

{kind=link}
Amazon Timestream is a serverless time series database that customers across a broad range of industry verticals have adopted to derive real-time insights, monitor critical business applications, and analyze millions of real-time events across websites and applications. By analyzing these diverse workloads, in conjunction with the query access patterns and query concurrency requirements, we made several optimizations to Timestream that resulted in improvements in query latency up to three times faster across different workloads.
In November 2020, we demonstrated the performance and scale characteristics of Timestream. As part of that post, we also open sourced a data and query workload generator used in the experiments, which modeled an example DevOps application derived from conversations with hundreds of customers with many different types of use cases. In this post, we use the same workload setup and data scales to highlight the query latency improvements, Timestream’s interactive query latency even at the scale of terabytes of data, and its effective scaling from bytes to petabytes without any need to rearchitect your applications. The serverless nature of Timestream means you automatically get these scaling and latency improvements without any effort on your part.
Timestream’s value proposition
You want the ability to derive insights or drive actions within seconds of when the data is generated to gain an advantage in today’s competitive market or to delight your own users through these proactive and real-time actions. You can track events and measures over time to derive insights in a variety of use cases in application monitoring, logistics, supply chain optimization, fleet management, manufacturing, personalization, 360-degree customer behavior modeling, fraud detection, finance, and many more. This has fueled the growth of scenarios in real-time analytics, observability, monitoring, and IoT. Time series data and the ability to derive analytics in real time over large volumes of time series data underpins many of these use cases. To better satisfy these use cases, Timestream was designed from the ground up as a scalable, highly available, serverless time series database.
Since Timestream’s general availability, a variety of customer workloads have moved into production with Timestream. These workloads span tens of industry verticals, such as media and entertainment, consumer electronics, energy, oil and gas, healthcare, and more, and brought with them the diversity in data models, ingestion volume, data distributions, numbers of time series, query patterns, concurrency and burstiness requirements, and so on. With Timestream, you get the benefits of a serverless offering that works out of the box at both small and large scale with a minimal set of knobs to configure. You create a database and a table, configure retention periods, set access policies, and voila—you can start ingesting data in a streaming fashion and query the recently ingested or historical data using the power and flexibility of SQL queries. No resources to manage or scale, partitions to tune, or indexes to build. You can focus on solving your business problems, and Timestream automatically partitions, indexes, adapts, and scales based on the workload and data distributions.
Continuous improvements to Timestream
This ease of use has attracted many customers to the service. Our quest is to continuously enhance, adapt, and tune the service to cater to this broad class of customers while improving performance and making it cost-effective. Some of our customers monitor and track metrics of streaming video sessions over hundreds of millions of subscribers, resulting in billions of time series metrics. Other workloads benefit from the serverless scaling and low costs when tracking metrics for devices with sporadic activity. Operating a service with this diversity provides us the opportunity to analyze the ingestion, data distributions, and query patterns for thousands of workloads over time, which in turn provided us the insights to optimize the system to improve performance.
Timestream automatically partitions and indexes the data depending on the ingestion volume, data sizes, and distribution characteristics such as number of time series or number of data points per time series. A time series in Timestream is a unique combination of dimension names, values, and measure names. We host many applications with billions of time series, for instance, hundreds of millions of streaming users. Other use cases have fewer time series with many data points per time series, for example, a DevOps monitoring use case storing frequently emitted metrics.
By analyzing these diverse workloads, in conjunction with the query access patterns and query concurrency requirements, we improved our adaptive auto scaling, partitioning, indexing, and resource allocation algorithms. These optimizations resulted in up to three times faster query response times across a variety of workloads. The best part is that because Timestream is a serverless offering, all these improvements were automatically and seamlessly rolled out to our customers without any effort on their part!
Overview of the workload
The application being monitored is modeled as a highly scaled-out service that is deployed in several Regions across the globe. The application emits a variety of metrics (such as cpu_user and memory_free) and events (such as task_completed and gc_reclaimed). Each metric or event is associated with eight dimensions (such as region or cell) that uniquely identify the server emitting it. In this post, we provide only a brief summary of the workload. Additional details are available in our previous post and the open-sourced data generator.
Ingestion workload
The following table summarizes the data ingestion characteristics and corresponding data storage volumes. Depending on the number of hosts and metric interval, the application ingests between 156 million–3.1 billion data points per hour, resulting in approximately 1.1–21.7 TB per day. These data volumes translate to approximately 0.37–7.7 PB of data ingested over a year. We consider three different scale factors—small, medium, and large—representing different data volumes and time series cardinality.
Data Scale
Data Interval (seconds)
Number of Hosts Monitored (million)
Number of Time Series (million)
Average Data Points/Second
Average Data Points/Hour (million)
Average Ingestion Volume (MB/s)
Data Size/Hour (GB)
Data Size/Day (TB)
Data Size/Year (PB)
Small
60
0.1
2.6
43,333
156
13
45
1
0.37
Medium
300
2
52
173,333
624
51
181
4.3
1.5
Large
120
4
104
866,667
3,120
257
904
21.7
7.7
Query workload
The query workload is modeled around observability use cases we see across customers. The queries correspond to three broad classes:
Alerting – Querying the most recent data to detect and alert on anomalous behavior
Populating dashboards – Fleet-wide aggregates to identify trends and patterns over the past few hours
Analysis and reporting – Analyzes large volumes of data for fleet-wide insights over longer periods of time
Each class has two distinct queries: Q1 and Q2 are alerting, Q3 and Q4 are dashboarding, and Q5 and Q6 are analysis.
Performance improvements
We use the same setup as the experiments reported in the our previous post: namely, run 100 concurrent sessions where each session randomly picks one of the six queries to run with a pre-specified probability (Q1 and Q2 run with 95% probability, Q3 and Q4 run with 4.9% probability, and Q5 and Q6 run with 0.1% probability) and uses a randomly picked think time in the range of 5–300 seconds between query runs. For these performance runs, we configured a database for each workload size and one table per database. Each table is configured with 2 hours of memory store retention and 1 year of magnetic store retention. We ran continuous data ingest for several months while also running concurrent queries.
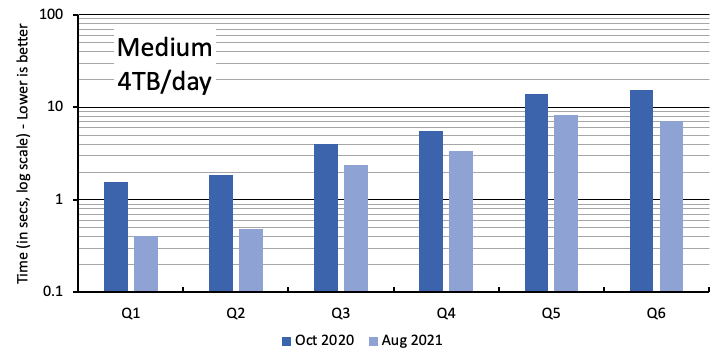
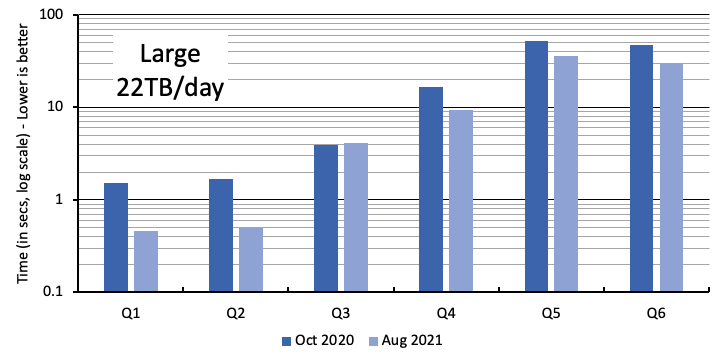
The following figures report the query latency for each query type, Q1–Q6, comparing the latency observed in October 2020 (reported in our previous post) with the latency observed in August 2021 after our optimizations and improvements have been deployed. The primary y-axis is the end-to-end query runtime in seconds (plotted in log scale), as observed by the client, from the time the query was issued to the last row of the query result was read. The client is an Amazon Elastic Compute Cloud (Amazon EC2) instance running the queries in the same Region where the Timestream database is hosted. Each session reports the geometric mean of query latency for each query type. The plot reports the latency averaged across the hundred sessions (the average of the geometric mean across the sessions). The different graphs correspond to the three different scale factors: small, medium, and large, as summarized in the preceding table.
{kind=link}
{kind=link}
{kind=link}
To make it easier to understand the scaling characteristics of Timestream, the next figure shows the numbers from Aug 2021 for all the queries and the three different scale factors. Timestream continues to provide interactive latency (less than 500 milliseconds) for Q1 and Q2 even as data scale grew to 22 terabytes per day. As the data size grew by twenty-two times from small to large scale factors, query latency for Q1 and Q2 only increased by two times. The latency for the analytical queries processing terabytes of data increased by about six times even though the data volume increased twenty-two times.
{kind=link}
The key takeaways from the query performance results are:
Timestream continues to effectively scale to petabytes of data. The decoupled ingestion, storage, and query scaling allows the system to scale to time series data of any scale, while seamlessly serving hundreds of concurrent queries at large scale in parallel to high throughput ingestion.
The three scale factors show that as applications grow in data volumes and query complexity, Timestream scales resources depending on query complexity and amount of data accessed, resulting in sub-linear latency increase with data scale. So as your application grows, Timestream continues to scale, from bytes to petabytes, without any need to rearchitect your application.
The cheapest queries, Q1 and Q2, became two to three times faster. This means your time to react to any anomalies went down significantly, either with automated alerts or dashboards that load faster.
Even the expensive analytical queries saw 50–100% latency reduction. For instance, if we consider Q5 and Q6 in the large scale, their latency came down from about 50 seconds to about 30 seconds—a 60% relative latency reduction. These queries analyzing terabytes of time series data now complete up to 20 seconds faster, allowing you to obtain faster real-time and historical insights.
Conclusion
In this post, we presented the query latency improvements resulting from the several optimizations we made to Timestream over the past year, analyzing and learning from the diverse set of workloads our customers run on Timestream. We improved our adaptive auto scaling, partitioning, indexing, and resource allocation algorithms, which resulted in up to three times faster query latency across different workloads. These improvements were seamlessly rolled out to our customers over the past year with no effort on their end. You continue to get the same serverless scaling to derive real-time insights—the queries run up to three times faster at the same cost to you.
To facilitate reproducing these performance numbers, we use the same open-sourced data and workload generator as our previous post. The workload is configurable to adapt to your own scale requirements to your use case. Follow these best practices guide to get started with optimizing the scale and performance of your workload.
About the Authors
Sudipto Das is a Principal Engineer in AWS working on Amazon Timestream. He is an engineering and research leader known for his work on scalable database management systems for cloud platforms. https://sudiptodas.github.io/
{kind=link}
Christian Damianidis is a Software Engineer at Amazon Timestream. He has 10 years of experience building database storage engines and cloud database services.
{kind=link}
Read MoreAWS Database Blog