each competitor’s offer for a range of possible prices. These data points are passed to the SageMaker endpoint, which returns the predicted probability of being visible against each competitor for each given price. We call the probability of being visible the predicted visibility. The result can be visualized as a curve for each competitor, portraying the relationship between our price and the visibility, as shown in the following figure.
{kind=link}
In this example, the visibility against Competitor 1 is almost a piecewise constant function, suggesting that we mainly have to decrease the price below a certain threshold, roughly the price of the competitor, to become visible. However, the visibility against Competitor 2 doesn’t decrease as steeply. On top of that, we still have a 50% chance of being visible even with a very high price. Analyzing the input data revealed that the competitor has a low amount of ratings, which happen to be very poor. Our model learned that this specific ecommerce platform gives a disadvantage to sellers with poor feedback ratings. We discovered similar effects for the other features, like fulfilment channel and shipping times.
The necessary data transformations and inferences against the SageMaker endpoint are implemented in AWS Glue. The AWS Glue job work in micro-batches on the real-time data ingested from Lambda.
Calculate optimal prices using predicted visibilities
Finally, we want to calculate the aggregated visibility curve, which is the predicted visibility for each possible price. Our offer is visible if it’s better than all other sellers’ offers. Assuming independence between the probabilities of being visible against each seller given our price, the probability of being visible against all sellers is the product of the respective probabilities. That means the aggregated visibility curve can be calculated by multiplying all curves.
The following figures show the predicted visibilities returned from the SageMaker endpoint.
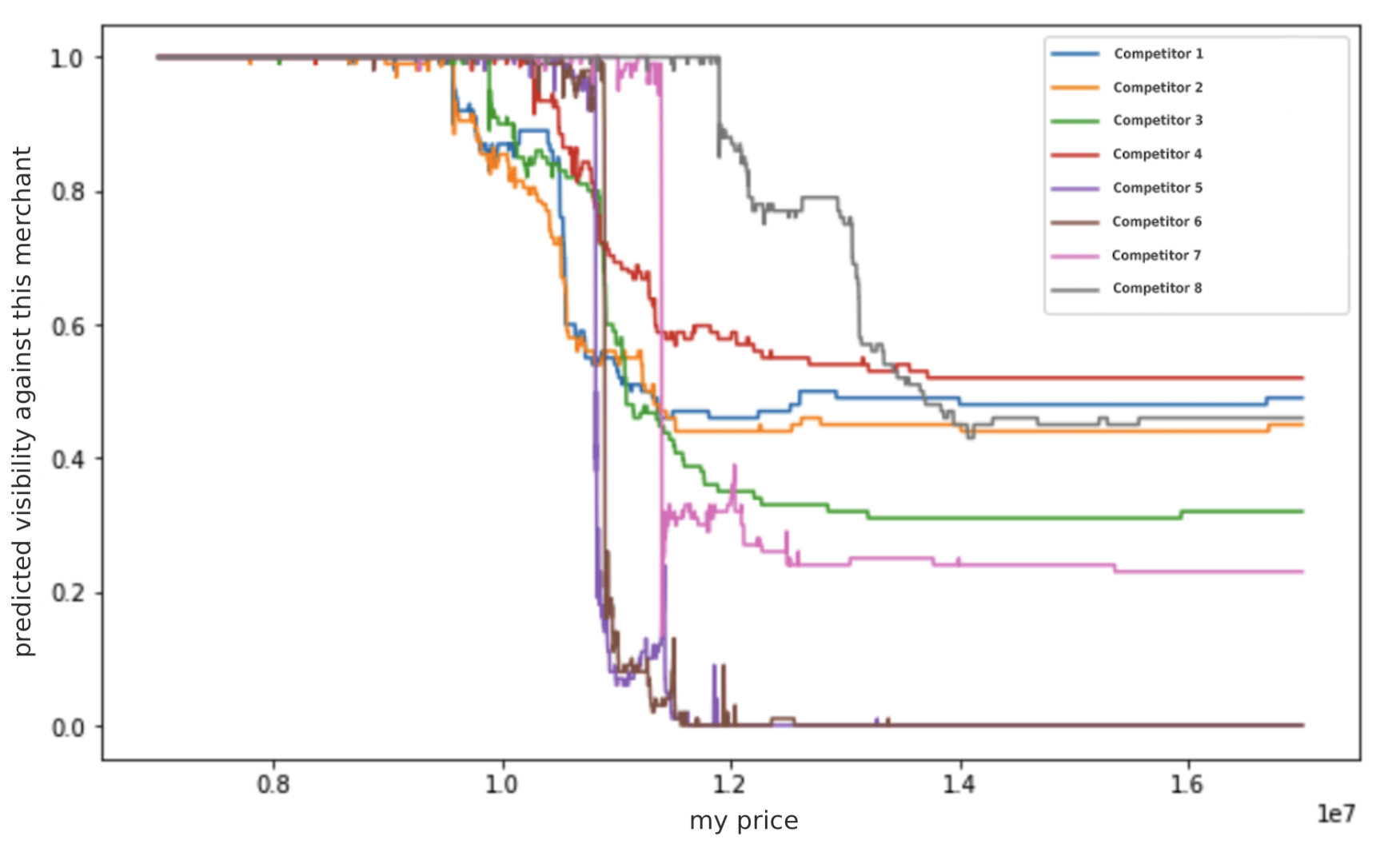{kind=link}
The following figure shows the aggregated visibility curve.
{kind=link}
To calculate the optimal price, the visibility curve is first smoothed and then multiplied by the margin. To calculate the margin, we use the costs of goods and the fees. The cost of goods sold and fees are the static product information synced via AWS DMS. Based on the profit function, Adspert calculates the optimal price and submits it to the ecommerce platform through the platform’s API.
This is implemented in the AWS Lambda prediction optimizer.
The following figure shows the relation between predicted visibility and price.
{kind=link}
The following figure shows the relation between price and profit.
{kind=link}
Conclusion
Adspert’s existing approach to profit maximization is focused on bid management to increase the returns from advertising. To achieve superior performance on ecommerce marketplaces, however, sellers have to consider both advertising and competitive pricing of their products. With this new ML model to predict visibility, we can extend our functionality to also adjust customer’s prices.
The new pricing tool has to be capable of automated training of the ML model on a large amount of data, as well as real-time data transformations, predictions, and price optimizations. In this post, we walked through the main steps of our price optimization engine, and the AWS architecture we implemented in collaboration with the AWS Data Lab to achieve those goals.
Taking ML models from concept to production is typically complex and time-consuming. You have to manage large amounts of data to train the model, choose the best algorithm for training it, manage the compute capacity while training it, and then deploy the model into a production environment. SageMaker reduced this complexity by making it much more straightforward to build and deploy the ML model. After we chose the right algorithms and frameworks from the wide range of choices available, SageMaker managed all of the underlying infrastructure to train our model and deploy it to production.
If you’d like start familiarizing yourself with SageMaker, the Immersion Day workshop can help you gain an end-to-end understanding of how to build ML use cases from feature engineering, the various in-built algorithms, and how to train, tune, and deploy the ML model in a production-like scenario. It guides you to bring your own model and perform an on-premise ML workload lift-and-shift to the SageMaker platform. It further demonstrates advanced concepts like model debugging, model monitoring, and AutoML, and helps you evaluate your ML workload through the AWS ML Well-Architected lens.
If you’d like help accelerating the implementation of use cases that involve data, analytics, AI and ML, serverless, and container modernization, please contact the AWS Data Lab.
About the authors
Viktor Enrico Jeney is a Senior Machine Learning Engineer at Adspert based in Berlin, Germany. He creates solutions for prediction and optimization problems in order to increase customers’ profits. Viktor has a background in applied mathematics and loves working with data. In his free time, he enjoys learning Hungarian, practicing martial arts, and playing the guitar.
{kind=link}
Ennio Pastore is a data architect on the AWS Data Lab team. He is an enthusiast of everything related to new technologies that have a positive impact on businesses and general livelihood. Ennio has over 9 years of experience in data analytics. He helps companies define and implement data platforms across industries, such as telecommunications, banking, gaming, retail, and insurance.
{kind=link}
Read MoreAWS Machine Learning Blog