

{kind=link}
This is a guest blog post by Mukesh Mishra, IT Architect at HP Inc.
HP Inc’s vision is to create technology that makes life better for every customer and partner, and we strive hard to simplify the customer experience across product lines and services. HP offers a broad portfolio of printers across different customer segments, including home and small and medium business (SMB). We noticed that many of these customers shared common challenges, especially customers with high printing volumes. They lacked a timely, simplified, and automated way to identify when their ink levels were low, where to buy the right compatible ink for their respective printer, and how to buy supply proactively through an integrated purchase experience to ensure their business wasn’t impacted.
We saw an opportunity to enhance the customer experience of replenishing printer supplies by building a solution that could deliver ink to customers’ doorsteps before they even run out of ink. The solution, HP Easy ink, which is the subject of this post, monitors the ink levels in the printer and, when the ink drops below a certain threshold, notifies the customer as well as an integrated retail partner or HP branded store who can deliver it in the shortest possible time.
The solution offers three key value propositions for users:
Receive low-on-ink notifications through their preferred media
Avoid the hassle of finding the right cartridge for their printer
Same-day doorstep delivery
HP monitors printer ink usage by capturing device telemetry data from printers. The telemetry data uses JSON as its de-facto format, and poses some challenges due to data volume and device connectivity. Furthermore, we need to store and retrieve compatibility data for customer printers and printer supplies in near-real time, adding even more complexity to the picture.
To support the complex data requirements for this solution, the HP Easy ink team started with a self-hosted MongoDB database in our prototyping days. However, we needed a more scalable document database service in order to go into production. In this post, I discuss how we migrated from our self-hosted MongoDB database to Amazon DocumentDB (with MongoDB compatibility). I also share the benefits that we achieved using Amazon DocumentDB.
Solution overview
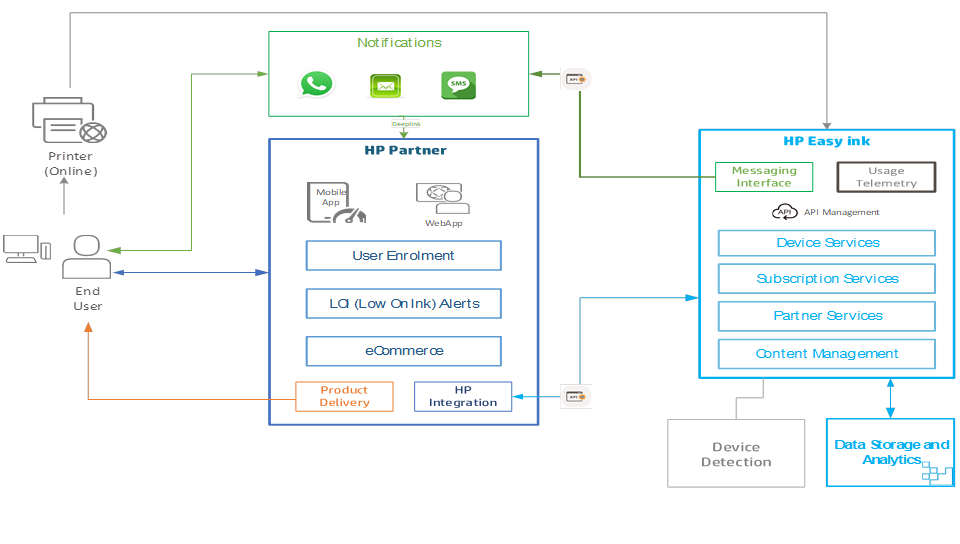
In this section, we provide a solution overview capturing all key entities and services and their relationships. The solution works on the premise of shared responsibilities between HP and participating HP partners. All the customer interactions—like customer enrollment, notification to customers when a printer is running low on link, and helping customers buy ink through ecommerce platforms—are hosted and maintained by a partner through a web or mobile experience.
HP Smart Ordering (SMO) services act as a backend engine in the form of headless RESTful APIs exchanging information with partners and, in some cases, sending notifications based on a user’s preferred channel (such as WhatsApp) and agreed consent. HP’s device connectivity services connect to enrolled printers and capture the telemetry data required for the SMO service layer, which then applies business rules and generates low-on-ink alerts for partners and customers. The device data varies across product lines and therefore the schema needs to be flexible while storing and retrieving data. This dataset is further aggregated with other relevant data types, such as device reference data, subscription and partner management data, notifications, and product detections.
The front end for these APIs is either a mobile app or a web app interacting with users in real time. To ensure optimal user experience, it’s important to have a database that can process these API requests with very low latency for response time.
Besides the variety of data and low latency, we also required scalability and flexibility due to the organic planned growth of the solution as we add new capabilities and onboard partners with different IT maturity levels and countries on a regular basis.
The Smart Ordering solution uses Amazon DocumentDB to support the “Data Storage and Analytics” solution component shown in the following diagram. Here, we use Amazon DocumentDB for transactional purposes (to support all internal or external API services and integrations) as well as some analytics use cases such as analyzing the subscriptions trend and usage behavior for continuous improvement of the solution based on user consent.
{kind=link}
Why DocumentDB?
Considering all the requirements we discussed, it was important to have a fast, highly available, and scalable data storage and retrieval service that could support flexible schema, with a rich query language for dynamic querying and efficient cache management.
Our first decision point was based on whether to choose a SQL (relational) vs. NoSQL (nonrelational) database. In this use case, we had well-structured data for subscriptions, partners, and operational data, but also semi-structured data for device telemetry. In some cases, the customer or printer data structure captured also demanded flexible schema based on how each partner is deploying their front end. Fixed schema wasn’t an option—the data structure would require adjustments to the entities and attributes based on printer product lines and partners, because different product lines and partners have different data structures. For example, we needed to co-relate printer telemetry with printer subscription data. We needed the flexibility to build querying functionality into the application layer instead of the database layer.
Database capabilities such as indexing for optimizing queries and aggregation for analytics were also important. With these considerations, we decided to use a document-oriented NoSQL database. The next obvious question was, which document database should we use?
First, for MongoDB-compatible options, we evaluated Amazon DocumentDB and another third-party managed MongoDB service. From a feature parity perspective, we found that Amazon DocumentDB offered all the features required for our application. Because we were planning to host the solution on AWS, we removed the third-party service in the early stages of our evaluation, to avoid any potential interoperability issues and additional costs related to support and maintenance.
Next, we compared Amazon DynamoDB and Amazon DocumentDB. We selected Amazon DocumentDB because it supports aggregation pipelines and reduces the transformation work on the application side.
In our earlier iterations, we validated MongoDB functional features such as schema flexibility, indexing, range-based queries, and regular expressions against our business and technical requirements using a self-hosted MongoDB database on premises. Then, to evaluate non-functional capabilities such as performance parameters, hardware requirements, security, and administration effort, we migrated the on-premises MongoDB database to an Amazon Elastic Compute Cloud (Amazon EC2) instance, and provisioned on Amazon DocumentDB for comparison. We didn’t have definitive volume or capacity requirements for the solution, so there were no performance benchmarks. We defined some basic evaluation parameters such as operation runtime, disk and memory utilizations, CPU utilizations, and network utilizations. We used native MongoDB utilities such as server status, logging, and operating system parameters configured to collect this data. All these were tested with approximately 10,000 documents for single read, single write, and aggregation.
During this process, we realized that significant effort was required to set up, reconfigure, and run tests with self-managed MongoDB. Meanwhile, fully managed Amazon DocumentDB was a boon, with no installations or setup requirements, no server management, and no manual scripting for monitoring metrics. Additionally, we could easily scale Amazon DocumentDB up or down vertically by adjusting instances used with cluster configurations. We also had a vision to deploy the solution to many partners and countries whose volumes weren’t clearly known, so we needed horizontal scale capability for the database to support dynamic workloads. Additionally, we needed speed, because all the integrations were in real time.
We believed a document database was a great fit for this solution, and Amazon DocumentDB, with its control over data locations, load balancing, high availability via replica sets, auto failover, and optimal costs with a pay-per-use pricing model, met most of our requirements. The fact that DocumentDB is a fully managed service from AWS was the icing on the cake because it removed operational overhead for the team managing databases and shifted the heavy lifting to AWS.
Application architecture
The following diagram shows a solution overview for Smart Ordering (SMO). The flow starts with the HP partner sending enrollment data captured from customers to HP using a JSON format through RESTful APIs. AWS WAF (Web Application Firewall) is set up here for source authenticity to allow traffic only from designated partner systems. AWS WAF also helps with other common security protection issues by defining rules based on HTTP request headers, helping to drop malformed requests. Complementing this, we also implemented custom OAuth2 services to control access and authorization for each partner with a specific API services scope.
Requests are load balanced across multiple Availability Zones using Application Load Balancer and AWS Auto Scaling for redundancy and decoupling of services. The application is deployed on Amazon EC2 with a NodeJS/Express environment, which exposes RESTful APIs to partners and device data, and integrates with Amazon DocumentDB on the backend.
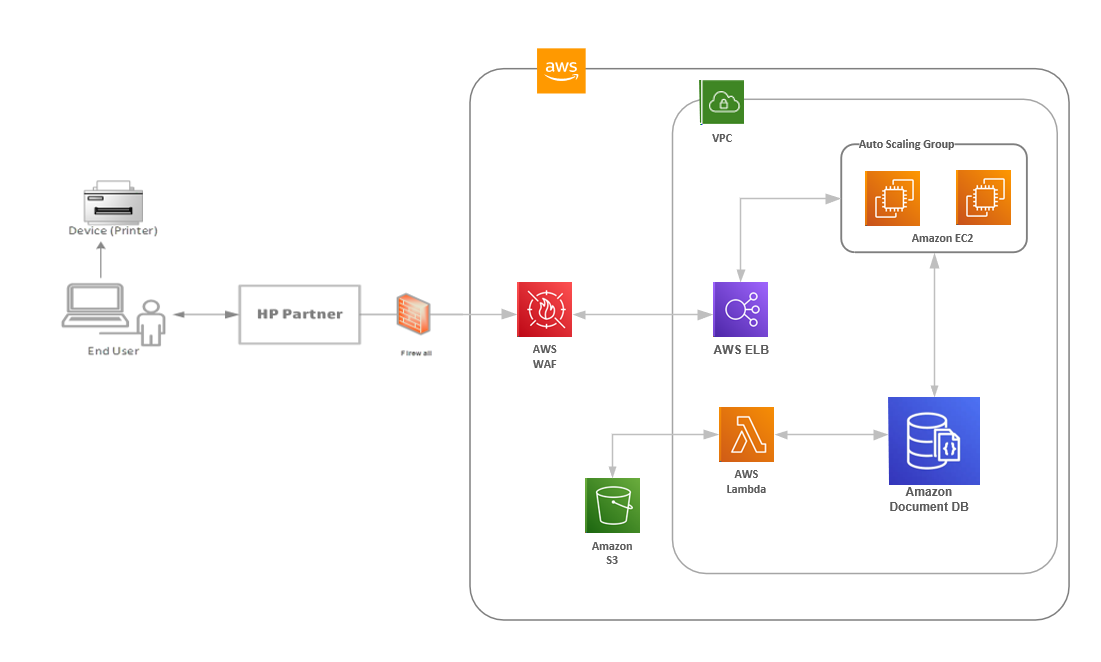{kind=link}
We have been running this application for almost 2 years using on-demand EC2 instances and are in the process of migrating to serverless offerings such as AWS Lambda and Amazon API Gateway. Our plan is to host all backend integrations using Lambda and manage front-end external APIs with an API Gateway layer. We use Amazon Simple Storage Service (Amazon S3) for storing reference data used by the application along with core datasets such as product reference data. This dataset is consumed by the application and finally transformed and stored with Amazon DocumentDB.
Our infrastructure consists of clusters of Amazon DocumentDB and multiple EC2 instances. We deploy Amazon DocumentDB within an Amazon Virtual Private Cloud (Amazon VPC) and limit access using security groups. Our data-in-transit encryption requirements are met by enabling TLS, and our data-at-rest encryption is met by using Amazon DocumentDB’s native integration with AWS Key Management Service (AWS KMS). Amazon DocumentDB credentials are managed through AWS Secrets Manager, and AWS Identity and Access Management (IAM) roles are in place to ensure role-based access for Amazon DocumentDB resources. IAM credentials are regularly rotated.
We designed our schema by de-normalizing the data model to minimize joins and, if required, join only while writing. Amazon DocumentDB makes it straightforward to embrace changes when changes are made to data model. Changes to the schema or modifying multiple documents as and when required has been very useful with our use cases, such as finding multiple printers and updating their related subscriptions or supplies.
We have enabled auto backup for fast recovery in case of data loss and data retention policies to archive with Amazon S3 Glacier. This helps reduce the workload on transactional databases by keeping only what is needed and reducing cost. All API calls to Amazon DocumentDB from a data access layer (DAL) are being implemented in the application with different categories and specific requirements. For example, the DAL for partner APIs are fast queries that need to be responded to in real time (expected response time approximately 600 milliseconds), and an approximate volume of 4,000 operations per hour. This required also a consideration of an 80/20 ratio for reads vs. writes (for example, a user enrolling in the application or checking their ink usage before they buy supplies, where not responding in real time) results in a bad customer experience and impacts overall program goals. For such requirements, we chose an instance type that could fit our working set in memory, and set up metrics and alerts with Amazon CloudWatch to keep us informed about resource consumption and Amazon DocumentDB real-time operations. We scale up appropriate compute resources based on capacity data reflected by these CloudWatch metrics.
Another set of DAL services are offline calls, either to a device telemetry data source or by a reporting layer that doesn’t need a real-time response. We mostly use Amazon DocumentDB for transactional purposes, but we also have an analytical cluster that hosts a subset of data only required for analytics, augmented with related datasets from other sources, consumed by visualization tools and applications. Data transformation is done through custom ETLs, which help create the necessary co-relations.
One of our key learnings was that Amazon DocumentDB offers a fast, flexible, and scalable data storage for our transactional use cases (web and APIs). We can also use it for scalable data analytics (dashboards and reports) with the help of custom data transformation and tools that can transform stored JSON into an analyst-friendly readable format.
One of the best practices to maintain Amazon DocumentDB clusters, from a cost-optimization standpoint, is to stop the clusters when not in use (dev or test clusters) and then start through automated scripts, tagging the clusters in such a way that we know whether the transactional clusters or analytical one is costing us more. We also have a custom tool to budget and set up billing alerts when cost crosses a pre-defined threshold.
Summary
Looking back at when we started as an early adopter to Amazon DocumentDB, it’s been a productive journey that has helped HP a great deal. We were able to cut the cost from self-managed MongoDB by reducing operations and maintenance; this has made us more agile in our delivery while growing with continuous rollouts to various partners in different countries, improving the supply replenishment experience for HP customers. We’re most excited about Amazon DocumentDB because it has helped us reduce maintenance and operations overhead. This has helped us deliver value for our customers and partners faster without worrying about the undifferentiated heavy lifting
Looking forward, we plan to expand our Amazon DocumentDB footprint as we roll out more deployments following the roadmap. We’re also planning to migrate a few other applications with self-managed MongoDB to our set of Amazon DocumentDB clusters.
For additional information on Amazon DocumentDB, be sure to visit the product page.
About the Author
Mukesh Mishra is a Master Information Systems Architect at HP. He works across HP Global Print business functions to enable technologies for evolving business models and digital transformation initiatives. He strongly believes in Data-Driven service design approach where APIs are first-class citizens for developing software products.
Read MoreAWS Database Blog