

{kind=link}
The business problem of real-time data aggregation is faced by customers in various industries like manufacturing, retail, gaming, utilities, and financial services. In a previous post, we discussed an example from the banking industry: real-time trade risk aggregation. Typically, financial institutions associate every trade that is performed on the trading floor with a risk value and the risk management division of the bank needs a consistent view on the total risk values, aggregated over all trades. We outlined an architecture solving this problem using Amazon Kinesis, AWS Lambda, and Amazon DynamoDB that can horizontally scale to handle up to 50,000 messages per second. In that example, all risk messages represented risks for new trades, which we aggregated using summation. However, in the reality of a trading floor, the risk value of a trade sometimes needs to be modified at a later stage.
Therefore, in this post, we show you how to enhance that architecture to be able to adjust the risk value of a trade as new messages come in, while providing exactly-once processing semantics. To achieve this, we add two additional components to the pipeline: A Lambda function that picks up the messages from the incoming data stream and adds or updates the risk value of every trade in a DynamoDB table.
Furthermore, we introduce a new Version attribute that we use to detect messages that arrive out of order. We add this Version attribute to our risk message schema (see example below), so if Version : 2 of a trade is picked up by the pipeline, but Version : 3 was already processed, we can simply disregard the message. The initial Version value for each trade is zero, and the Version is incremented for each subsequent modification of that trade.
Architecture overview: Stateful, exactly-once, aggregation pipeline
The following diagram shows the architecture of our stateful, exactly-once aggregation pipeline. It uses a map-and-reduce approach in which multiple concurrent map Lambda functions pre-aggregate data and reduce it to a manageable volume, allowing the data to be aggregated by a single reduce Lambda function in a consistent manner. Overall, the data travels from the upstream data source, passes through the pipeline, lands in the DynamoDB aggregate table, and is read by a front end.
{kind=link}
The newly added components to the map-and-reduce schema are enclosed by the dashed line. In this architecture, the Kinesis data stream triggers a fleet of the state Lambda functions. These functions write all attributes of incoming risk messages to the DynamoDB state table. The TradeID attribute of a risk message is used as the partition key of the DynamoDB table.
Each instance of the state Lambda function is invoked by a batch of up to 100 risk messages from the data stream. For each message in the batch, if the TradeID doesn’t exist in the table yet, the state function writes a new row into the DynamoDB state table. In case that a previous version of that TradeID was already recorded in the table, it updates the existing row with the new version of the risk record.
As we will explain below, this combination of the state Lambda function and the DynamoDB state table prevents processing any message more than once, and keeps track of the current state of individual risk messages (as identified by their TradeID), which allows us to compute the change in value when a new version of a risk arrives.
Subsequently, the DynamoDB stream of the state table invokes the second part of the pipeline, with a map-and-reduce schema that is similar to the architecture that we introduced in a related blog post.
Based on our implementation of this architecture, we can make sure that every message ingested into Kinesis is processed and added to the aggregates exactly once. This is based on two pillars.
First, the AWS services that we use are designed for at-least-once delivery and processing: The producer – a sample risk record generator, hosted in the AWS Cloud – generates and sends risk record messages into the data stream. In case of a failure, the submission of a request is retried, until the producer receives a successful confirmation of the delivery of the messages (see documentation for more details). Kinesis Data Streams natively provides at-least-once delivery semantics. This means, that Kinesis is designed to ensure that every message that’s successfully ingested into the data stream will be delivered to the destination.
This is an event-driven architecture: The arrival of risk messages in the data stream triggers the state Lambda function. By default, Lambda functions that are invoked by a stream (Kinesis data streams as well as DynamoDB streams) are retried with the same batch of messages until the batch is successfully processed. The same applies to the map and reduce Lambda functions (invoked by corresponding DynamoDB streams), therefore we can make sure that the pipeline processes every message at least once from end-to-end (as long as automatic retries are enabled).
Second, the write operations to the three DynamoDB tables are idempotent, which means any operation can be repeated for an arbitrary number of times, without influencing the result. Based on the requirements specific to this pipeline, we use three different techniques to ensure idempotency in each of the three Lambda functions of the pipeline.
Let’s look closer at how the different parts of the pipeline are implemented in order to ensure fault tolerance and exactly-once processing of every message.
State Lambda function
The state Lambda function attempts to write the new state of each received risk message to the DynamoDB state table. As we outlined earlier, we use the unique TradeID as the partition key of the state table, therefore we can use the update_item API call in the following way:
The conditional update solves two potential issues: duplicates and out-of-order messages. A message with a specific TradeID and Version is written to DynamoDB, only if either no item with the same TradeID exists in the table, or if an item with the same TradeID exists, but the version number of the existing item is smaller than that of the currently processed message.
Map Lambda function
The map Lambda function is invoked by a batch of add or update operations to the state table. With the default retry schema of functions invoked by a data stream, the exact same batch of messages is retried in case of failure. Therefore, to ensure idempotency, we calculate a SHA256 hash over the list of records in the Lambda event, and only write the aggregate to the reduce table, if this hash is not present in the table (see the following code):
Note, how we combine a unique identifier with a conditional put to achieve idempotent writes to DynamoDB.
Reduce Lambda function
Finally, the reduce Lambda function is invoked with a batch of items from the DynamoDB reduce table’s stream. This function updates the total aggregate values in the aggregate table. An aggregation is stored across multiple rows in the table, and each row represents a value of a specific category. We want to ensure that each update is performed atomically: either all items are updated, or none. We need to eliminate the possibility of inconsistent states, in which a function fails after a partial update. Therefore, we use a single DynamoDB transaction to increment the value of all items in a single, atomic operation:
DynamoDB transactions can include 25 unique items or up to 4 MB of data, including conditions. In our specific example, with a message size of less than 1 KB and fewer than 25 distinct aggregation categories, we aren’t affected by these constraints. Naturally, this may be different for other use cases. If your specific use case comprises more than 25 distinct aggregation categories or larger messages, we recommend controlling the maximum size of the output of the map Lambda function: if any pre-aggregate in the map function contains more than 25 distinct values or exceeds 4 MB, you can split it into multiple entries in the reduce table.
In addition to the atomicity, DynamoDB transactions provide idempotency via the ClientRequestToken supplied with the write or transaction request. ClientRequestToken makes sure that subsequent invocations of transactions with a token that was used in the last 10 minutes don’t result in updates to the DynamoDB table.
We compute the hash over all messages in the batch that the Lambda function is invoked with to use as the ClientRequestToken. Lambda ensures that the function is retried with the same batch of messages on failure. Therefore, by ensuring that all code paths in the Lambda function are deterministic, we can ensure idempotency of the transactions and achieve exactly-once processing at this last stage of the pipeline, provided that any retry happens within a 10-minute window after the first successful write (since a ClientRequestToken is valid for no more than 10 minutes, as outlined in the documentation).
Throughput and capacity requirements
The state function is designed to write one item at a time to DynamoDB (more details on this in the previous section), therefore the maximum throughput of a single instance is around 100 messages per second. To handle a rate of 50,000 messages per second, we need to instantiate around 500 concurrent instances of the state function. Furthermore, because every message is written to the state table, consuming 1 write capacity unit (WCU) per write, the total consumed WCUs of this table have the same magnitude as the pipeline throughput. The remaining parts of the pipeline have a significantly smaller resource footprint.
Evaluation
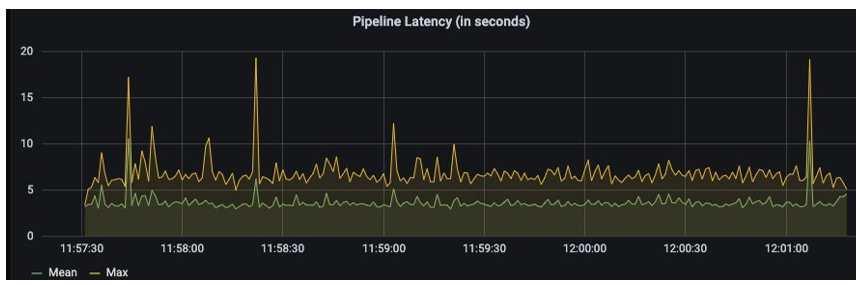
The following are measurements from ingesting 10 million messages at a fairly constant throughput of 50,000 messages per second into the pipeline (the total throughput is computed as a rolling mean over 20 seconds). The horizontal axis shows the time, and the vertical axis is specified on the top of each of the following graphs. We can observe a mean end-to-end latency of 3–4 seconds with a maximum at around 20 seconds.
{kind=link}
{kind=link}
Test resiliency
Considering the strict consistency requirements of the financial services industry, we took special care to make a solution that is fault tolerant by design, and we took extra steps to verify its resiliency by testing the consistency of the results under Lambda function failures and intentional message duplication by the data producer.
We added the following code snippet to all three Lambda functions:
This code can fail each Lambda function with a predefined probability, which allows us to test and verify operating behavior under failures. Moreover, a particularly unlucky message could be retried multiple times in each of the three Lambda functions. We selected the following failure probabilities for the three functions:
Finally, we modified the producer to introduce duplicate and out-of-order messages into the pipeline.
The following graphs show a test in which we consistently processed 10 million messages over 200 seconds, while achieving a throughput of 50,000 messages per second with the intentionally induced failures.
{kind=link}
{kind=link}
Due to the intentionally injected failures, we observe an increased variance in the pipeline’s latency. In extreme cases, end-to-end processing time for individual records exceeded 60 seconds. This is expected and explained by the fact that certain (“unlucky”) messages experienced failures at more than one stage of the pipeline. Such consecutive failures can lead to a significant increase in the end-to-end processing time.
However, despite the injected failures, the pipeline still achieved a throughput of 50,000 messages per second while maintaining mean end-to-end latency of 3–4 seconds, which demonstrates the resiliency and scalability of the described architecture. At the end of the experiment, we verified that no single message was duplicated or lost, confirming that the pipeline adheres to the exactly-once processing semantics.
Explore the pipeline in your AWS account
You can easily deploy the architecture described in this post in your own AWS account using the provided AWS CloudFormation template. The template deploys a pipeline that allows you to test and investigate serverless data aggregation. It comes with an AWS Cloud9 instance that can run the producer, as well as the front end.
Running the provided CloudFormation template in your own account may incur costs. Following the exact steps outlined in this post in any Region of your choice incurs charges of less than $1 USD, but be careful to clean up all of the resources after use.
To deploy the solution architecture, complete the following steps:
Download the following CloudFormation template.
Navigate to the AWS CloudFormation console in your preferred Region.
Choose Create stack, then choose With new resources (standard).
Choose Upload a template file and choose the file you downloaded.
Choose Next.
Enter a name for the stack, such as ServerlessAggregationStack.
Note: If you deployed the stateless pipeline introduced in our earlier blog post, you need to give this stack a different name.
Choose Next.
Leave all remaining defaults and choose Next.
Select I acknowledge that AWS CloudFormation… and choose Create stack.
Stack creation takes 1–2 minutes. When it’s complete, we’re ready to run the pipeline.
On the AWS Cloud9 console, locate the instance StatefulDataProducer.
If you don’t see it, make sure you’re in the same Region that you used to create the CloudFormation stack.
Choose Open IDE.
Open a terminal and run the following commands to prepare the pipeline:
The pipeline is ready!
Start the front end with the following code:
Open an additional terminal and start the producer:
The data from the producer should start arriving in batches at the front end. When you run the pipeline for the first time, you may see a few seconds of initial latency. You can confirm the accuracy of the aggregation by comparing the two sets of numbers.
Before you run the producer again, you may want to reset the aggregation table displayed in the front end by running the following commands:
Clean up
Clean up your resources to prevent unexpected costs:
On the AWS CloudFormation console, choose Stacks.
Select the stack you created (ServerlessAggregationStack).
Choose Delete.
Confirm by choosing Delete stack.
You should see the status DELETE_IN_PROGRESS and after 1–2 minutes, the delete should be complete and the stack disappears from the list.
Conclusion
In this series of posts, we discussed two architectural patterns for building near real-time, scalable, serverless data aggregation pipelines in the AWS Cloud. We started by introducing a generic map-and-reduce pattern using Lambda functions and DynamoDB, which can easily handle throughputs of 50,000 messages per second, while maintaining a single, consistent view on the aggregates. Next, we introduced state and the capability to modify the value of messages after ingestion, and extended the pipeline to handle not only modify, but also duplicates and out-of-order messages, remain tolerant to failures in any of the components of the pipeline, and ensure exactly-once processing of every message.
With the examples outlined in this post, you should have a good understanding of how to deploy serverless data aggregation pipelines with different levels of consistency in the AWS Cloud. With the provided CloudFormation templates, you can adjust the schema and the aggregation logic to fit your workload, then deploy, run, and test it in minutes.
Both Lucas and Kirill are part of the of the Migration Acceleration team within Global Financial Services, that aims to accelerate our customers’ cloud journey. If you’re interested in running a pipeline like this in production or if you have other questions to the team, you can contact them with an e-mail to [email protected].
About the Authors
Lucas Rettenmeier is a Solutions Architect based in Munich, Germany. His journey at AWS started in Business Development. After completing his M.Sc. in Physics at Heidelberg University with a focus on Machine Learning, he re-joined in 2020 as a Solutions Architect. He’s part of the Acceleration team within Global Financial Services, that aims to accelerate our customers’ cloud journey. Lucas is especially passionate about purpose-built databases and serverless technologies. Outside of work, he spends the majority of his time in nature either cycling, hiking, skiing, or trying something new.
{kind=link}
Kirill Bogdanov is a Senior Solutions Architect in the Amazon Web Services (AWS) for Global Financial Services. He provides cloud-native architecture designs and prototype implementations to build highly reliable, scalable, secure, and cost-efficient solutions ensuring the customers’ long-term business objectives and strategies. Kirill is a Ph.D. in Computer Science from KTH Royal Institute of Technology with expertise in distributed systems and High-Performance Computing (HPC). He has 12 years of experience in R&D, cloud migration, developing large-scale innovative solutions leveraging cloud technologies, and driving digital transformation.
{kind=link}
Read MoreAWS Database Blog