

{kind=link}
Purpose
Processing streaming data to extract insights and powering real time applications is becoming more and more critical. Google Cloud Dataflow and Pub/Sub provides a highly scalable, reliable and mature streaming analytics platform to run mission critical pipelines. One very common challenge that developers often face when designing such pipelines is how to handle duplicate data.
In this blog, I want to give an overview of common places where duplicate data may originate in your streaming pipelines and discuss various options that are available to you to handle them. You can also check out this tech talk on the same topic.
Origin of duplicates in streaming data pipelines
This section gives an overview of the places where duplicate data may originate in your streaming pipelines. Numbers in red boxes in the following diagram indicate where this may happen.
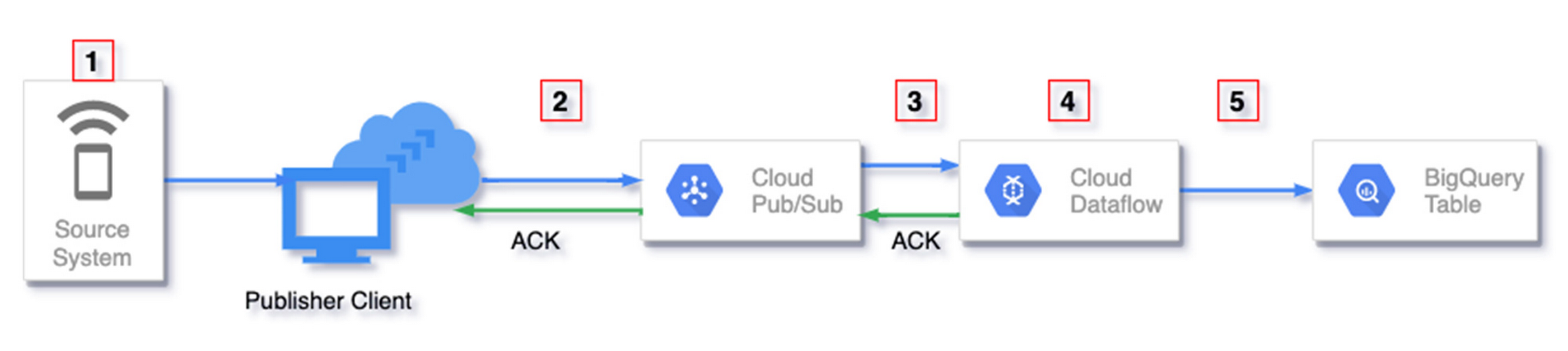{kind=link}
Some duplicates are automatically handled by Dataflow while for others developers may need to use some techniques to handle them. This is summarized in the following table.
{kind=link}
Your data source system may itself produce duplicate data. There could be several reasons like network failure, system errors etc that can produce duplicate data. Such duplicates are referred to as ‘source generated duplicates’.
One example where this could happen is when you set trigger notifications from Google Cloud Storage to Pub/Sub in response to object changes to GCS buckets. This feature guarantees at-least-once delivery to Pub/Sub and can produce duplicate notifications.
2. Publisher generated duplicates
Your publisher when publishing messages to Pub/Sub can generate duplicates due to at-least-once publishing guarantees. Such duplicates are referred to as ‘publisher generated duplicates’.
Pub/Sub automatically assigns a unique message_id to each message successfully published to a topic. Each message is considered successfully published by the publisher when Pub/Sub returns an acknowledgement to the publisher. Within a topic all messages have a unique message_id and no two messages have the same message_id. If success of the publish is not observed for some reason (network delays, interruptions etc) the same message payload may be retried by the publisher. If retries happen, we may end up with duplicate messages with different message_id in Pub/Sub. For Pub/Sub these are unique messages as they have different message_id.
3. Reading from Pub/Sub
Pub/Sub guarantees at least once delivery for every subscription. This means that a message may be delivered more than once by the same subscription if Pub/Sub doesn’t receive acknowledgement within the acknowledgement deadline. The subscriber may acknowledge after the acknowledgement deadline or the acknowledgement may be lost due to transient network issues. In such scenarios the same message would be redelivered and subscribers may see duplicate data. It is the responsibility of the subscribing system (for example Dataflow) to detect such duplicates and handle accordingly.
When Dataflow receives messages from Pub/Sub subscription, messages are acknowledged after they are successfully processed by the first fused stage. Dataflow does optimization called fusion where multiple stages can be combined into a single fused stage. A break in fusion happens when there is a shuffle which happens if you have transforms like GROUP BY, COMBINE or I/O transforms like BigQueryIO. If a message has not been acknowledged within its acknowledgement deadline, Dataflow attempts to maintain the lease on the message by repeatedly extending the acknowledgement deadline to prevent redelivery from Pub/Sub. However this is best effort and there is a possibility that messages may be redelivered. This can be monitored using metrics listed here.
However, because Pub/Sub provides each message with a unique message_id, Dataflow uses it to deduplicate messages by default if you use the built-in Apache Beam PubSubIO. Thus Dataflow filters out such duplicates originating from redelivery of the same message by Pub/Sub. You can read more about this topic on one of our earlier blog under the section “Example source: Cloud Pub/Sub”
4. Processing data in Dataflow
Due to the distributed nature of processing in Dataflow each message may be retried multiple times on different Dataflow workers. However Dataflow ensures that only one of those tries wins and the processing from the other tries does not affect downstream fused stages. Dataflow does guarantee exactly once processing by leveraging checkpointing at each stage to ensure such duplicates are not reprocessed affecting state or output. You can read more about how this is achieved in this blog.
5. Writing to a sink
Each element can be retried multiple times by Dataflow workers and may produce duplicate writes. It is the responsibility of the sink to detect these duplicates and handle them accordingly. Depending on the sink, duplicates may be filtered out, over-written or appear as duplicates.
File systems as sink
If you are writing files, exactly once is guaranteed as any retries by Dataflow workers in event of failure will overwrite the file. Beam provides several I/O connectors to write files, all of which guarantees exactly once processing.
{kind=link}
If you use the built-in Apache Beam BigQueryIO to write messages to BigQuery using streaming inserts, Dataflow provides a consistent insert_id (different from Pub/Sub message_id) for retries and this is used by BigQuery for deduplication. However, this deduplication is best effort and duplicate writes may appear. BigQuery provides other insert methods as well with different deduplication guarantees as listed below.
{kind=link}
You can read more about BigQuery insert methods at the BigQueryIO Javadoc. Additionally for more information on BigQuery as a sink check out the section “Example sink: Google BigQuery” in one of our earlier blog.
For duplicates originating from places discussed in points 3), 4) and 5) there are built-in mechanisms in place to remove such duplicates as discussed above, assuming BigQuery is a sink. In the following section we will discuss deduplication options for ‘source generated duplicates’ and ‘publisher generated duplicates’. In both cases, we have duplicate messages with different message_id, which for Pub/Sub and downstream systems like Dataflow are two unique messages.
Deduplication options for source generated duplicates and publisher generated duplicates
1. Use Pub/Sub message attributes
Each message published to a Pub/Sub topic can have some string key value pairs attached as metadata under the “attributes” field of PubsubMessage. These attributes are set when publishing to Pub/Sub. For example, if you are using the Python Pub/Sub Client Library, you can set the “attrs” parameter of the publish method when publishing messages. You can set the unique fields (e.g: event_id) from your message as attribute value and field name as attribute key.
Dataflow can be configured to use these fields to deduplicate messages instead of the default deduplication using Pub/Sub message_id. You can do this by specifying the attribute key when reading from Pub/Sub using the built-in PubSubIO.
For Java SDK, you can specify this attribute key in the withIdAttribute method of PubsubIO.Read() as shown below.
In the Python SDK, you can specify this in the id_label parameter of the ReadFromPubSub PTransform as shown below.
This deduplication using a Pub/Sub message attribute is only guaranteed to work for duplicate messages that are published to Pub/Sub within 10 minutes of each other.
2. Use Apache Beam Deduplicate PTransform
Apache Beam provides deduplicate PTransforms which can deduplicate incoming messages over a time duration. Deduplication can be based on the message or a key of a key value pair, where the key could be derived from the message fields. The deduplication window can be configured using the withDuration method, which can be based on processing time or event time (specified using the withTimeDomain method). This has a default value of 10 mins.
You can read the Java documentation or the Python documentation of this PTransform for more details on how this works.
This PTransform uses the Stateful API under the hood and maintains a state for each key observed. Any duplicate message with the same key that appears within the deduplication window is discarded by this PTransform.
3. Do post-processing in sink
Deduplication can also be done in the sink. This could be done by running a scheduled job that periodically deduplicates rows using a unique identifier.
BigQuery as a sink
If BigQuery is the sink in your pipeline, scheduled query can be executed periodically that writes the deduplicated data to another table or updates the existing table. Depending on the complexity of the scheduling you may need orchestration tools like Cloud Composer or Dataform to schedule queries.
Deduplication can be done using a DISTINCT statement or DML like MERGE. You can find sample queries about these methods on these blogs (blog 1, blog 2).
Often in streaming pipelines you may need deduplicated data available in real time in BigQuery. You can achieve this by creating materialized views on top of underlying tables using a DISTINCT statement.
Any new updates to the underlying tables will be updated in real time to the materialized view with zero maintenance or orchestration.
Technical trade-offs of different deduplication options
{kind=link}
Cloud BlogRead More