

{kind=link}
This post is part three of a series, and shows the steps to modernize a legacy SQL Server database to Amazon Aurora PostgreSQL-Compatible Edition using Babelfish. Babelfish is a capability of Amazon Aurora that allows it to understand the SQL Server dialect. In Part 1, we walked you through a step-by-step approach to re-architect a legacy ASP.NET MVC application and port it to .NET Core Framework. In Part 2, we showed how to deploy the previously re-architected application to Amazon Elastic Container Service (Amazon ECS) and run it as a task in the ECS cluster using Amazon Relational Database Service (Amazon RDS) for SQL Server. Now, in this post we show you how modernize the SQL Server database to use Aurora PostgreSQL-compatible by configuring Babelfish and making changes to the SQL code.
Babelfish allows you to run your application against Amazon Aurora PostgreSQL database with a fraction of the code changes required in a traditional migration. You don’t need to change your database drivers. Typically, you can use the same ORM framework.
With Babelfish, you can run T-SQL queries on the Aurora PostgreSQL-compatible engine because a new endpoint is created that understands the Tabular Data Stream (TDS) wire protocol and the SQL Server dialect. Support for T-SQL includes elements such as static cursors, triggers, stored procedures, and functions. Babelfish provides support for some system views and catalogs and extends the PostgreSQL type system to ensure correctness and compatibility with SQL Server data types. This ability to run existing SQL Server code is the biggest difference between Babelfish and traditional migration services, including those offered by AWS, such as conversions using the AWS Schema Conversion Tool (AWS SCT). Although other migration options facilitate the conversion of the database schema from SQL Server to PostgreSQL, they don’t take care of the laborious process of rewriting application code and stored procedures. With Babelfish, the effort required to migrate applications running on SQL Server 2005 (TDS 7.1 wire protocol) or newer to Aurora is greatly reduced. This allows for migrations that are faster, lower risk, and more cost-effective.
Overview of solution
The following diagram illustrates the architecture and tasks we accomplish in this post.
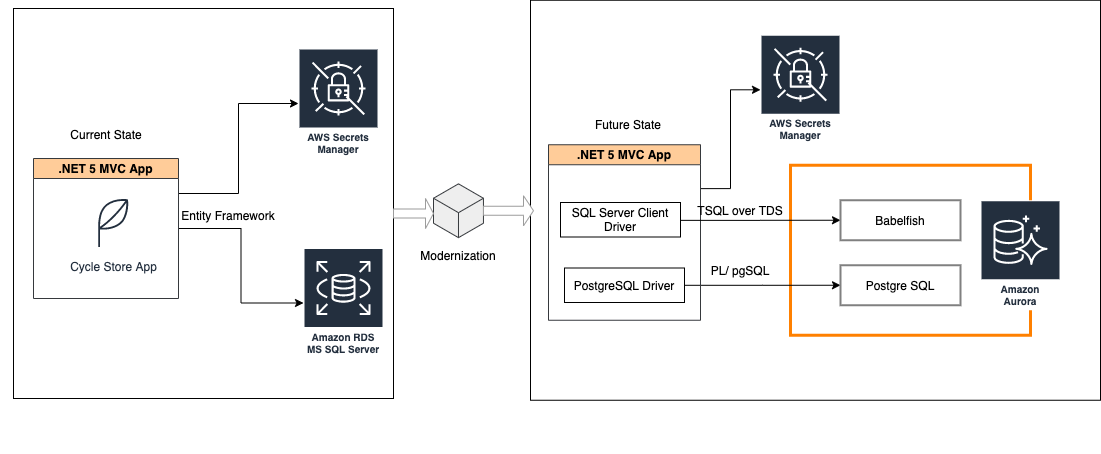{kind=link}
Prerequisites
For this walkthrough, you should have the following prerequisites:
An AWS account.
An AWS Identity and Access Management (IAM) user with privileges to create Security Group, IAM Role, AWS Secrets Manager Secret, Amazon Relational Database Service (Amazon RDS) for SQL Server and AWS CloudFormation service role.
AWS Tools for Windows. For instructions on setting up your AWS profile, see Using AWS Credentials.
.NET Core 5.0 SDK installed. For instructions, see Download .NET 5.0.
Microsoft Visual Studio 2017 or later (Visual Studio code can be an alternative).
SQL Server Management Studio (SSMS) to connect to the SQL Server instance.
ASP.NET application development experience.
This post implements the solution in Region us-east-1.
Source code
Clone the source code from the GitHub repo. The source code folder contains the re-architected source code and the AWS CloudFormation template to launch the infrastructure. All resources but Amazon Aurora cluster, created in this post by the AWS CloudFormation are AWS Free Tier eligible. Please see Amazon Aurora pricing page for current pricing information.
Set up the SQL Server database
To make sure that the application database works out of the box, you can use this CloudFormation template , from the GitHub repo, to create an instance of Microsoft SQL Server Express. It creates AWS Secrets Manager secret to store database user id and generates random password, security groups, and IAM roles required to access the database instance. This stack takes approximately 15 minutes to complete and provision.
Database login password will be auto-generated by AWS Secrets Manager.
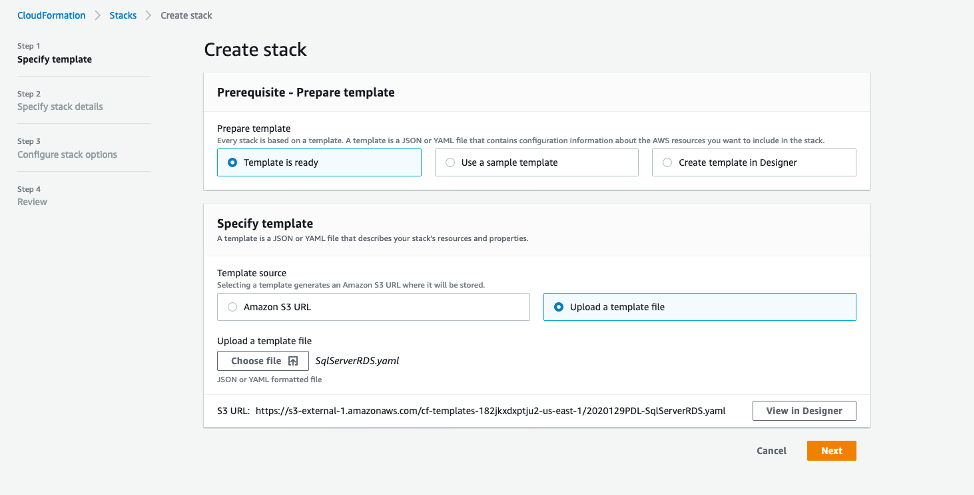
On the AWS CloudFormation console, choose Create stack.
For Prepare template, select Template is ready.
For Template source, select Upload a template file.
Upload SqlServerRDSFixedUidPwd.yaml, which is available in the GitHub repo.
Choose Next.
For Stack name, enter SQLRDSEXStack.
Choose Next.
Keep the rest of the options at their default.
Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
Choose Create stack.
When the status shows as CREATE_COMPLETE, choose the Outputs tab.
Record the value for the SQLDatabaseEndpoint key.
To retrieve the password created by AWS Secrets Manager, navigate to the AWS Secrets Manager Console then open the secret “CycleStoreCredentials”.
Choose “Retrieve secret value” from the page, and copy the password from the secret.
Connect the database from SSMS using the query editor with the following credentials:
User id – dbuser
Password – Use the password copied from the AWS Secrets Manager.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Set up the Cycle Store database
To set up your database, complete the following steps:
We use SQL Server Management Studio (SSMS) to connect to the SQL Server database. To download the latest version of SSMS, see Download SQL Server Management Studio (SSMS).
On the SSMS console, connect to the DB instance using the ID and password you defined earlier.
On the File menu, choose New.
Choose Query with Current Connection.
Alternatively, choose New Query on the toolbar.
{kind=link}
Open CYCLE_STORE_Schema_data.sql from the GitHub repository and run it.
This creates the CYCLE_STORE database with all the tables and data you need.
Run the Cycle Store web application
To set up your ASP.NET application, complete the following steps:
Open the re-architected application code that you cloned from the GitHub repo.
The Dockerfile added to the solution enables Docker support.
Open the appsettings.Development.json file and replace the RDS endpoint in the ConnectionStrings section with the output of the CloudFormation stack.
The ASP.NET application should now load with bike categories and subcategories, as in the following screenshot.
{kind=link}
Set up Babelfish for Aurora PostgreSQL
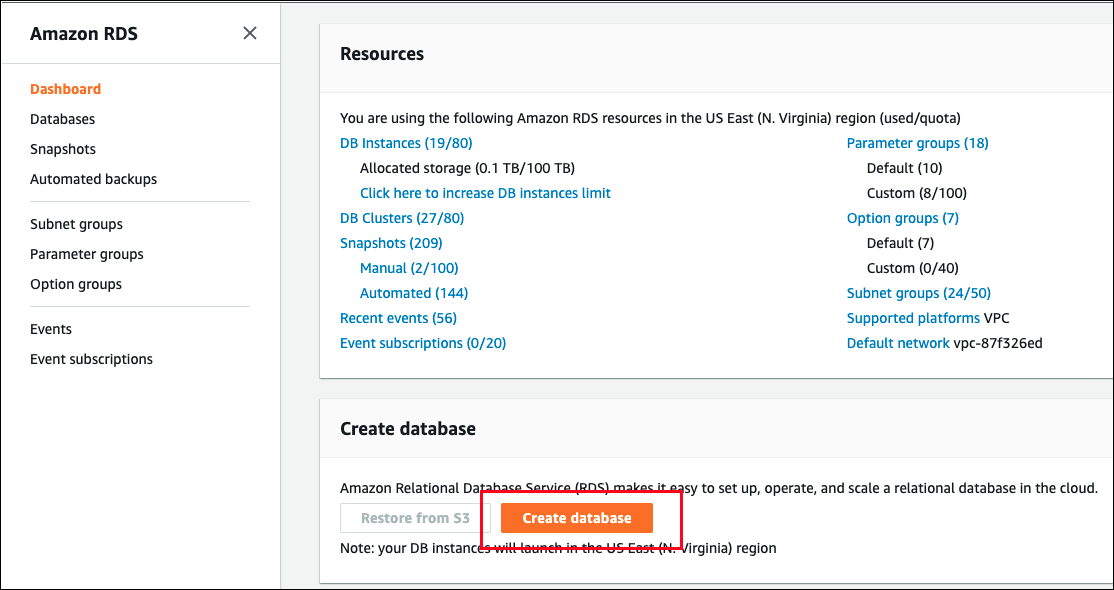
Complete the following steps on the Amazon RDS console to create a Babelfish cluster:
Choose Create database.
Choose Amazon Aurora as the engine type.
Choose the default Capacity type Provisioned
Expand Hide filters and select Show versions that support the Babelfish for PostgreSQL feature.
Choose Aurora PostgreSQL (Compatible with PostgreSQL 13.4)
Choose the Production template.
For DB cluster identifier, enter dev-cluster.
For Master username, enter dbuser.
For Master password, enter the password retrieved previously from AWS Secrets Manager
For DB instance class, choose db.r5.large.
For this instance, choose Don’t create an Aurora Replica as the Availability & Durability setting.
{kind=link}
You can also choose Create an Aurora Replica if you want Aurora to maintain a standby replica DB instance. This provides for automatic failover if an outage occurs on the primary DB instance.
Use the following connectivity settings:
Choose the default virtual private cloud (VPC).
Use the subnet group for the default VPC you selected.
Choose No for Public access configuration so Aurora doesn’t assign a public IP address to the DB cluster.
Choose No for Availability Zone.
Keep 5432 for the Database port.
Check “Turn on Babelfish” under “Babelfish settings”
Choose Password authentication.
Use the following as Additional configuration settings:
For Initial database name, enter cycle_store.
Choose default.aurora-postgresql13 for the DB cluster parameter group and the DB parameter group. The Option group is preset to default.aurora-postgresql13 for Babelfish.
Choose No preference for Failover priority.
Deselect Enable encryption and Enable Performance Insights
Deselect Enable auto minor version upgrade and choose No preference for the maintenance window.
Select Enable deletion protection to protect your database from being deleted by accident. If you enable this feature, you can’t directly delete the database; instead you need to modify the database cluster and disable this feature before deleting the database.
Select the acknowledgment check box and choose Create database.
You can find your new Babelfish-enabled database on the Databases list. It might take some time for the status of the DB cluster to become available.
Migrate data to the PostgreSQL database
In this procedure, you connect to your Aurora PostgreSQL database by using SQL Server Management Studio (SSMS). You must choose New Query or use the query editor to connect to a Babelfish database in SSMS. Do not use the New Connection menu option.
Start SQL Server Management Studio.
Open the Connect to Server dialog by doing one of the following:
Choose New Query.
If the query editor is open, choose Query, Connection, Connect.
For Server type, choose Database Engine.
For Server name, enter the DNS name. For example, your server name should look similar to the following: cluster-name.us-east-1.rds.amazonaws.com.
For Authentication, choose SQL Server Authentication.
For Login, enter the user name that you chose to use when you created your database.
For Password, enter the password that you chose when you created your database.
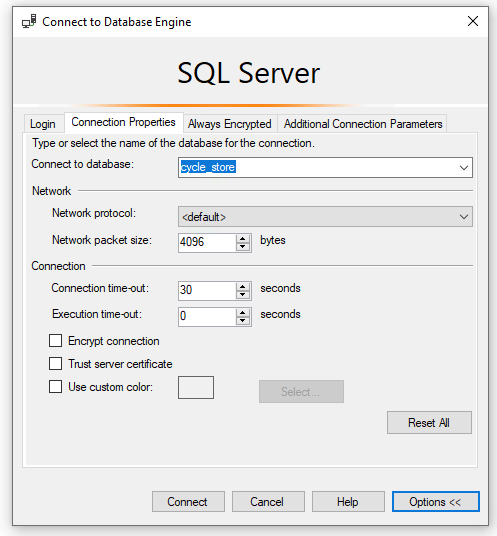
On the Connection Properties tab, enter the database name.
Download and run CYCLE_STORE_Schema_data.sql to create the schema and populate data to the cycle_store database in the Babelfish for Aurora PostgreSQL cluster.
{kind=link}
{kind=link}
This is the same script you used to create the schema and data for the RDS for SQL Server DB CYCLE_STORE.
Redirect existing application
To point the application to the RDS Babelfish for Aurora PostgreSQL DB, complete the following steps:
Open the CycleStoreMVCCore.Web solution in Visual Studio.
Open the appsettings.Development.json file.
Comment out the line that is pointing to the RDS for SQL Server Express DB:
Add the connection string, which is now pointing to the Babelfish for Aurora PostgreSQL DB:
Run the application.
The following screenshot shows the updated view.
{kind=link}
Cleaning up
To avoid incurring future charges, on the AWS CloudFormation console, delete the stack created for this post. In order to do so
Open the AWS CloudFormation console.
On the Stacks page in the CloudFormation console, select the stack that you created for this post.
In the stack details pane, choose Delete.
Select Delete stack when prompted.
To delete Aurora DB cluster created for this post follow instructions to Delete an Aurora DB cluster.
Conclusion
This concludes Part 3 of this series. In this post, we demonstrated using Babelfish for Aurora PostgreSQL to migrate a .NET MVC application to Aurora PostgreSQL-Compatible Edition. In Part 1 of this series, we converted a legacy MVC enterprise application built on the .NET framework to run in a Linux container by using in-place refactoring. In Part 2, we deployed the same application to an ECS cluster, which was still connected to SQL Server. In this post, we further modernized the application by using Babelfish for Aurora PostgreSQL.
To learn more about modernization pathways, please email [email protected]. Also, check out our .NET on AWS page for recent updates.
About the Authors
{kind=link}
Vin Dahake is Sr Manager at AWS leading the Strategic Horizontal team. He helps manage and drive joint Strategic Deals between GSI partners and AWS by identifying specific customer segments and industry verticals to approach with a joint value proposition for using AWS. He helps to set a strategic business & technology plan that drives development of repeatable assets, solutions, products & accelerators which are scalable, secure, and highly available AWS solutions.
Pratip Bagchi is a Sr. Partner Solutions Architect with Amazon Web Services. He works with enterprise customers and partners to modernize their legacy applications, workloads and helps them to build reliable, secured and maintainable enterprise architecture on the AWS platform.
{kind=link}
Read MoreAWS Database Blog