

{kind=link}
In recent years, natural language understanding (NLU) has increasingly found business value, fueled by model improvements as well as the scalability and cost-efficiency of cloud-based infrastructure. Specifically, the Transformer deep learning architecture, often implemented in the form of BERT models, has been highly successful, but training, fine-tuning, and optimizing these models has proven to be a challenging problem. Thanks to the AWS and Hugging Face collaboration, it’s now simpler to train and optimize NLU models on Amazon SageMaker using the SageMaker Python SDK, but sourcing labeled data for these models is still difficult and time-consuming.
One NLU problem of particular business interest is the task of question answering. In this post, we demonstrate how to build a custom question answering dataset using Amazon SageMaker Ground Truth to train a Hugging Face question answering NLU model.
Question answering challenges
Question answering entails a model automatically producing an answer to a query given some body of text that may or may not contain the answer. For example, given the following question, “What workflows does SageMaker Ground Truth support?” a model should be able to identify the segment “annotation consolidation and audit” in the following paragraph:
SageMaker Ground Truth helps improve the quality of labels through annotation consolidation and audit workflows. Annotation consolidation is the process of collecting label inputs from two or more data labelers and combining them to create a single data label for your machine learning model. With built-in audit and review workflows, workers can perform label verification and make adjustments to improve accuracy.
This problem is challenging because it requires a model to comprehend the meaning of a question, rather than simply perform keyword search. Accurate models in this area can reduce customer support costs through powering intelligent chatbots, delivering high-quality voice assistant products, and driving online store revenue through personalized product question answering. One large dataset in this area is the Stanford Question Answering Dataset (SQuAD), a diverse question answering dataset that presents a model with short text passages and requires the model to predict the location of the answering text span in the passage. SQuAD is a reading comprehension dataset, consisting of questions posed by crowd workers on a set of Wikipedia articles, where the answer to every question is either a span of text from the corresponding passage, or otherwise marked impossible to answer.
One challenge in adapting SQuAD for business use cases is generating domain-specific custom datasets. This process of creating new question and answer datasets requires a specialized user interface that allows annotators to highlight spans and add questions to those spans. It must also be able to support the addition of impossible questions to support SQuAD 2.0 format, which includes non-answerable questions. These impossible questions help models gain additional understanding around which queries can’t be answered using the given passage. The custom worker templates in Ground Truth simplify the generation of these datasets by providing workers with a tailored annotation experience for creating question and answer datasets.
Solution overview
This solution creates and manages Ground Truth labeling jobs to label a domain-specific custom question-answer dataset using a custom annotation user interface. We use SageMaker to train, fine-tune, optimize, and deploy a Hugging Face BERT model built with PyTorch on a custom question answering dataset.
You can implement the solution by deploying the provided AWS CloudFormation template in your AWS account. AWS CloudFormation handles deploying the AWS Lambda functions that support pre-annotation and annotation consolidation for the annotation user interface. It also creates an Amazon Simple Storage Service (Amazon S3) bucket and the AWS Identity and Access Management (IAM) roles to use when creating a labeling job.
This post walks you through how to do the following:
Create your own question answering dataset, or augment an existing one using Ground Truth
Use Hugging Face datasets to combine and tokenize text
Fine-tune a BERT model on your question answering data using SageMaker training
Deploy your model to a SageMaker endpoint and visualize your results
Annotation user interface
We use a new custom worker task template with Ground Truth to add new annotations to the existing SQuAD dataset. This solution offers a worker task template as well as a pre-annotation Lambda function (which handles putting data into the user interface) and post-annotation Lambda function (which extracts results from the user interface after labeling is complete).
This custom worker task template gives you the ability to highlight text in the right pane, then add a corresponding question in the left pane that relates to the highlighted text. Highlighted text on the right pane can also be added to any previously created question. Moreover, you can add impossible questions according to SQuAD 2.0 format. Impossible questions allow models to reduce the number of unreliable false positive guesses when the passage is unable to answer a query.
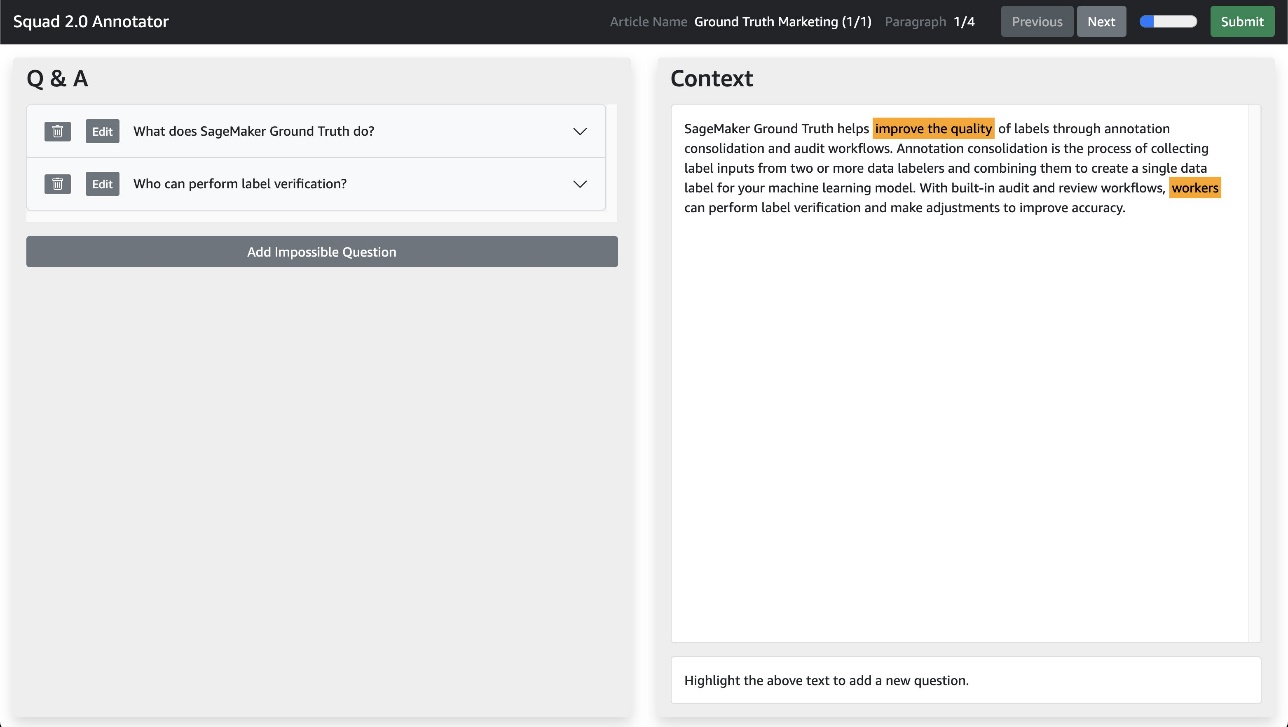{kind=link}
This user interface uses the same JSON schema as the SQuAD 2.0 dataset, which means it can operate over multiple articles and paragraphs, displaying one paragraph at a time using the Previous and Next buttons. The user interface makes it easy to monitor and determine the labeling work each annotator needs to complete during the task submission step.
Because the annotation UI is contained in a single Liquid HTML file, you can customize the labeling experience with knowledge of basic JavaScript. You can also modify Liquid tags to pass additional information into the labeling UI, and you can modify the template itself to include more detailed worker instructions.
Estimated costs
Deploying this solution can incur a maximum cost of around $20, not accounting for human labeling costs. Amazon S3, Lambda, SageMaker, and Ground Truth all offer the AWS Free Tier, with charges for additional usage. For more information, see the following pricing pages:
Amazon S3 Pricing
AWS Lambda Pricing
Amazon SageMaker Pricing
Amazon SageMaker Data Labeling Pricing – This fee depends on the type of workforce that you use. If you’re a new user of Ground Truth, we suggest using a private workforce and including yourself as a worker to test your labeling job configuration.
Prerequisites
To implement this solution, you should have the following prerequisites:
An AWS account.
Familiarity with Ground Truth. For more information, refer to Use Amazon SageMaker Ground Truth to Label Data.
Familiarity with AWS CloudFormation. For more information, refer to the AWS CloudFormation User Guide.
A SageMaker workforce. For this demonstration, we use a private workforce. You can create a workforce on the SageMaker console.
The following GIF demonstrates how to create a private workforce. For instructions, see Create an Amazon Cognito Workforce Using the Labeling Workforces Page.
Launch the CloudFormation Stack
Now that you’ve seen the structure of the solution, you deploy it into your account so you can run an example workflow. All the deployment steps related to the labeling pipeline are managed by AWS CloudFormation. This means AWS CloudFormation creates your pre-annotation and annotation consolidation Lambda functions, as well as an S3 bucket to store input and output data.
You can launch the stack in AWS Region us-east-1 on the AWS CloudFormation console using the Launch Stack button. To launch the stack in a different Region, use the instructions found in the README of the GitHub repository.
Operate the notebook
After the solution has been deployed to your account, a notebook instance named gt-hf-squad-notebook is available in your account. To start operating the notebook, complete the following steps:
On the Amazon SageMaker console, navigate to the notebook instance page.
Choose Open JupyterLab to open the instance.
Inside the instance, browse to the repository hf-gt-custom-qa and open the notebook hf_squad_finetuning.ipynb.
Choose conda_pytorch_p38 as your kernel.
Now that you’ve created a notebook instance and opened the notebook, you can run cells in the notebook to operate the solution. The remainder of this post provides additional details to each section in the notebook as you go along.
Download and inspect the data
The SQuAD dataset contains a training dataset as well as test and development datasets. The notebook downloads the SQuAD2.0 dataset for you, but you can choose which version of SQuAD to use by modifying the notebook cell under Download and inspect the data.
SQuAD was created by Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. For more information, refer to the original paper and dataset. SQuAD has been licensed by the authors under the Creative Commons Attribution-ShareAlike 4.0 International Public License.
Let’s look at an example question and answer pair from SQuAD:
Paragraph title: Immune_system
The immune system is a system of many biological structures and processes within an organism that protects against disease. To function properly, an immune system must detect a wide variety of agents, known as pathogens, from viruses to parasitic worms, and distinguish them from the organism’s own healthy tissue. In many species, the immune system can be classified into subsystems, such as the innate immune system versus the adaptive immune system, or humoral immunity versus cell-mediated immunity. In humans, the blood–brain barrier, blood–cerebrospinal fluid barrier, and similar fluid–brain barriers separate the peripheral immune system from the neuroimmune system which protects the brain.
Question: The immune system protects organisms against what?
Answer: disease
Load model
Now that you’ve viewed an example question and answer pair in SQuAD, you can download a model that you can fine-tune for question answering. Hugging Face allows you to easily download a base model that has undergone large-scale pre-training and reinitialize it for a different downstream task. In this case, you download the distilbert-base-uncased model and repurpose it for question answering using the AutoModelForQuestionAnswering class from Hugging Face. You also utilize the AutoTokenizer class to retrieve the model’s pre-trained tokenizer. We dive deeper into the model we use later in the post.
View BERT input
BERT requires you to transform text data into a numeric representation known as tokens. There are a variety of tokenizers available; the following tokens were created by a tokenizer specifically designed for BERT that you instantiate with a set vocabulary. Each token maps to a word in the vocabulary. Let’s look at the transformed immune system question and context you supply BERT for inference.
Model inference
Now that you’ve seen what BERT takes as input, let’s look at how you can get inference results from the model. The following code demonstrates how to use the previously generated tokenized input and return inference results from the model. Similar to how BERT can’t accept raw text as input, it doesn’t generate raw text as output either. You translate BERT’s output by identifying the start and end points in the paragraph that BERT identified as the answer. Then you map that output to our tokens and back to English text.
The translated results are as follows:
Question: The immune system protects organisms against what?
Answer: disease
Augment SQuAD
Next, to obtain additional labeled data, we use a custom worker task template in Ground Truth. We can first create a new article in SQuAD format. The notebook copies this file from the repo to Amazon S3, but feel free to make any edits before running the Augment SQuAD cell. The format of SQuAD is shown in the following code. Each SQuAD JSON file contains multiple articles stored in the data key. Each article has a title field and one or more paragraphs. These paragraphs contain segments of text called context and any associated questions in the qas list. Because we’re annotating from scratch, we can leave the qas list empty and just provide context. The user interface is able to loop across both paragraphs and articles, allowing you to make each worker task as large or small as desired.
After we generate a sample SQuAD data file, we need to create a Ground Truth augmented manifest file that refers to our input data. We do this by generating a JSON lines-formatted file with a “source” key corresponding to the location in Amazon S3 where we stored our input SQuAD data:
Access labeling portal
After you send the job to Ground Truth, you can view the generated labeling job on the Ground Truth console.
{kind=link}
To perform labeling, you need to log in to the worker portal account you created as a part of the prerequisite steps. Your job is available in the worker portal after a few minutes of pre-processing. After opening the task, you’re presented with the custom worker template for Q&A annotation. You can add questions by highlighting sections of text in the context, then choosing Add Question.
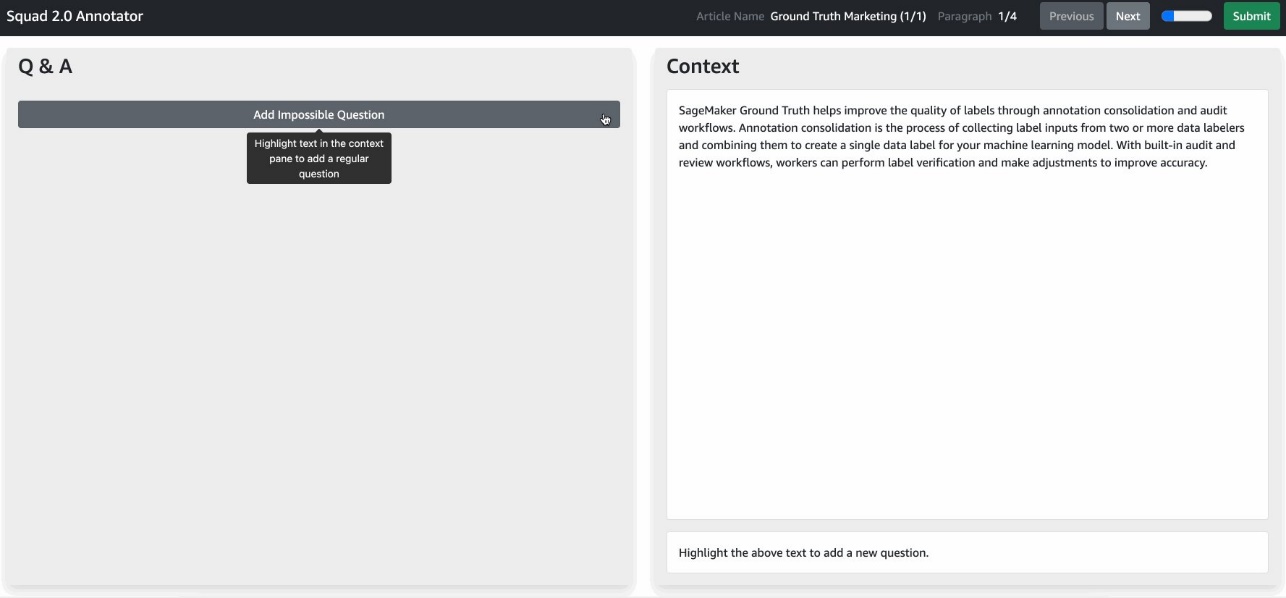{kind=link}
Check labeling job status
After submission, you can run the Check labeling job status cell to see if your labeling job is complete. Wait for completion before proceeding to further cells.
Load labeled data
After labeling, the output manifest contains an entry with your label attribute name (in this case squad-1626282229) containing an S3 URI to SQuAD-formatted data that you can use during training. See the following output manifest contents:
Each line in the manifest corresponds to a single worker task.
Load SQuAD train set
Hugging Face has a dataset package that provides you with the ability to download and preprocess SQuAD, but to add our custom questions and answers, we need to do a bit of processing. SQuAD is structured around sets of topics. Each topic has a variety of different context statements and each context statement has question and answer pairs. Because we want to create our own questions for training, we need to combine our questions with SQuAD. Luckily for us, our annotations are already in SQuAD format, so we can take our example labels and append them as a new topic to the existing SQuAD data.
Create a Hugging Face Dataset object
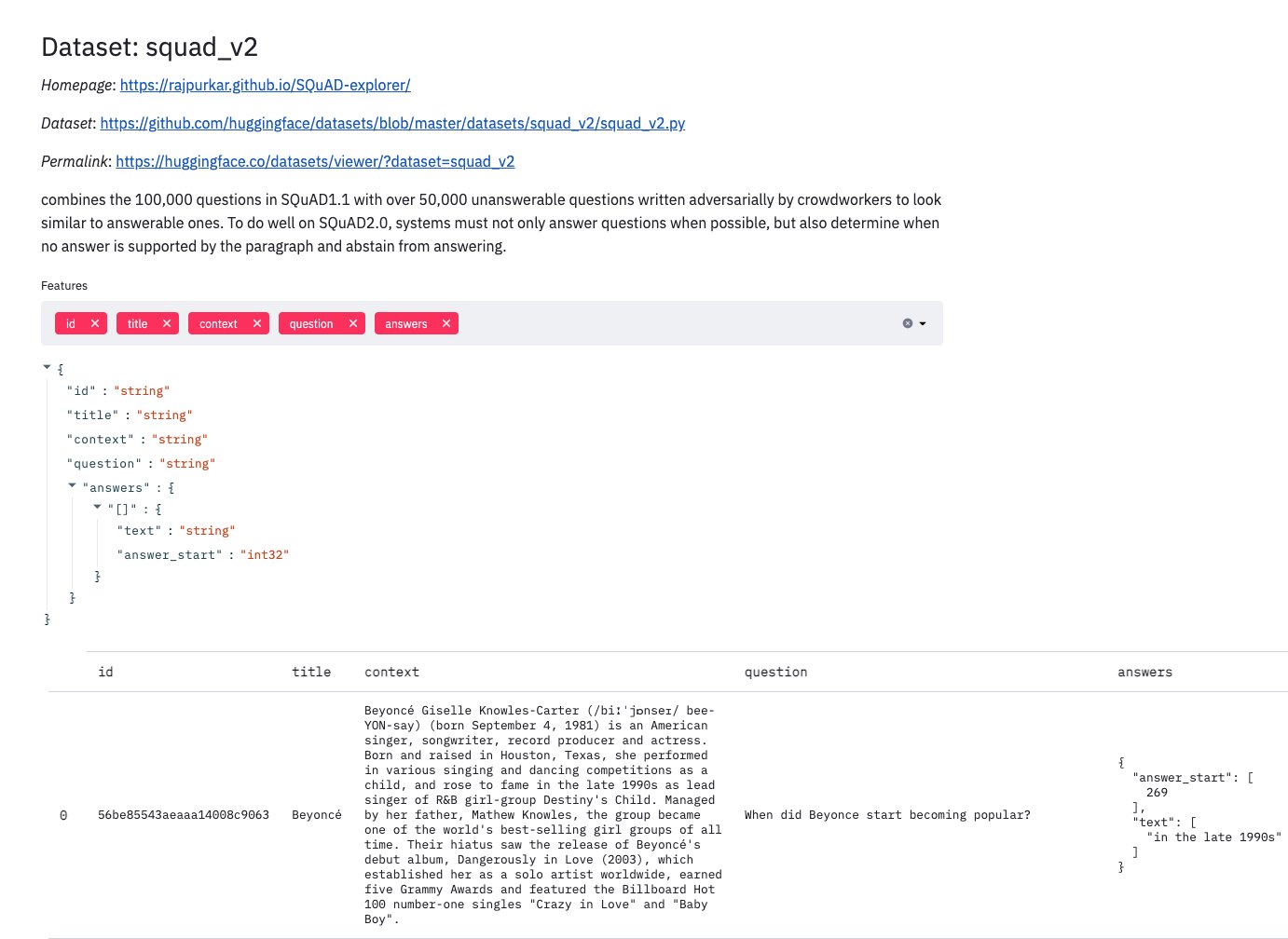
To get our data into Hugging Face’s dataset format, we have several options. We can use the load_dataset option, in which case we can supply a CSV, JSON, or text file that is loaded as a dataset object. You also can supply load_dataset with a processing script to convert your file into the desired format. For this post, we instead use the Dataset.from_dict() method, which allows us to supply an in-memory dictionary to create a dataset object. We also define our dataset features. We can view the features by using Hugging Face’s dataset viewer, as shown in the following screenshot.
{kind=link}
Our features are as follows:
ID – The ID of the text
title – The associated title for the topic
context – The context statement the model must search to find an answer
question – The question the model is being asked
answer – The accepted answer text and location in the context statement
Hugging Face datasets easily allow us to define this schema:
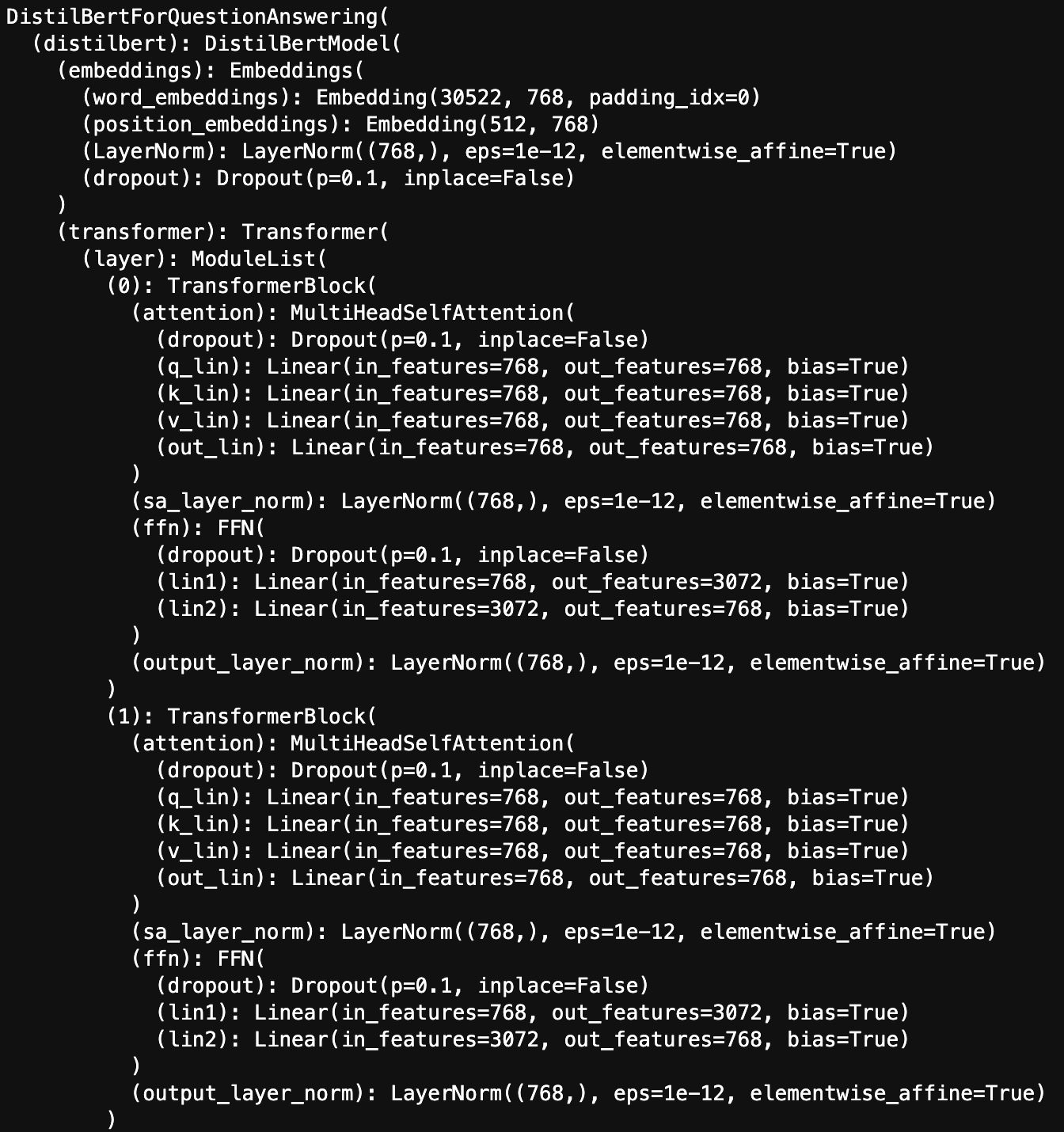
After we create our dataset object, we have to tokenize the text. Because models can’t accept raw text as an input, we need to convert our text into a numeric input that it can understand, otherwise known as tokenization. Tokenization is model specific, so let’s understand the model we’re going to fine-tune. We’re using a distilbert-base-uncased model. It looks very similar to BERT: it uses input embeddings, multi-head attention (for more information about this operation, refer to The Illustrated Transformer), and feed forward layers, but has half the parameters of the original BERT base model. See the following initial model layers:
{kind=link}
Let’s break down each component of the model’s title. The name distilbert denotes the fact that this is a distilled version of the BERT base model, which is obtained through a process called knowledge distillation. Knowledge distillation allows us to train a smaller student model on not only the training data but also the responses to the same training set from a larger pre-trained teacher model. base refers to the size of the model, in this case the model was distilled from a BERT base model (as opposed to a BERT large model). uncased refers to the text it was trained on. In this case the text didn’t account for case; all the text it was trained on was lowercase. The uncased aspect directly affects the way we tokenize our text. Thankfully, in addition to providing easy access to downloading transformer models, Hugging Face also provides the model’s accompanying tokenizer. We also downloaded a customized tokenizer for our distilbert-base-uncased model that we now use to transform our text:
Another feature of the dataset class is it allows us to run preprocessing and tokenization in parallel with its map function. We define a processing function and then pass it to the map method.
For question answering, Hugging Face needs several components (which are also defined in the glossary):
attention mask – A mask indicating to the model which tokens to pay attention to, used primarily for differentiating between actual text and padding tokens
start_positions – The start position of the answer in the text
end_positions – The end position of the answer in the text
input_ids – The token indices mapping the tokens to the vocabulary
Our tokenizer will tokenize the text, but we need to explicitly capture the start and end positions of our answer, which is why we have defined a custom preprocessing function. Now that we have our inputs ready, let’s start training!
Launch training job
We can run training in our notebook, but the types of instances we need to train our Q&A model in a reasonable amount of time, p3 and p4 instances, are rather powerful. These instances tend to be overkill for running a notebook or as a persistent Amazon Elastic Compute Cloud (Amazon EC2) instance. This is where SageMaker training comes in. SageMaker training allows you to launch a training job on a specified instance or instances that are only up for the duration of the training job. This allows us to run on larger instances like the p4d.24xlarge, with 8 NVIDIA A100 GPUs, but without worrying about running up a huge bill in case we forget to turn it off. It also gives us easy access to other SageMaker functionalities, like SageMaker Experiments for tracking your ML training runs and SageMaker Debugger for understanding and profiling your training jobs.
Local training
Let’s start by understanding how training a model in Hugging Face works locally, then go over the adjustments we make to run it in SageMaker.
Hugging Face makes training easy through the use of their trainer class. The trainer class allows us to pass in our model, our train and validation datasets, our hyperparameters, and even our tokenizer. Because we already have our model as well as our training and validation sets, we only need to define our hyperparameters. We can do this through the TrainingArguments class. This allows us to specify things like the learning rate, batch size, number of epochs, and more in-depth parameters like weight decay or a learning rate scheduling strategy. After we define our TrainingArguments, we can pass in our model, training set, validation set, and arguments to instantiate our trainer class. Then we can simply call trainer.train() to start training our model. The following code block demonstrates how to run local training:
Send data to S3
Doing the same thing in SageMaker training is straightforward. The first step is putting our data in Amazon S3 so that our model can access it. SageMaker training allows you to specify a data source; you can use sources like Amazon S3, Amazon Elastic File System (Amazon EFS), or Amazon FSx for Lustre for high-performance data ingestion. In our case, our augmented SQuAD dataset isn’t particularly large, so Amazon S3 is a good choice. We upload our training data to a folder in Amazon S3 and when SageMaker spins up our training instance, it downloads the data from our specified location.
Instantiate the model
To launch our training job, we can use the built-in Hugging Face estimator in the SageMaker SDK. SageMaker uses the estimator class to define the parameters for a training job as well as the number and type of instances to use for training. SageMaker training is built around the use of Docker containers. You can use the default containers in SageMaker or supply your own custom container for training. In the case of Hugging Face models, SageMaker has built-in Hugging Face containers with all the dependencies you need to run Hugging Face training jobs. All we need to do is define our training script, which our Hugging Face container uses as its entry point.
In this training script, we define our arguments, which we pass to our entry point in the form of a set of hyperparameters, as well as our training code. Our training code is the same as if we were running it locally; we can simply use the TrainingArguments and then pass them to a trainer object. The only difference is we need to specify the output location for our model to be in /opt/ml/model so that SageMaker training can take it, package it, and send it to Amazon S3. The following code block shows how to instantiate our Hugging Face estimator:
Fine-tune the model
For our specific training job, we use a p3.8xlarge instance consisting of 4 V100 GPUs. The trainer class automatically supports training on multi-GPU instances so we don’t need any additional setup to account for this. We train our model for two epochs, with a batch size of 16, and a learning rate of 4e5. We’re also enabling mixed precision training, which uses mixed precision in areas where we can reduce numerical precision without impacting our model’s accuracy. This increases our available memory and training speeds. To launch the training job, we call the fit method from our huggingface_estimator class.
When our model is done training, we can download the model locally and load it into our notebook’s memory to test it, which is demonstrated in the notebook. We will focus on another option, deploying it as a SageMaker endpoint!
Deploy trained model
In addition to providing utilities for training, SageMaker can also allow data scientists and ML engineers to easily deploy REST endpoints for their trained models. You can deploy models trained in or outside of SageMaker. For more information, refer to Deploy a Model in Amazon SageMaker.
Because our model was trained in SageMaker, it’s already in the correct format to deploy as an endpoint. Similar to training, we define a SageMaker model class that defines the model, serving code, and the number and type of instances we want to deploy as endpoints. Also similar to training, serving is based on Docker containers, and we can use either of the built-in SageMaker containers or supply our own. For this post, we use a built-in PyTorch serving container, so we simply need to define a few things to get our endpoint up and running. Our serving code needs four functions:
model_fn – Defines how the endpoint loads the model (it only does this once, and then keeps it in memory for subsequent predictions)
input_fn – Defines how the input is deserialized and processed
predict_fn – Defines how our model makes predictions on our input
output_fn – Defines how the endpoint formats and sends back the output data to the client making the request
After we define these functions, we can deploy our endpoint and pass it context statements and questions and return its predicted answer:
Visualize model results
Because we deployed a SageMaker endpoint that allows us to send context statements and receive answers, we can go back and visualize the resulting inferences within the original SQuAD viewer to better visualize what our model found in the passage context. We do this by reformatting the results of inference back into SQuAD format, then replacing the Liquid tags in the worker template with the SQuAD-formatted JSON. We can then iframe the resulting UI inside our worker template to iteratively review results within the context of a single notebook, as shown in the following screenshot. Each question on the left can be clicked to highlight the spans of text on the right matching the query. With no question selected, all text spans are highlighted on the right as shown below.
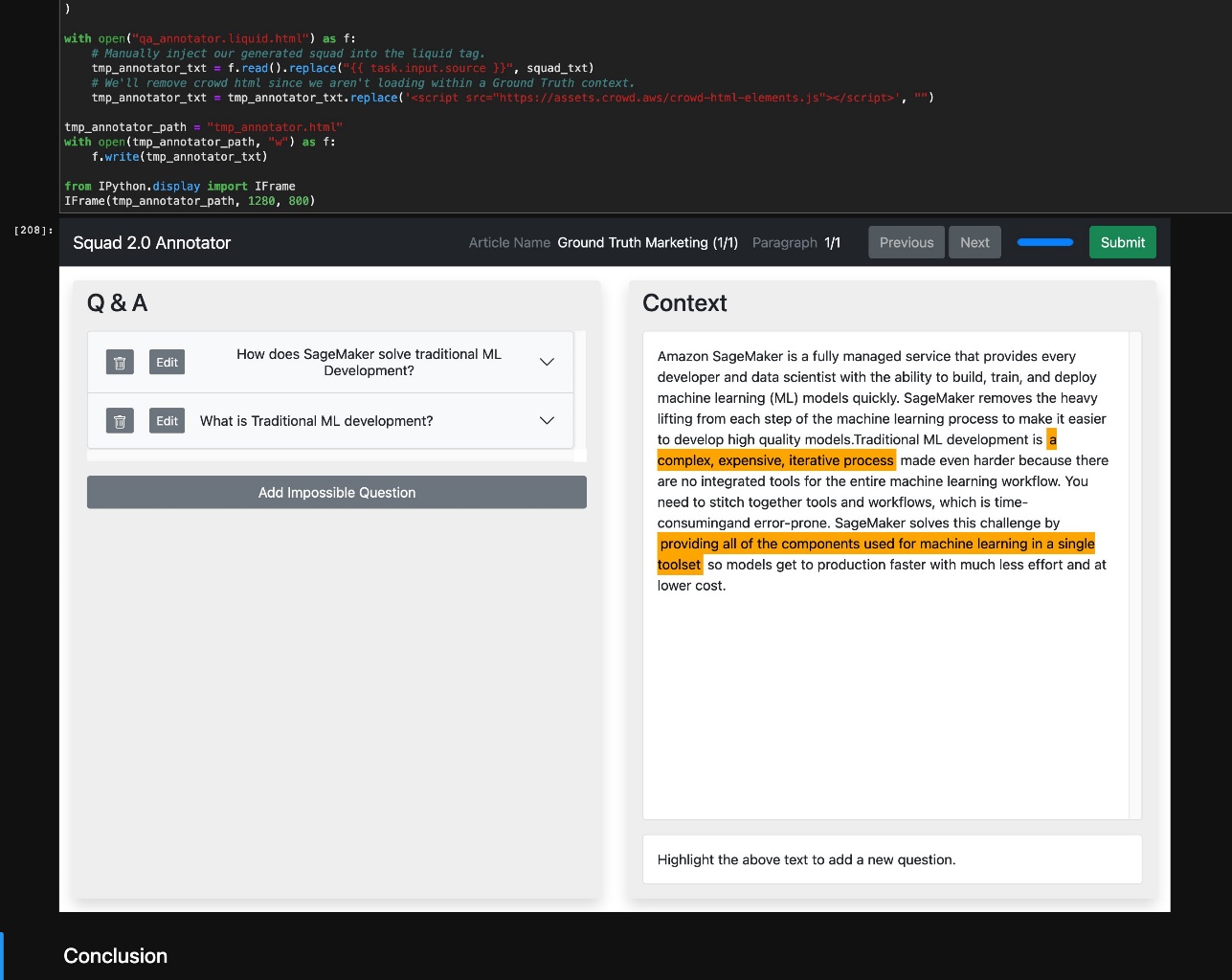{kind=link}
Clean up
To avoid incurring future charges, run the Clean up section of the notebook to delete all the resources, including SageMaker endpoints, S3 objects that contains the raw and processed dataset, and the CloudFormation stack. When the deletion is complete, make sure to stop and delete the notebook instance that is hosting the current notebook script.
Conclusion
In this post, you learned how to create your own question answering dataset using Ground Truth and combine it with SQuAD to train and deploy your own question answering model using SageMaker. After you complete the notebook, you have a deployed SageMaker endpoint that was trained on your custom Q&A dataset. This endpoint is ready for integration into your production NLU workflows, because SageMaker endpoints are available through standard REST APIs. You also have an annotated custom dataset in SQuAD 2.0 format, which allows you to retrain your existing model or try training other question answering model architectures. Finally, you have a mechanism to quickly visualize the results from your inference by loading the worker template in your local notebook.
Try out the notebook, augment it with your own questions, and train and deploy your own custom question answering model for your NLU use cases!
Happy building!
About the Authors
Jeremy Feltracco is a Software Development Engineer with the Amazon ML Solutions Lab at Amazon Web Services. He uses his background in computer vision, robotics, and machine learning to help AWS customers accelerate their AI adoption.
Vidya Sagar Ravipati is a Manager at the Amazon ML Solutions Lab, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption. Previously, he was a Machine Learning Engineer in Connectivity Services at Amazon who helped to build personalization and predictive maintenance platforms.
Isaac Privitera is a Senior Data Scientist at the Amazon Machine Learning Solutions Lab, where he develops bespoke machine learning and deep learning solutions to address customers’ business problems. He works primarily in the computer vision space, focusing on enabling AWS customers with distributed training and active learning.
Read MoreAWS Machine Learning Blog