

{kind=link}
Medical imaging techniques like computed tomography (CT), magnetic resonance imaging (MRI), medical x-ray imaging, ultrasound imaging, and others are commonly used by doctors for various reasons. Some examples include detecting changes in the appearance of organs, tissues, and vessels, and detecting abnormalities such as tumors and various other type of pathologies.
Before doctors can use the data from those techniques, the data needs to be transformed from its native raw form to a form that can be displayed as an image on a computer screen.
This process is known as image reconstruction, and it plays a crucial role in a medical imaging workflow—it’s the step that creates diagnostic images that can be then reviewed by doctors.
In this post, we discuss a use case of MRI reconstruction, but the architectural concepts can be applied to other types of image reconstruction.
Advances in the field of image reconstruction have led to the successful application of AI-based techniques within magnetic resonance (MR) imaging. These techniques are aimed at increasing the accuracy of the reconstruction and in the case of MR modality, and decreasing the time required for a full scan.
Within MR, applications using AI to work with under-sampled acquisitions have been successfully employed, achieving nearly ten times reduction in scan times.
Waiting times for tests like MRIs and CT scans have increased rapidly in the last couple of years, leading to wait times as long as 3 months. To ensure good patient care, the increasing need for quick availability of reconstructed images along with the need to reduce operational costs has driven the need of a solution capable of scaling according to storage and computational needs.
In addition to computational needs, data growth has seen a steady increase in the last few years. For example, looking at the datasets made available by the Medical Image Computing and Computer-Assisted Intervention (MICCAI), it’s possible to gather that the annual growth is 21% for MRI, 24% for CT, and 31% for functional MRI (fMRI). (For more information, refer to Dataset Growth in Medical Image Analysis Research.)
In this post, we show you a solution architecture that addresses these challenges. This solution can enable research centers, medial institutions, and modality vendors to have access to unlimited storage capabilities, scalable GPU power, fast data access for machine learning (ML) training and reconstruction tasks, simple and fast ML development environments, and the ability to have on-premises caching for fast and low-latency image data availability.
Solution overview
This solution uses an MRI reconstruction technique known as Robust Artificial-neural-networks for k-space Interpolation (RAKI). This approach is advantageous because it’s scan-specific and doesn’t require prior data to train the neural network. The drawback to this technique is that it requires a lot of computational power to be effective.
The AWS architecture outlined shows how a cloud-based reconstruction approach can effectively perform computational-heavy tasks like the one required by the RAKI neural network, scaling according to the load and accelerating the reconstruction process. This opens the door to techniques that can’t realistically be implemented on premises.
Data layer
The data layer has been architected around the following principles:
Seamless integration with modalities that store data generated into an attached storage drive via a network share on a NAS device
Limitless and secure data storage capabilities to scale to the continuous demand of storage space
Fast storage availability for ML workloads such as deep neural training and neural image reconstruction
The ability to archive historic data using a low-cost, scalable approach
Permit availability to the most frequently accessed reconstructed data while simultaneously keeping less frequently accessed data archived at a lower cost
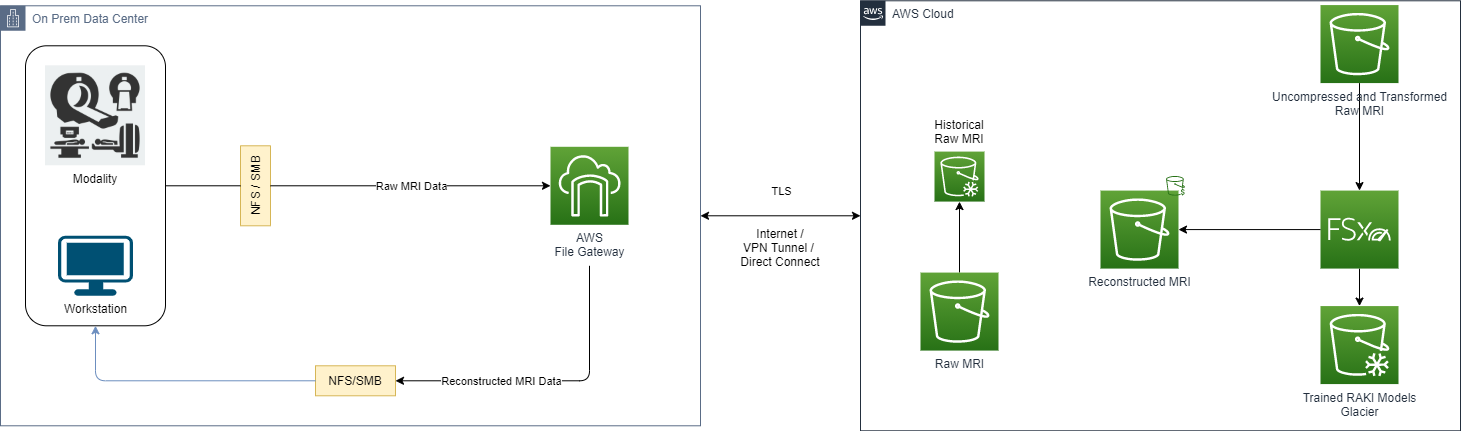
The following diagram illustrates this architecture.
{kind=link}
This approach uses the following services:
AWS Storage Gateway for a seamless integration with the on-premises modality that exchanges information via a file share system. This allows transparent access to the following AWS Cloud storage capabilities while maintaining how the modality exchanges data:
Fast cloud upload of the volumes generated by the MR modality.
Low-latency access to frequently used reconstructed MR studies via local caching offered by Storage Gateway.
Amazon SageMaker for unlimited and scalable cloud storage. Amazon S3 also provides low-cost, historical raw MRI data deep archiving with Amazon S3 Glacier, and an intelligent storage tier for the reconstructed MRI with Amazon S3 Intelligent-Tiering.
Amazon FSx for Lustre for fast and scalable intermediate storage used for ML training and reconstruction tasks.
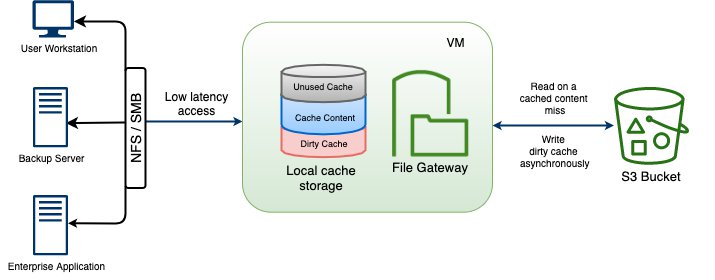
The following figure shows a concise architecture describing the data exchange between the cloud environments.
{kind=link}
Using Storage Gateway with the caching mechanism allows on-premises applications to quickly access data that’s available on the local cache. This occurs while simultaneously giving access to scalable storage space on the cloud.
With this approach, modalities can generate raw data from acquisition jobs, as well as write the raw data into a network share handled from Storage Gateway.
If the modality generates multiple files that belong to the same scan, it’s recommended to create a single archive (.tar for example), and perform a single transfer to the network share to accelerate the data transfer.
Data decompression and transformation layer
The data decompression layer receives the raw data, automatically performs decompression, and applies potential transformations to the raw data before submitting the preprocessed data to the reconstruction layer.
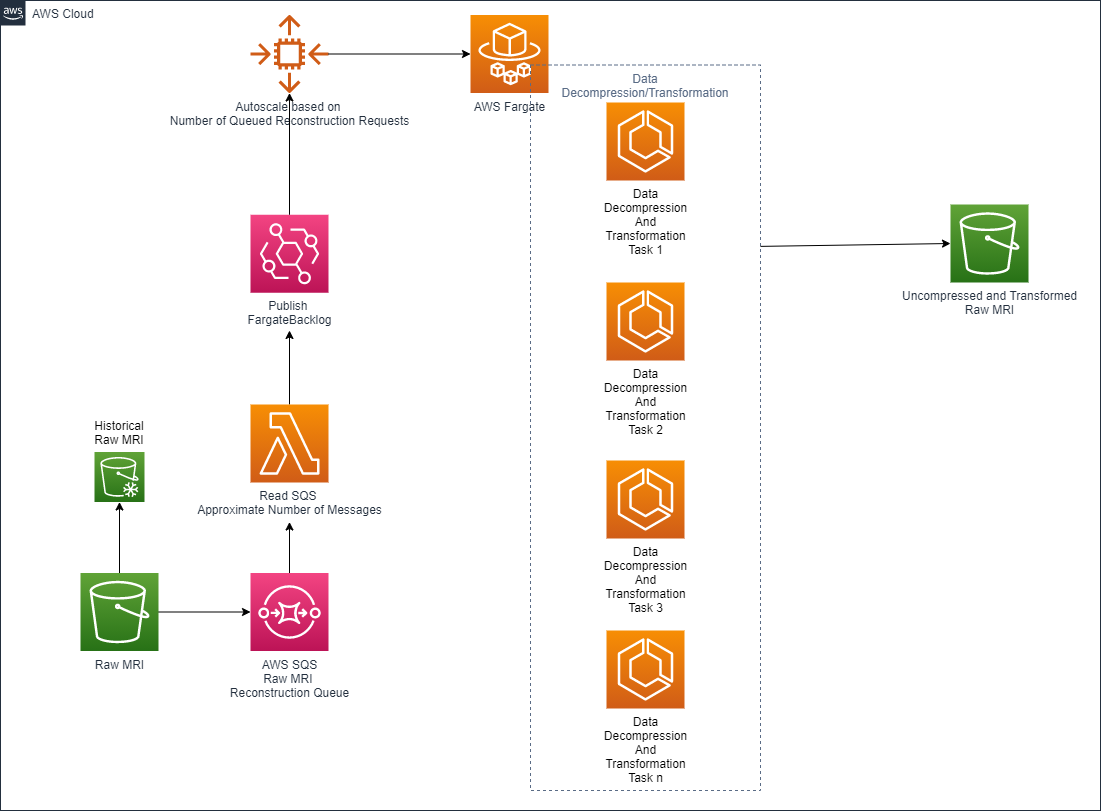
The adopted architecture is outlined in the following figure.
{kind=link}
In this architecture, raw MRI data lands in the raw MRI S3 bucket, thereby triggering a new entry in Amazon Simple Queue Service (Amazon SQS).
An AWS Lambda function retrieves the raw MRI Amazon SQS queue depth, which represents the amount of raw MRI acquisitions uploaded to the AWS Cloud. This is used with AWS Fargate to automatically modulate the size of an Amazon Elastic Container Service (Amazon ECS) cluster.
This architecture approach lets it automatically scale up and down accordingly to the number of raw scans landed into the raw input bucket.
After the raw MRI data is decompressed and preprocessed, it’s saved into another S3 bucket so that it can be reconstructed.
Neural model development layer
The neural model development layer consists of a RAKI implementation. This creates a neural network model to allow the fast image reconstruction of under-sampled magnetic resonance raw data.
The following figure shows the architecture that realizes the neural model development and container creation.
{kind=link}
In this architecture, Amazon SageMaker is used to develop the RAKI neural model, and simultaneously to create the container that is later used to perform the MRI reconstruction.
Then, the created container is included in the fully managed Amazon Elastic Container Registry (Amazon ECR) repository so that it can then spin off reconstruction tasks.
Fast data storage is guaranteed by the adoption of Amazon FSx for Lustre. It provides sub-millisecond latencies, up to hundreds of GBps of throughput, and up to millions of IOPS. This approach gives SageMaker access to a cost-effective, high-performance, and scalable storage solution.
MRI reconstruction layer
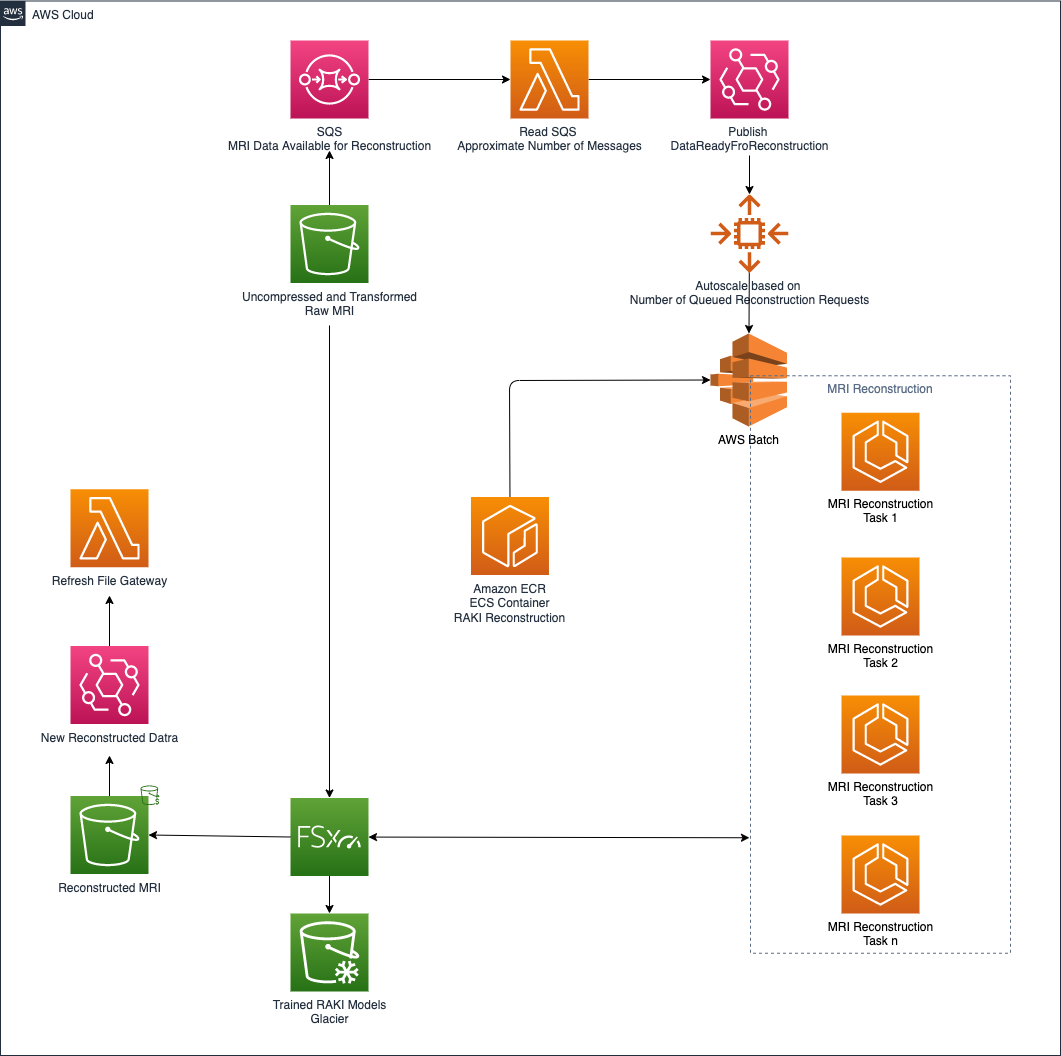
The MRI reconstruction based on the RAKI neural network is handled by the architecture shown in the following diagram.
{kind=link}
With the same architectural pattern adopted in the decompression and preprocessing layer, the reconstruction layer automatically scales up and down by analyzing the depth of the queue responsible for holding all the reconstruction requests. In this case, to enable GPU support, AWS Batch is used to run the MRI reconstruction jobs.
Amazon FSx for Lustre is used to exchange the large amount of data involved in MRI acquisition. Furthermore, when a reconstruction job is complete and the reconstructed MRI data is stored in the target S3 bucket, the architecture employed automatically requests a refresh of the storage gateway. This makes the reconstructed data available to the on-premises facility.
Overall architecture and results
The overall architecture is shown in the following figure.
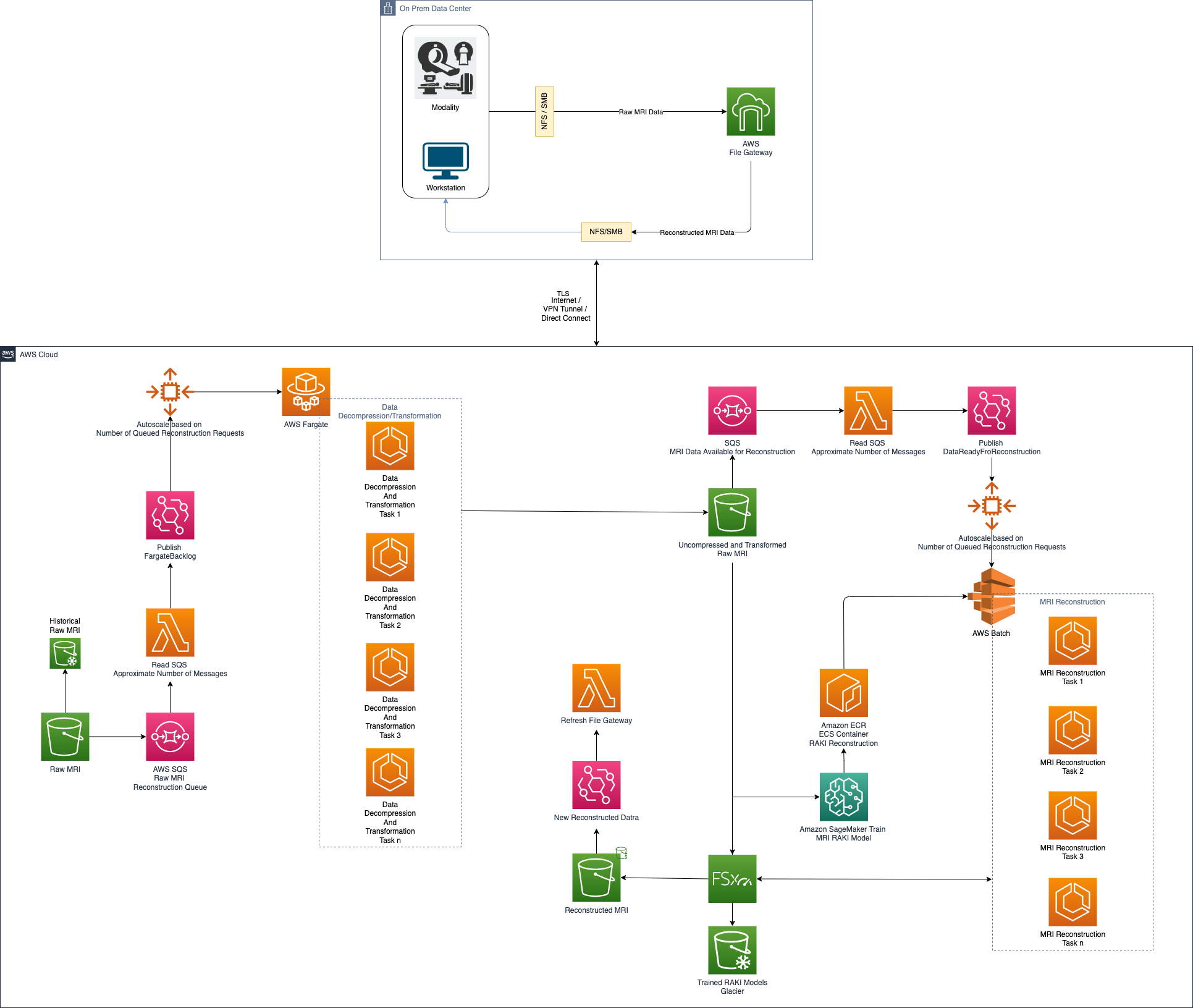{kind=link}
We applied the described architecture on MRI reconstruction tasks with datasets approximately 2.4 GB in size.
It took approximately 210 seconds to train 221 datasets, for a total of 514 GB of raw data on a single node equipped with a Nvidia Tesla V100-SXM2-16GB.
The reconstruction, after the RAKI network has been trained, took an average of 40 seconds on a single node equipped with a Nvidia Tesla V100-SXM2-16GB.
The application of the preceding architecture to a reconstruction job can yield the results in the following figure.
{kind=link}
The image shows that good results can be obtained via reconstruction techniques such as RAKI. Moreover, adopting cloud technology can make these computation-heavy approaches available without the limitations found in on-premises solutions where storage and computational resources are always limited.
Conclusions
With tools such as Amazon SageMaker, Amazon FSx for Lustre, AWS Batch, Fargate, and Lambda, we can create a managed environment that is scalable, secure, cost-effective, and capable of performing complex tasks such as image reconstruction at scale.
In this post, we explored a possible solution for image reconstruction from raw modality data using a computationally intensive technique known as RAKI: a database free deep learning technique for fast image reconstruction.
To learn more about how AWS is accelerating innovation in healthcare, visit AWS for Health.
References
Scan-specific Robust Artificial-neural-networks for k-space Interpolation (RAKI): Database free Deep Learning Reconstruction for Fast Imaging
MRI datasets used in this post
About the author
Benedetto Carollo is the Senior Solution Architect for medical imaging and healthcare at Amazon Web Services in Europe, Middle East, and Africa. His work focuses on helping medical imaging and healthcare customers solve business problems by leveraging technology. Benedetto has over 15 years of experience of technology and medical imaging and has worked for companies like Canon Medical Research and Vital Images. Benedetto received his summa cum laude MSc in Software Engineering from the University of Palermo – Italy.
{kind=link}
Read MoreAWS Machine Learning Blog