

{kind=link}
Critical workloads with a global footprint have strict availability requirements and may need to tolerate a Region-wide outage. Traditionally, this required a difficult trade-off between performance, availability, cost, and data integrity, and sometimes required a considerable re-engineering effort. Due to the high implementation and infrastructure costs that are involved, some businesses are compelled to tier their applications, so that only the most critical ones are well protected.
When developing a cross-Region disaster recovery (DR) strategy, whether to use multiple accounts is a key consideration. There are many benefits to using more than one AWS account, including resource and operational isolation, security boundaries, and cost tracking. Having a multi-account strategy is critical to maintaining business continuity and achieving regulatory compliance.
In this post, we talk about the benefits of using multiple accounts, and how Amazon Aurora Global Database can be a part of your disaster recovery solution. We show you two ways to achieve cross-account, cross-Region disaster recovery using Global Database.
Use cases
Many organizations, for security or compliance reasons, require complete separation of duties and access from their primary Region and secondary Region. This helps mitigate the insider threat or piece of software that has gained access in your primary account. Having your backups or primary database routinely copied to the secondary account provides an isolated account that can take over primary duties. With Aurora Global Database, you get the advantage of fast replication to a secondary database cluster in a different Region in the same account with lower Recovery Time Objective (RTO) and Recovery Point Objective (RPO). When you isolate the failover to a different account by following the options we describe in this post, you continue to maintain lower RTO and RPO depending on the level of automation and frequency you configure for restoring the database in a separate DR account.
Many organizations want to share data throughout their organization or even with third parties. Sharing this data from a secondary account limits the number of users on your primary account, and allows users to run queries without impacting the production database. Secondly, only sanitized copies of the data can be moved into the secondary account to ensure that sensitive data isn’t inadvertently exposed. The biggest benefit here is the level of control you have on the data that you want to expose to the users with varying needs from your organization and outside your organization.
You can use multiple AWS accounts to isolate workloads or applications that have specific security requirements, or need to meet strict guidelines for compliance such as HIPAA. With HIPAA, you as a customer are responsible for encrypting the PHI data at rest and in motion, and AWS offers a comprehensive set of features and services to make key management and encryption of PHI easy to manage and simple to audit. HIPAA also has a requirement to maintain a contingency plan to protect data in case of emergency, so in the rare occasion that your primary AWS account is compromised, you can continue to meet the requirement of data durability through the secondary account. You can refer to AWS recommended best practices for multi-account strategies for architecting your workload in AWS. This approach also helps with effective cost management across accounts.
You may also have requirements for fast cross-Region disaster recovery and low-latency local reads, and running analytics for users in different Regions. In this scenario, a version of the application stack is set up in another Region to provide disaster recovery and serve fast local reads. The benefit here is that you can provide faster access to your application without redirecting the request from a different Region in an isolated account in case of emergency or disaster.
Enterprise applications are tiered by their business priorities, for example platinum, gold, and silver. These platinum and gold applications mostly have very stringent business SLAs for RTO and RPO. AWS’s recommended well-architected multi-Region and multi-account strategy for DR provides a strong isolation boundary and helps avoid correlated failures across Regions. With this approach, you get greater control over recovery time in the event of a hard dependency failure on accounts that span across Regions.
This approach has the following benefits:
Greater control over data
Complete isolation of workloads to meet compliance requirements
Minimizing risk while sharing data within the organization and with third parties
However, it has the following drawbacks:
Additional effort to automate the multi-account strategy, and creating, maintaining, and restoring from a snapshot or database cloning
Additional cost of resources in a separate account depending on the DR strategy—pilot light, warm standby, or active-active
In the following sections, we discuss two different options that we can use to share data using Aurora Global Database across Regions within multiple accounts.
Option 1: Create and share a snapshot to another account from a global database
This walkthrough assumes you already have an existing Aurora global database up and running with at least one secondary cluster. For instructions, see Creating an Amazon Aurora global database.
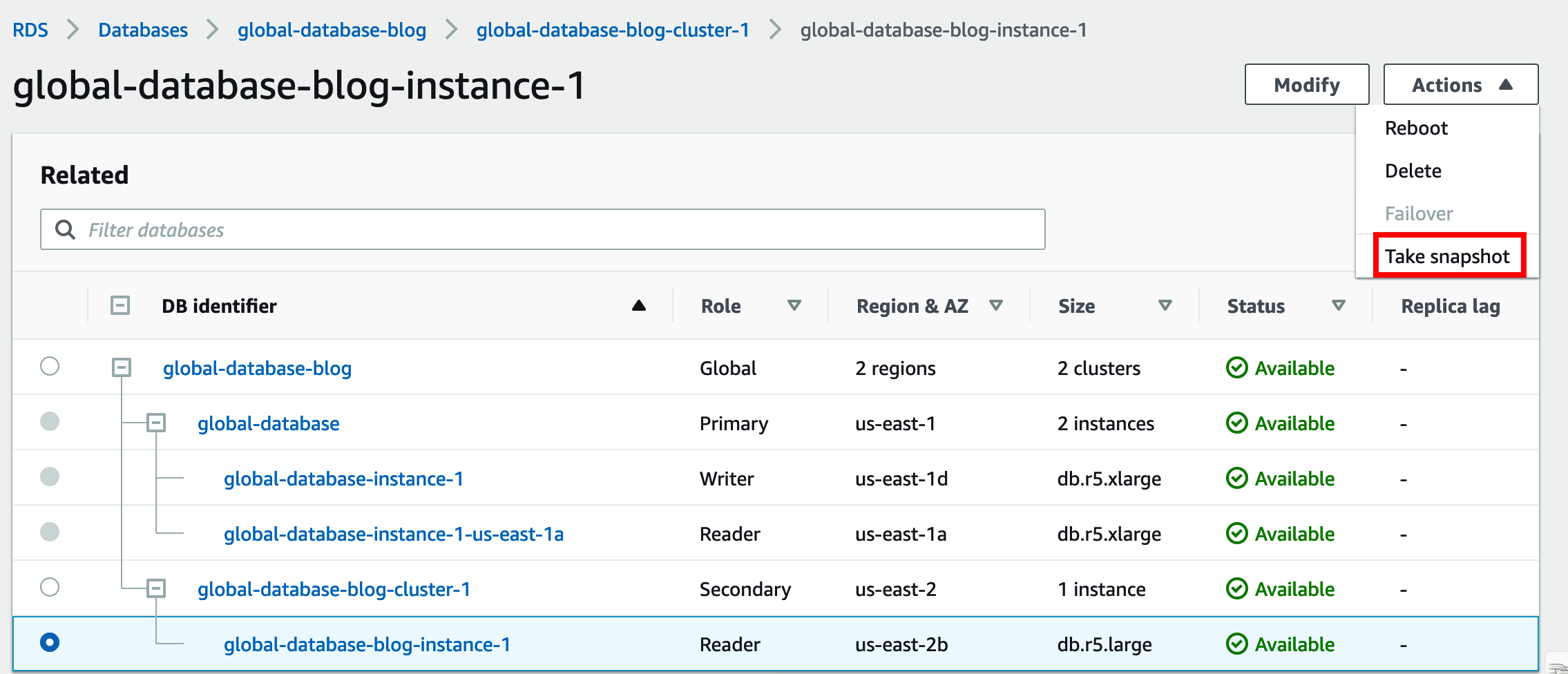
In the secondary Region, select the reader instance in the secondary cluster.
On the Actions menu, choose Take snapshot.
For Snapshot name, enter a name.
Choose Take snapshot.
{kind=link}
{kind=link}
{kind=link}
The snapshot status changes to Creating.
{kind=link}
Finally, the snapshot becomes available.
{kind=link}
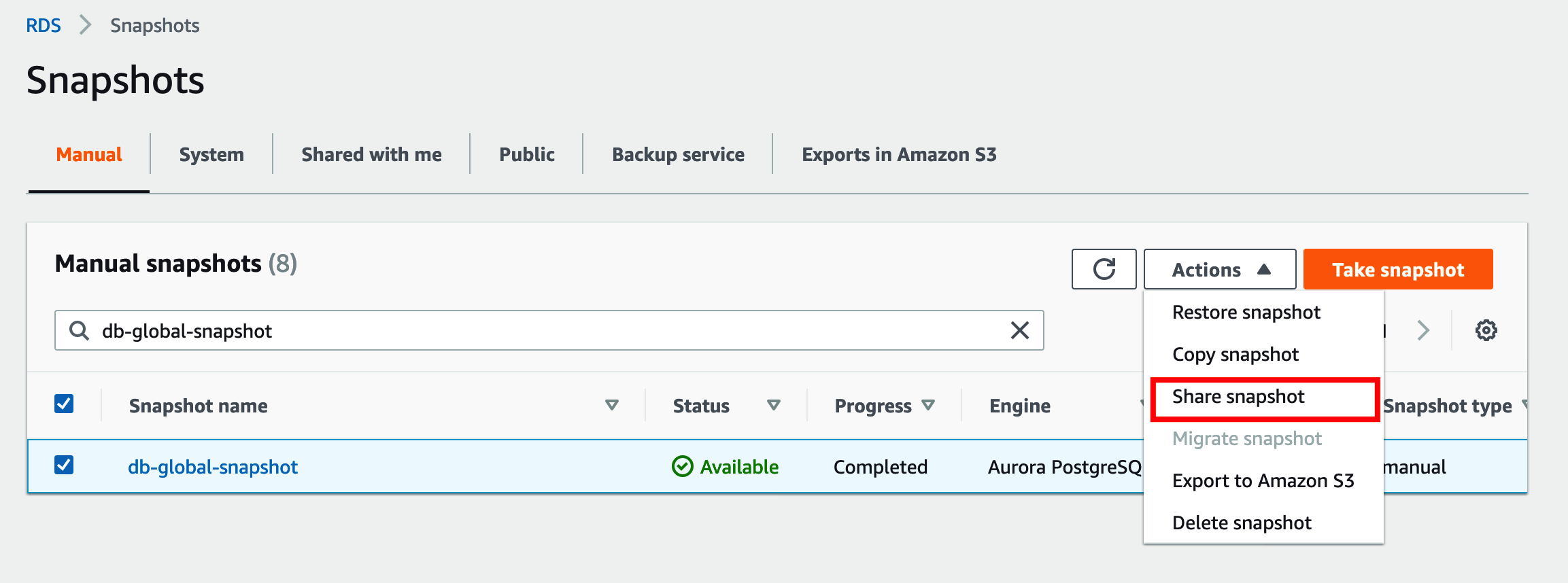
You can now share the snapshot with a different (disaster recovery) account.
Select your snapshot and on the Actions menu, choose Share snapshot.
For DB snapshot visibility, select Private.
For AWS account ID, enter your account ID.
Choose Save.
{kind=link}
{kind=link}
You can verify the snapshot is available in the DR account on the Shared with me tab.
{kind=link}
Allow access to the target account on the CMK of the source account
For an encrypted snapshot, you need to ensure that the target account also has access to the AWS Key Management Service (AWS KMS) customer master key (CMK) of the source account. For more information, see Allowing users in other accounts to use a CMK.
Log in to the source account, then open the AWS KMS console in the same Region as the DB snapshot.
Choose Customer managed keys in the navigation pane.
Choose the name of your customer managed key, or choose Create key, if you don’t yet have one.
For more information about creating a key, see Creating keys.
In the Key administrators section, add the AWS Identity and Access Management (IAM) users and roles who can administer the KMS key.
In the Key users section, add the IAM users and roles who can use the CMK to encrypt and decrypt data.
In the Other AWS accounts section, choose Add another AWS account.
Enter the AWS account number of the target account.
Restore the snapshot
You can now restore the snapshot in the DR account in case of a disaster. For un-encrypted clusters such as the ones for non-sensitive workload or clusters in lower environments, you don’t need to perform the CMK step. Also, you can’t share snapshots encrypted with the default KMS key, therefore you should use a custom KMS key to share the snapshot with another account.
You can delete the old snapshots after the latest snapshot is created and shared as per your retention policy and RPO.
Option 2: Use a cross-account clone from a secondary cluster of Aurora Global Database
Another method of performing cross-Region, cross-account disaster recovery is to create a cross-account clone from the secondary cluster of Aurora Global Database.
First, you need to grant the DR account permission to clone the secondary cluster. We use AWS Resource Access Manager (AWS RAM) to securely share your resources across AWS accounts, within your organization or organizational units (OUs) in AWS Organizations, and with IAM roles and IAM users for supported resource types.
Complete the following steps to perform cross-account cloning:
Share the secondary Aurora cluster in the production account with the DR account using the AWS Command Line Interface (AWS CLI) and the following syntax:
For example, see the following code:
In the DR account, you should see the AWS RAM resource sharing invitation:
Accept the invitation in the DR account:
Next, you should see a shared cluster in the DR account in the secondary Region for creating a clone.
{kind=link}
Choose the resource to see the Aurora cluster.
{kind=link}
The following screenshot shows the details for the secondary Aurora cluster.
{kind=link}
On the Actions menu, choose Create clone.
On the Create clone page, enter the appropriate instance specifications.
Enter the instance class, VPC, and other required details to create the cloned cluster.
{kind=link}
{kind=link}
You could also use the AWS CLI to create a clone instead of the console. First, you create the clone:
Then you add an instance:
Comparison
Now let’s compare these two methods for cross-account, cross-Region DR in Aurora.
When we use the snapshot from the secondary cluster in the same account but in the DR Region and then share the snapshot with the DR account (option 1), we reduce the need to copy the snapshot data across Regions. It uses the purpose-built, high-performance, dedicated replication technology of Aurora Global Database. However, you need to have the instance running in the secondary cluster to take a snapshot, which can contribute to additional cost. You can make that part of the snapshot creation and sharing workflow to create an instance, take a snapshot, and then delete the instance.
You can also create an Aurora snapshot in the production Region, share it with the DR account, and copy the snapshot with the DR Region. One advantage is that you don’t need to keep the instances running, so this method is simple and cost-efficient. However, during a disaster, you need to create new cluster by restoring the snapshot, thereby increasing the RTO. Also, there is a limited number of snapshots that can be copied concurrently.
In both cases, the RPO depends on the snapshot frequency.
With our second option, creating a cross-account clone in the DR account from the secondary cluster in the production account is very quick. Therefore, it can be a highly suitable solution for systems with an aggressive RTO requirement. However, this method also needs instances to be running in the secondary cluster, and has additional cost due to instances running. With this option, you can also make that part of the cross-account clone creation workflow to create an instance in the secondary cluster in the production account, create a cross-account clone in the DR account, and finally delete the instance in the production account’s DR Region.
Monitor an Aurora database in the DR account
As part of a well-architected framework, AWS recommends using a monitoring and observability service to record performance-related metrics, and monitor and alarm proactively. Disaster recovery is no different. Amazon RDS Performance Insights is a database performance tuning and monitoring feature that helps you quickly assess the load on your database, and determine when and where to take action.
You can use Performance Insights to monitor your Aurora global database. The Performance Insights API provides visibility into your instance performance. You can use this API to automate, retrieve DB metrics such as Aurora metrics, and add the Performance Insights data in your monitoring dashboard such as an Amazon CloudWatch dashboard. If you have this automation in place for your primary account, you can reuse the scripts, and configure AWS Lambda in your DR account after your failover. For more information, see Retrieving metrics with Performance Insights API and Analyzing metrics with the Performance Insights dashboard.
Database authentication with Aurora
Aurora supports the following ways to authenticate database users:
Password authentication
IAM database authentication
Kerberos authentication
When you configure your Aurora global database, you can take advantage of AWS Managed Microsoft AD cross-Region support—you only need one distinct AWS Managed Microsoft AD that spans multiple AWS Regions. Aurora support for Kerberos and Active Directory provides the benefits of single sign-on and centralized authentication of database users. AWS Managed Microsoft AD integrates tightly with Organizations to allow seamless directory sharing across multiple AWS accounts. So, after configuring your application to use your Aurora global database in a different Region and in a different account, you can authenticate your users with this directory sharing configuration.
Best practices
Improperly setting parameters in a parameter group can have unintended adverse effects, including degraded performance and system instability. Always exercise caution when modifying database parameters and back up your data before modifying a parameter group. For an Aurora global database, you can specify different configuration settings for the individual Aurora clusters. Make sure that the settings are similar enough to produce consistent behavior if you promote a secondary cluster to be the primary cluster. For example, use the same settings for time zones and character sets across all the clusters of an Aurora global database.
With Aurora Global Database, you can either share snapshots or you can clone a database for another account (which is your DR account). Regardless of the approach you take, for security reasons, consider encryption of data at rest and in transit.
Conclusion
Aurora Global Database allows you to create disaster recovery capabilities and resources that are completely isolated and secured with an AWS well-architected multi-account strategy. You can use either the cloning feature with your Aurora global database or the database snapshot option from a secondary cluster to synchronize the data in a different Region anywhere in the world and in a different DR account to comply with your business needs.
In this post, we explained two methods to perform cross-account, cross-Region disaster recovery for Aurora clusters and their pros and cons. Using a cross-account clone or sharing a snapshot from a secondary cluster both have additional costs than running just a secondary cluster. The cost implication of both solutions depends on various components like cluster size, instance class, frequency of snapshots, as well as the rate of data changes. Depending on your use case, RPO, RTO, and cost implications, you can choose either of these methods to achieve cross-Region and cross-account disaster recovery in your Aurora environments.
About the Authors
Saikat Banerjee is a Database Specialist Solutions Architect with Amazon Web Services.
{kind=link}
Ryan Shevchik is a Data & Analytics Specialist Solutions Architect with Amazon Web Services.
{kind=link}
Sukhomoy Basak is a Solutions Architect with Amazon Web Services.
{kind=link}
Read MoreAWS Database Blog