

{kind=link}
For manufacturers it’s important to track transformations and transfers of products as they travel through the supply chain.
In the event of quality issues, the ability to quickly and accurately identify a defective product and gather data for root cause analysis and containment is critical.
NXP Semiconductors has been working to improve its product traceability capabilities and they have several products that support single device level traceability.
There are billions of devices produced in many variants at various sites across the globe, using multiple IT systems. Connecting key data and manufacturing events at the individual device level opens up many opportunities: from continual quality improvement to overall efficiency and extra supply chain security.
A key component in this approach is the development of an RDF (Resource Description Framework) Knowledge Graph.
NXP originally built a solution using a custom-built RDF data store. This solution required a high level of maintenance and couldn’t scale to work with the variety and quantity of data, so they partnered with Semaku to build a better solution. They migrated from their custom-built RDF data store to Amazon Neptune, a fast, fully managed database service that supports RDF and graph use-cases such as knowledge graphs.
By integrating key data from multiple systems into a common linked data model, NXP’s traceability Knowledge Graph is continuously growing.
In this post, we describe a solution for this use case. We describe how NXP ingests data into Amazon Simple Storage Service (Amazon S3) buckets as CSV or XML files, which triggers AWS Lambda functions using Amazon S3 Event Notifications. The Lambda functions transform the CSV and XML data into RDF data, then load the new RDF data into Neptune by using the Neptune bulk loader and SPARQL UPDATE LOAD.
The following image illustrates the supply chain process and entities stored in Neptune.
{kind=link}
Solution overview
We use the following services in our solution:
AWS Lambda – A serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. You can trigger Lambda from over 200 AWS services and software as a service (SaaS) applications, and only pay for what you use.
Amazon Neptune – A fast, reliable, and fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. It is purpose-built and optimized for storing billions of relationships and querying graph data with millisecond latency.
Amazon Simple Queue Service (Amazon SQS) – A fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications.
Amazon S3 – An object storage service that offers industry-leading scalability, data durability, security, and performance.
Semantic Web Standards
Amazon Neptune supports Semantic Web Standards which include RDF 1.1 and SPARQL 1.1.
Because of this, NXP can use an existing tool (Tarql) to generate RDF data and insert it into Neptune. Data about both production lots and individual devices can then be queried using SPARQL, the standard query language for RDF compatible databases, such as Neptune.
Conversion to RDF
Initial data flows consist of scheduled incremental extracts in CSV format that are ingested into Amazon S3. We use Amazon S3 Event Notifications to invoke a Lambda function that takes care of converting the CSV data to RDF using Tarql.
Streaming data comes in via XML files, generated during the manufacturing process. This data is also put into an S3 bucket, which triggers another Lambda function that performs the following tasks:
Convert the XML into RDF/XML (an XML syntax for encoding RDF) using XSLT 3.0.
Convert the RDF/XML into N-Triples (a line-based, plain text format for encoding RDF) using Apache Jena (an open-source Java framework for working with RDF).
Compress the N-Triples with Gzip.
Write the compressed N-Triples back to Amazon S3.
Currently, we have on average eight of these XML messages arriving per minute, but we expect that to increase as more manufacturing steps and locations are integrated.
{kind=link}
The RDF graphs from the incremental CSV extracts result in thousands to tens of millions of RDF statements. An RDF statement is a triple that may be considered a single database record, encompassing one edge and the origin and destination of that edge. See the following example:
The streaming XML messages are typically around a thousand RDF statements.
The following diagram illustrates our Neptune ingestion architecture.
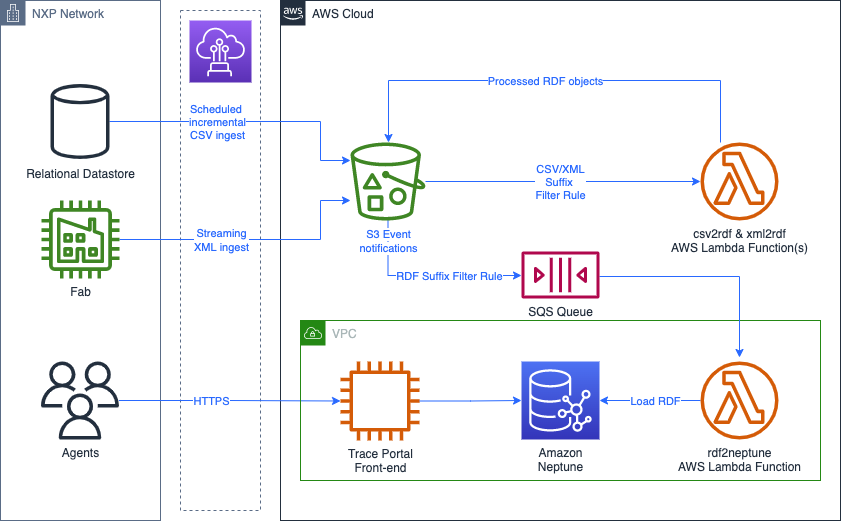{kind=link}
Loading RDF to Neptune using the bulk loader
As part of the migration to Neptune, NXP implemented a process using the Neptune bulk loader to import these N-Triples files into Neptune. For more information about using the bulk loader, refer to Neptune Loader Command.
An RDF named graph (a graph partitioning mechanism for RDF) per S3 object is used to maintain a clear provenance in Neptune of which statements originate from which S3 object. This promotes idempotency and means it’s easy to drop and reload specific named graphs.
The example is very similar to the real data that is loaded when represented in another RDF format, TriG, which supports specifying the named graph within the data file itself.
{kind=link}
RDF named graphs provide a way of contextualizing a subset of the graph. Named graphs in RDF can be directly interacted with a SPARQL 1.1 Query or using SPARQL 1.1 Graph Store HTTP Protocol in Neptune.
The initial implementation sends an S3 event notification, using suffix filters, to an SQS queue upon creation of a Gzipped N-Triples object in Amazon S3. Lambda automatically polls the queue and invokes the function for each message in the queue. The function creates a Neptune bulk load job for each S3 object, where each object is loaded to a distinct named graph in Neptune. This process is depicted in the following figure.
{kind=link}
Although the Neptune bulk loader has a queuing mechanism, this has a maximum queue size of 64 jobs. Given the rate at which the event-based XML messages arrive, we can easily fill the bulk loader queue when a long-running import is in progress. The SQS queue acts as a pre-queue such that if the Lambda function fails to create a bulk load job, it exits with an error code and the message isn’t deleted from the SQS queue. We configure a visibility timeout of 5 minutes in the SQS queue, after which the message becomes visible and is reprocessed. This gives Neptune the chance to work through the bulk load queue and makes sure all files are eventually loaded. The logs are monitored for error codes, so that we can take action should a message continue to error indefinitely.
Based on empirical data gathered running in the production environment for several weeks, we observed this implementation can import up to 18 of the smaller event files per minute under sustained load pressure. Interestingly, the size of the Neptune writer instance doesn’t seem to influence this rate, as can be observed in the following figure (blue indicates messages being processed, orange shows messages queued for processing).
{kind=link}
This figure shows the total approximate number of messages (visible and not visible) in the SQS queue (objects for which bulk load jobs aren’t yet created). During this period, two large incremental files were imported, which the bulk import jobs take a few hours to complete. Because the event-based XML messages continue to arrive while these imports are in progress, this causes a large queue to form in Amazon SQS. When those large imports complete, the maximum import rate is represented by the downward slope gradient after large incremental files were imported. The left peak was loaded using an r5.24xlarge writer instance, and the right peak was loaded using an r5.large write instance.
Given that the import rate is higher than the current eight files per minute rate at which the event-based messages arrive in Amazon S3, the queue is naturally emptied given sufficient time. However, if the arrival rate increases above the import rate, the Neptune import won’t be able to keep up. To be able to handle the increased rate we expect, we wanted to find a way to increase the import rate.
Improving concurrency of imports
To improve concurrency, first we need to understand any bottlenecks in the current process. The Neptune bulk loader breaks up large files for concurrent loading or can load multiple files in a job concurrently. However, for the smaller files, there is no concurrent processing happening within a single bulk load job. We assume the smaller files aren’t broken up into smaller chunks, and therefore don’t benefit from the concurrent loading. Essentially, only a single thread is used for these bulk load jobs. Because the processing of the bulk loader jobs is serialized, this fits the observation that using larger instances doesn’t improve import rates. We needed to find a way to enable the imports to be processed concurrently.
We considered a couple of possible solutions:
Process multiple event-based objects in a single bulk load job
Use SPARQL UPDATE LOAD to import the event-based objects rather than the Neptune bulk loader because it may be more efficient for small individual RDF files
Option 1: Process multiple event-based objects in a single bulk load job
For this option, we need to consider named graph management. When using the Neptune bulk loader, the named graph is specified when the HTTP request is made to initiate the load. Because we want to load data containing multiple named graphs, we can’t specify the named graph when initiating the load.
To overcome this issue, we can convert the RDF data to a format that supports named graph’s within the data itself.
The RDF format N-Quads adds a fourth element (the named graph) to an N-Triple.
For example, we can start with the following N-Triple:
And it becomes an N-Quad:
Therefore, to keep the graph-per-S3-object approach, the data needs to be converted to N-Quads prior to import.
We did consider changing the topology of the named graphs to, for example, load all files for a given date into the same named graph, but it quickly became apparent that we needed to keep the graph-per-S3-object approach because the context of the event can be relevant when querying, which is represented by the graph boundary.
An added benefit to having the named graphs specified in the data (using N-Quads) is that all the data can be combined into a small number of large files, rather than a large number of small files. The Neptune bulk loader is most efficient and fastest when loading a small number of large files.
This would be possible to implement using batch processing of messages from the SQS queue. However, we felt this batch processing would add complexity and latency in the processing, which we prefer to keep as close to real time as possible.
Option 2: Use SPARQL UPDATE LOAD to import the event-based objects
For this option, we prototyped a Python script using a Neptune notebook. The script uses the Boto3 library to generate presigned URLs for the S3 object and constructs a SPARQL UPDATE procedure in the following form:
With this approach, we observed that imports using SPARQL UPDATE LOAD complete individually about 10 times faster than for the same file loaded via the Neptune bulk loader (around 300 milliseconds vs. 3,000 milliseconds).
Based on this finding, we extended the Lambda function to support both the Neptune bulk loader and SPARQL UPDATE LOAD protocols to import data to Neptune.
By adding a SIZE_THRESHOLD environment variable, it’s now possible to control which protocol is used for the import based on the size of the file being imported. Files below the threshold (which we configured as 200,000 bytes) are imported using SPARQL UPDATE LOAD, and those above the threshold using the bulk loader.
The event-based files and some of the incremental files are below this threshold and able to import synchronously using SPARQL UPDATE LOAD. The larger (incremental) files are imported using the Neptune bulk loader, which is able to effectively split those into chunks for improved concurrency.
We feel this approach strikes a good balance to use the right protocol for the right job. The new approach also means we never come close to filling the Neptune bulk loader queue, so we could remove the SQS pre-queue. So now the S3 event notification is asynchronously processed by Lambda when an RDF file is created, as depicted in the following figure.
{kind=link}
Neptune is able to process multiple SPARQL requests in parallel. The maximum number of queries that can be running at one time is determined by the number of worker threads assigned, which is generally set to twice the number of vCPUs that are available. For more information, refer to Query queuing in Amazon Neptune.
We’re using a db.r5.large writer instance, so we have up to four threads available. To avoid keeping all those threads busy, we limit concurrency on the Lambda function to two concurrent invocations. This ensures there are always some threads available to handle queries and any bulk loads.
With this configuration, we can import up to 450 event-based files per minute. This provides plenty of headroom for the immediate future.
However, we were interested to see if the speedup with an increased number of processors would follow Amdahl’s law or Gustafson’s law.
To do this measurement, we varied the size of the Neptune writer instance and concurrency of the Lambda function to match the number of available worker threads. The experiment was conducted by reprocessing 88,422 files, representing 2 weeks’ worth of production data. The data was imported to a database, which was reset at the start of every run, using Neptune engine version 1.1.0.0. Reprocessing was done by copying the files to the current location in Amazon S3 using the AWS Management Console in order to retrigger the S3 event notifications. For the experiments, we first queued all the S3 event notifications using Amazon SQS, to ensure the rate of moving the files in Amazon S3 didn’t become the bottleneck, and the Lambda function read from the queue. The following table summarizes our findings.
Instance Type
vCPU
Concurrency
Total Duration (hh:mm:ss)
Peak Rate (invoc/min)
Average Rate (invoc/min)
Average duration (ms)
Speedup Factor
db.r5.large
2
2
04:09:17
450
355
159
1.98
db.r5.large
2
4
02:27:04
834
601
229
3.35
db.r5.xlarge
4
8
01:06:49
1663
1323
237
7.37
db.r5.2xlarge
8
16
00:29:08
3419
3035
222
16.91
db.r5.4xlarge
16
32
00:16:14
6125
5447
255
30.36
db.r5.8xlarge
32
64
00:11:13
8910
7883
346
43.93
db.r5.12xlarge
48
96
00:10:49
9351
8175
501
45.56
db.r5.16xlarge
64
128
00:11:10
8618
7966
715
44.13
db.r5.24xlarge
96
192
00:11:45
8240
7525
1015
41.94
The following figure plots the speedup factor (log) and average duration of the Lambda function (linear) vs. concurrency (log).
{kind=link}
We can see the relation between speedup and concurrency is linear up to 32 concurrent queries before maxing out at around 45 times speedup with higher concurrencies. According to Amdahl’s law, this would indicate that nearly 100% of the process can be parallelized. However, at the higher concurrencies, it appears the speedup is ultimately limited by some serial part of the program. The increase in the duration of the Lambda function at those higher concurrencies indicates that those import requests are being queued by Neptune.
Conclusion
In this post, we showed how to build a Knowledge Graph of billions of devices to quickly and accurately identify defective products and gather data for root causes, in order to contain and identify defective components, which is vital for supply chain efficiency and product reliability.
We demonstrated that Neptune is able to handle high near-real-time write pressure from event-based messages without the need to batch/club imports into a bulk load job and any latency that would introduce. For files larger than 200 KB, the Neptune bulk loader is a better choice.
The transactional nature of Neptune gives clarity if individual SPARQL UPDATE requests have succeeded or failed. Understanding the capabilities of the service and which import protocol is applicable for your use case is important to achieve optimal performance.
To further simplify the process, NXP is exploring SPARQL 1.1 Graph Store Protocol (GSP) support in Neptune.
Using GSP for this solution, we could add the RDF data to the body of an HTTP request, and POST or PUT that data into Neptune via HTTP directly from the Lambda function.
About the authors
John Walker is co-founder and director of Semaku. John is passionate about bringing the benefits of linked data and semantic technologies into the enterprise world. Semaku was founded in 2013 and offers information management services leveraging cloud and graph technologies to help clients see the big picture with a unified approach.
{kind=link}
Onno Buijs is a Director at NXP Semiconductors responsible for Quality Information Systems. Onno has more than 20 years of experience leading IT solution development programs and transformations in the high-tech industry.
{kind=link}
Javy de Koning is a Senior Solutions Architect for Amazon Web Services. He has 15 years of experience designing enterprise scale distributed systems. His passion is designing microservice architectures that can take full advantage of the cloud and DevOps toolchains.
{kind=link}
Charles Ivie is a Senior Graph Architect with the Amazon Neptune team at AWS. He has been designing, implementing and leading solutions using knowledge graph technologies for over ten years.
{kind=link}
Read MoreAWS Database Blog