

{kind=link}
Approximately 7,000 languages are in use today. Despite attempts in the late 19th century to invent constructed languages such as Volapük or Esperanto, there is no sign of unification. People still choose to create new languages (think about your favorite movie character who speaks Klingon, Dothraki, or Elvish).
Today, natural language processing (NLP) examples are dominated by the English language, the native language for only 5% of the human population and spoken only by 17%.
The digital divide is defined as the gap between those who can access digital technologies and those who can’t. Lack of access to knowledge or education due to language barriers also contributes to the digital divide, not only between people who don’t speak English, but also for the English-speaking people who don’t have access to non-English content, which reduces diversity of thought and knowledge. There is so much to learn mutually.
In this post, we summarize the challenges of low-resource languages and experiment with different solution approaches covering over 100 languages using Hugging Face transformers on Amazon SageMaker.
We fine-tune various pre-trained transformer-based language models for a question and answering task. We use Turkish in our example, but you could apply this approach to other supported language. Our focus is on BERT [1] variants, because a great feature of BERT is its unified architecture across different tasks.
We demonstrate several benefits of using Hugging Face transformers on Amazon SageMaker, such as training and experimentation at scale, and increased productivity and cost-efficiency.
Overview of NLP
There have been several major developments in NLP since 2017. The emergence of deep learning architectures such as transformers [2], the unsupervised learning techniques to train such models on extremely large datasets, and transfer learning have significantly improved the state-of-the-art in natural language understanding. The arrival of pre-trained model hubs has further democratized access to the collective knowledge of the NLP community, removing the need to start from scratch.
A language model is an NLP model that learns to predict the next word (or any masked word) in a sequence. The genuine beauty of language models as a starting point are three-fold: First, research has shown that language models trained on a large text corpus data learn more complex meanings of words than previous methods. For instance, to be able to predict the next word in a sentence, the language model has to be good at understanding the context, the semantics, and also the grammar. Second, to train a language model, labeled data—which is scarce and expensive—is not required during pre-training. This is important because an enormous amount of unlabeled text data is publicly available on the web in many languages. Third, it has been demonstrated that once the language model is smart enough to predict the next word for any given sentence, it’s relatively easy to perform other NLP tasks such as sentiment analysis or question answering with very little labeled data, because fine-tuning reuses representations from a pre-trained language model [3].
Fully managed NLP services have also accelerated the adoption of NLP. Amazon Comprehend is a fully managed service that enables text analytics to extract insights from the content of documents, and it supports a variety of languages. Amazon Comprehend supports custom classification and custom entity recognition and enables you to build custom NLP models that are specific to your requirements, without the need for any ML expertise.
Challenges and solutions for low-resource languages
The main challenge for a large number of languages is that they have relatively less data available for training. These are called low-resource languages. The m-BERT paper [4] and XLM-R paper [7] refer to Urdu and Swahili as low-resource languages.
The following figure specifies the ISO codes of over 80 languages, and the difference in size (in log-scale) between the two major pre-trainings [7]. In Wikipedia (orange), there are only 18 languages with over 1 million articles and 52 languages with over 1,000 articles, but 164 languages with only 1–10,000 articles [9]. The CommonCrawl corpus (blue) increases the amount of data for low-resource languages by two orders of magnitude. Nevertheless, they are still relatively small compared to high-resource languages such as English, Russian, or German.
{kind=link}
In terms of Wikipedia article numbers, Turkish is another language in the same group of over 100,000 articles (28th), together with Urdu (54th). Compared with Urdu, Turkish would be regarded as a mid-resource language. Turkish has some interesting characteristics, which could make language models more powerful by creating certain challenges in linguistics and tokenization. It’s an agglutinative language. It has a very free word order, a complex morphology, or tenses without English equivalents. Phrases formed of several words in languages like English can be expressed with a single word form, as shown in the following example.
Turkish
English
Kedi
Cat
Kediler
Cats
Kedigiller
Family of cats
Kedigillerden
Belonging to the family of cats
Kedileştirebileceklerimizdenmişçesineyken
When it seems like that one is one those we can make cat
Two main solution approaches are language-specific models or multilingual models (with or without cross-language supervision):
Monolingual language models – The first approach is to apply a BERT variant to a specific target language. The more the training data, the better the model performance.
Multilingual masked language models – The other approach is to pre-train large transformer models on many languages. Multilingual language modeling aims to solve the lack of data challenge for low-resource languages by pre-training on a large number of languages so that NLP tasks learned from one language can be transferred to other languages. Multilingual masked language models (MLMs) have pushed the state-of-the-art on cross-lingual understanding tasks. Two examples are:
Multilingual BERT – The multilingual BERT model was trained in 104 different languages using the Wikipedia corpus. However, it has been shown that it only generalizes well across similar linguistic structures and typological features (for example, languages with similar word order). Its multilinguality is diminished especially for languages with different word orders (for example, subject/object/verb) [4].
XLM-R – Cross-lingual language models (XLMs) are trained with a cross-lingual objective using parallel datasets (the same text in two different languages) or without a cross-lingual objective using monolingual datasets [6]. Research shows that low-resource languages benefit from scaling to more languages. XLM-RoBERTa is a transformer-based model inspired by RoBERTa [5], and its starting point is the proposition that multilingual BERT and XLM are under-tuned. It’s trained on 100 languages using both the Wikipedia and CommonCrawl corpus, so the amount of training data for low-resource languages is approximately two orders of magnitude larger compared to m-BERT [7].
Another challenge of multilingual language models for low-resource languages is vocabulary size and tokenization. Because all languages use the same shared vocabulary in multilingual language models, there is a trade-off between increasing vocabulary size (which increases the compute requirements) vs. decreasing it (words not present in the vocabulary would be marked as unknown, or using characters instead of words as tokens would ignore any structure). The word-piece tokenization algorithm combines the benefits of both approaches. For instance, it effectively handles out-of-vocabulary words by splitting the word into subwords until it is present in the vocabulary or until the individual character is reached. Character-based tokenization isn’t very useful except for certain languages, such as Chinese. Techniques exist to address challenges for low-resource languages, such as sampling with certain distributions [6].
The following table depicts how three different tokenizers behave for the word “kedileri” (meaning “its cats”). For certain languages and NLP tasks, this would make a difference. For instance, for the question answering task, the model returns the span of the start token index and end token index; returning “kediler” (“cats”) or “kedileri” (“its cats”) would lose some context and lead to different evaluation results for certain metrics.
Pretrained Model
Vocabulary size
Tokenization for “Kedileri”*
dbmdz/bert-base-turkish-uncased
32,000
Tokens
[CLS]
kediler
##i
[SEP]
Input IDs
2
23714
1023
3
bert-base-multilingual-uncased
105,879
Tokens
[CLS]
ked
##iler
##i
[SEP]
Input IDs
101
30210
33719
10116
102
deepset/xlm-roberta-base-squad2
250,002
Tokens
<s>
▁Ke
di
leri
</s>
Input IDs
0
1345
428
1341
.
*In English: (Its) cats
Therefore, although low-resource languages benefit from multilingual language models, performing tokenization across a shared vocabulary may ignore some linguistic features for certain languages.
In the next section, we compare three approaches by fine-tuning them for a question answering task using a QA dataset for Turkish: BERTurk [8], multilingual BERT [4], and XLM-R [7].
Solution overview
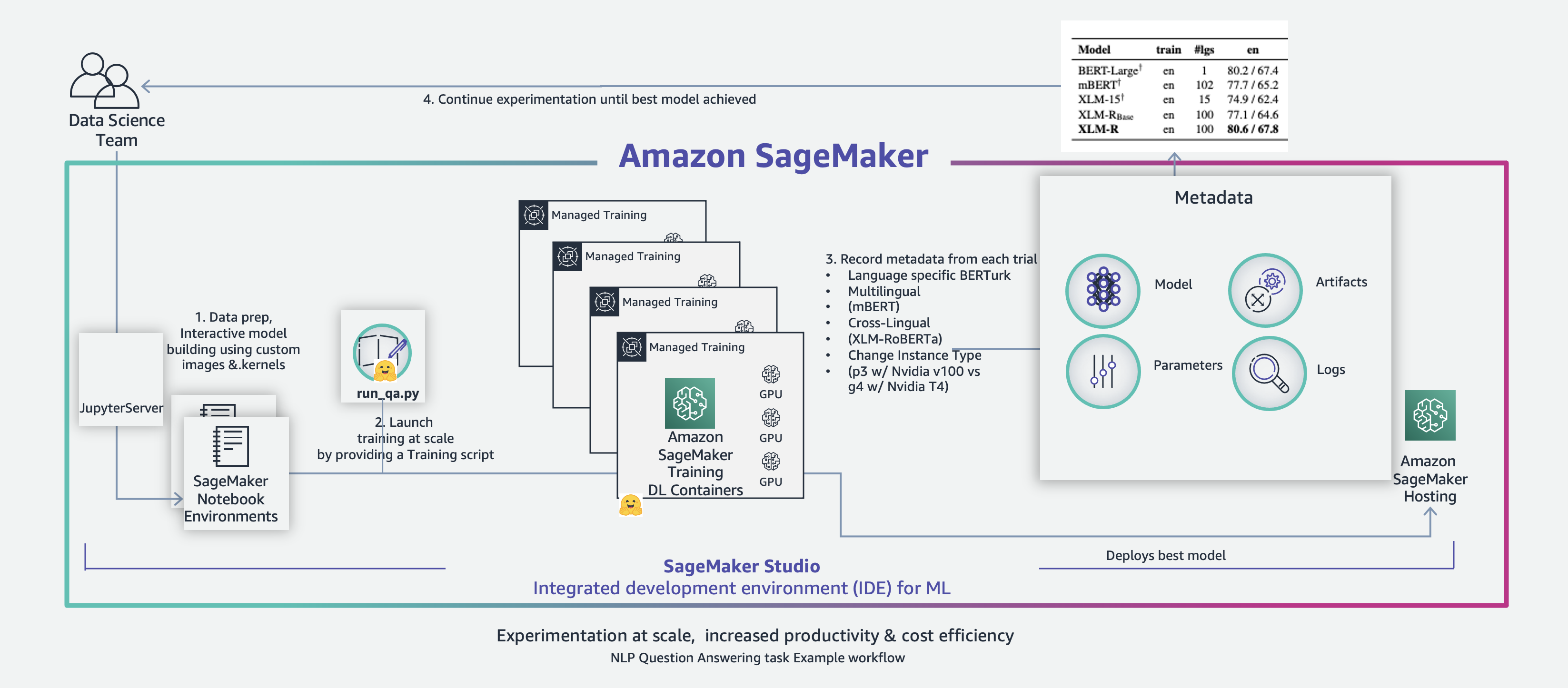
Our workflow is as follows:
Prepare the dataset in an Amazon SageMaker Studio notebook environment and upload it to Amazon Simple Storage Service (Amazon S3).
Launch parallel training jobs on SageMaker training deep learning containers by providing the fine-tuning script.
Collect metadata from each experiment.
Compare results and identify the most appropriate model.
The following diagram illustrates the solution architecture.
{kind=link}
For more information on Studio notebooks, refer to Dive deep into Amazon SageMaker Studio Notebooks architecture. For more information on how Hugging Face is integrated with SageMaker, refer to AWS and Hugging Face collaborate to simplify and accelerate adoption of Natural Language Processing models.
Prepare the dataset
The Hugging Face Datasets library provides powerful data processing methods to quickly get a dataset ready for training in a deep learning model. The following code loads the Turkish QA dataset and explores what’s inside:
There are about 9,000 samples.
{kind=link}
The input dataset is slightly transformed into a format expected by the pre-trained models and contains the following columns:
The English translation of the output is as follows:
{kind=link}
context – Resit Emre Kongar (b. 13 October 1941, Istanbul), Turkish sociologist, professor.
question – What is the academic title of Emre Kongar?
answer – Professor
Fine-tuning script
The Hugging Face Transformers library provides an example code to fine-tune a model for a question answering task, called run_qa.py. The following code initializes the trainer:
Let’s review the building blocks on a high level.
Tokenizer
The script loads a tokenizer using the AutoTokenizer class. The AutoTokenizer class takes care of returning the correct tokenizer that corresponds to the model:
The following is an example how the tokenizer works:
{kind=link}
Model
The script loads a model. AutoModel classes (for example, AutoModelForQuestionAnswering) directly create a class with weights, configuration, and vocabulary of the relevant architecture given the name and path to the pre-trained model. Thanks to the abstraction by Hugging Face, you can easily switch to a different model using the same code, just by providing the model’s name. See the following example code:
Preprocessing and training
The prepare_train_features() and prepare_validation_features() methods preprocess the training dataset and validation datasets, respectively. The code iterates over the input dataset and builds a sequence from the context and the current question, with the correct model-specific token type IDs (numerical representations of tokens) and attention masks. The sequence is then passed through the model. This outputs a range of scores, for both the start and end positions, as shown in the following table.
Input Dataset Fields
Preprocessed Training Dataset Fields for QuestionAnsweringTrainer
id
input_ids
title
attention_mask
context
start_positions
question
end_positions
Answers { answer_start, answer_text }
.
Evaluation
The compute_metrics() method takes care of calculating metrics. We use the following popular metrics for question answering tasks:
Exact match – Measures the percentage of predictions that match any one of the ground truth answers exactly.
F1 score – Measures the average overlap between the prediction and ground truth answer. The F1 score is the harmonic mean of precision and recall:
Precision – The ratio of the number of shared words to the total number of words in the prediction.
Recall – The ratio of the number of shared words to the total number of words in the ground truth.
Managed training on SageMaker
Setting up and managing custom machine learning (ML) environments can be time-consuming and cumbersome. With AWS Deep Learning Container (DLCs) for Hugging Face Transformers libraries, we have access to prepackaged and optimized deep learning frameworks, which makes it easy to run our script across multiple training jobs with minimal additional code.
We just need to use the Hugging Face Estimator available in the SageMaker Python SDK with the following inputs:
Evaluate the results
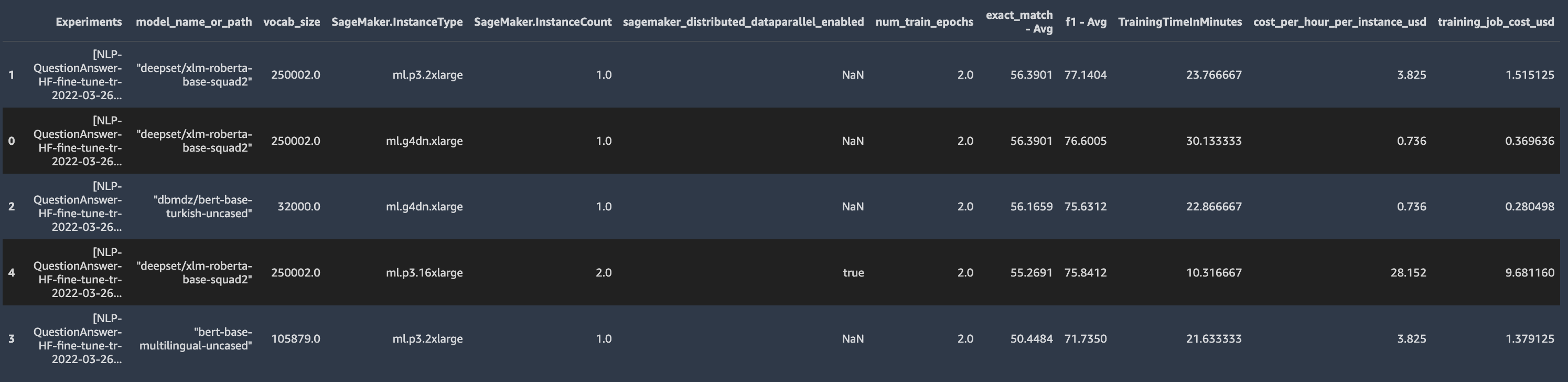
When the fine-tuning jobs for the Turkish question answering task are complete, we compare the model performance of the three approaches:
Monolingual language model – The pre-trained model fine-tuned on the Turkish question answering text is called bert-base-turkish-uncased [8]. It achieves an F1 score of 75.63 and an exact match score of 56.17 in only two epochs and with 9,000 labeled items. However, this approach is not suitable for a low-resource language when a pre-trained language model doesn’t exist, or there is little data available for training from scratch.
Multilingual language model with multilingual BERT – The pre-trained model is called bert-base-multilingual-uncased. The multilingual BERT paper [4] has shown that it generalizes well across languages. Compared with the monolingual model, it performs worse (F1 score 71.73, exact match 50:45), but note that this model handles over 100 other languages, leaving less room for representing the Turkish language.
Multilingual language model with XLM-R – The pre-trained model is called xlm-roberta-base-squad2. The XLM-R paper shows that it is possible to have a single large model for over 100 languages without sacrificing per-language performance [7]. For the Turkish question answering task, it outperforms the multilingual BERT and monolingual BERT F1 scores by 5% and 2%, respectively (F1 score 77.14, exact match 56.39).
{kind=link}
Our comparison doesn’t take into consideration other differences between models such as the model capacity, training datasets used, NLP tasks pre-trained on, vocabulary size, or tokenization.
Additional experiments
The provided notebook contains additional experiment examples.
SageMaker provides a wide range of training instance types. We fine-tuned the XLM-R model on p3.2xlarge (GPU: Nvidia V100 GPU, GPU architecture: Volta (2017)), p3.16xlarge (GPU: 8 Nvidia V100 GPUs), and g4dn.xlarge (GPU: Nvidia T4 GPU, GPU architecture: Turing (2018)), and observed the following:
Training duration – According to our experiment, the XLM-R model took approximately 24 minutes to train on p3.2xlarge and 30 minutes on g4dn.xlarge (about 23% longer). We also performed distributed fine-tuning on two p3.16xlarge instances, and the training time decreased to 10 minutes. For more information on distributed training of a transformer-based model on SageMaker, refer to Distributed fine-tuning of a BERT Large model for a Question-Answering Task using Hugging Face Transformers on Amazon SageMaker.
Training costs – We used the AWS Pricing API to fetch SageMaker on-demand prices to calculate it on the fly. According to our experiment, training cost approximately $1.58 on p3.2xlarge, and about four times less on g4dn.xlarge ($0.37). Distributed training on two p3.16xlarge instances using 16 GPUs cost $9.68.
To summarize, although the g4dn.xlarge was the least expensive machine, it also took about three times longer to train than the most powerful instance type we experimented with (two p3.16xlarge). Depending on your project priorities, you could choose from a wide variety of SageMaker training instance types.
Conclusion
In this post, we explored fine tuning pre-trained transformer-based language models for a question answering task for a mid-resource language (in this case, Turkish). You can apply this approach to over 100 other languages using a single model. As of writing, scaling up a model to cover all of the world’s 7,000 languages is still prohibitive, but the field of NLP provides an opportunity to widen our horizons.
Language is the principal method of human communication, and is a means of communicating values and sharing the beauty of a cultural heritage. The linguistic diversity strengthens intercultural dialogue and builds inclusive societies.
ML is a highly iterative process; over the course of a single project, data scientists train hundreds of different models, datasets, and parameters in search of maximum accuracy. SageMaker offers the most complete set of tools to harness the power of ML and deep learning. It lets you organize, track, compare, and evaluate ML experiments at scale.
Hugging Face is integrated with SageMaker to help data scientists develop, train, and tune state-of-the-art NLP models more quickly and easily. We demonstrated several benefits of using Hugging Face transformers on Amazon SageMaker, such as training and experimentation at scale, and increased productivity and cost-efficiency.
You can experiment with NLP tasks on your preferred language in SageMaker in all AWS Regions where SageMaker is available. The example notebook code is available in GitHub.
To learn how Amazon SageMaker Training Compiler can accelerate the training of deep learning models by up to 50%, see New – Introducing SageMaker Training Compiler.
The authors would like to express their deepest appreciation to Mariano Kamp and Emily Webber for reviewing drafts and providing advice.
References
J. Devlin et al., “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding”, (2018).
A. Vaswani et al., “Attention Is All You Need”, (2017).
J. Howard and S. Ruder, “Universal Language Model Fine-Tuning for Text Classification”, (2018).
T. Pires et al., “How multilingual is Multilingual BERT?”, (2019).
Y. Liu et al., “RoBERTa: A Robustly Optimized BERT Pretraining Approach”, (2019).
G. Lample, and A. Conneau, “Cross-Lingual Language Model Pretraining”, (2019).
A. Conneau et al., “Unsupervised Cross-Lingual Representation Learning at Scale”, (2019).
Stefan Schweter. BERTurk – BERT models for Turkish (2020).
Multilingual Wiki Statistics https://en.wikipedia.org/wiki/Wikipedia:Multilingual_statistics
About the Authors
Arnav Khare is a Principal Solutions Architect for Global Financial Services at AWS. His primary focus is helping Financial Services Institutions build and design Analytics and Machine Learning applications in the cloud. Arnav holds an MSc in Artificial Intelligence from Edinburgh University and has 18 years of industry experience ranging from small startups he founded to large enterprises like Nokia, and Bank of America. Outside of work, Arnav loves spending time with his two daughters, finding new independent coffee shops, reading and traveling. You can find me on LinkedIn and in Surrey, UK in real life.
{kind=link}
Hasan-Basri AKIRMAK (BSc and MSc in Computer Engineering and Executive MBA in Graduate School of Business) is a Senior Solutions Architect at Amazon Web Services. He is a business technologist advising enterprise segment clients. His area of specialty is designing architectures and business cases on large scale data processing systems and Machine Learning solutions. Hasan has delivered Business development, Systems Integration, Program Management for clients in Europe, Middle East and Africa. Since 2016 he mentored hundreds of entrepreneurs at startup incubation programs pro-bono.
{kind=link}
Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning and leads the Natural Language Processing (NLP) community within AWS. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers being successful in their AI/ML journey on AWS and has worked with organizations in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. In his spare time Heiko travels as much as possible.
{kind=link}
Read MoreAWS Machine Learning Blog