

{kind=link}
Hopefully you’ve been following along with our BigQuery Admin series and are well on your way to getting ramped up with BigQuery. Now that you’re equipped with the fundamentals, let’s talk about something that’s relevant for all data professionals – data governance.
What does data governance mean?
Data governance is everything you do to ensure your data is secure, private, accurate, available, and usable inside of BigQuery. With good governance, everyone in your organization can easily find – and leverage – the data they need to make effective decisions. All while minimizing the overall risk of data leakage or misuse, and ensuring regulatory compliance.
BigQuery security features
Because BigQuery is a fully-managed service, we take care of a lot of the hard stuff for you! Like we talked about in our post on BigQuery Storage Internals, BigQuery data is replicated across data centers to ensure reliability and availability. Plus data is always encrypted at rest. By default, we’ll manage encryption keys for you. However, you have the option to leverage customer managed encryption keys, by using Cloud KMS to automatically rotate and destroy encryption keys.
You can also leverage Google Virtual Private Cloud (VPC) Service Controls to restrict traffic to BigQuery. When you correctly apply these controls, unauthorized networks can’t access BigQuery data, and data can’t be copied to unauthorized Google Cloud projects. Free communication can still occur within the perimeter, but communication is restricted across the perimeter.
Aside from leveraging BigQuery’s out-of-the-box security features, there are also ways to improve governance from a process perspective. In this post, we’ll walk you through the different tactics to ensure data governance at your organization.
Dataset onboarding: Understanding & classifying data
Data governance starts with dataset onboarding. Let’s say you just received a request from someone on your eCommerce team to add a new dataset that contains customer transactions. The first thing you’ll need to do is understand the data. You might start by asking questions like these:
What information does this contain?How will it be used to make business decisions?Who needs access to this data?Where does the data come from, and how will analysts get access to it in BigQuery?
Understanding the data helps you make decisions on where the new table should live in BigQuery, who should have access to this data, and how you’ll plan to make the data accessible inside of BigQuery (e.g. leveraging an external table, batch loading data into native storage, etc.).
For this example, the transactions live in an OLTP database. Let’s take a look at what information is contained in the existing table in our database. Below, we can see that this table has information about the order (when it was placed, who purchased it, any additional comments for the order), and details on the items that were purchased (the item ID, cost, category, etc.).
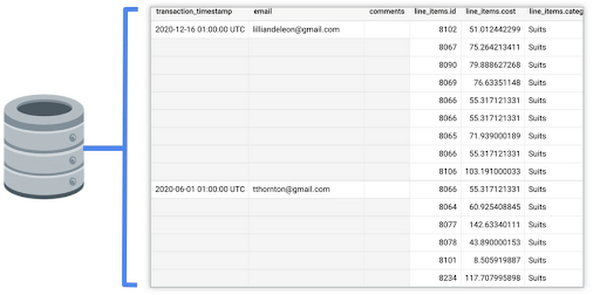{kind=link}
Now that we have an idea of what data exists in the source, and what information is relevant for the business, we can determine which fields we need in our BigQuery table and what transformations are necessary to push the data into a production environment.
Classifying information
Data classification means that you are identifying the types of information contained in the data, and storing it as searchable metadata. By properly classifying data you can make sure that it’s handled and shared appropriately, and that data is discoverable across your organization.
Since we know what the production table should look like, we can go ahead and create an empty BigQuery table, with the appropriate schema, that will house the transactions.
As far as storing metadata about this new table, we have two different options.
Using labels
On the one hand, we can leverage labels. Labels can be used on many BigQuery resourcesincluding Projects, Datasets and Tables. They are key:value pairs and can be used to filter data in Cloud Monitoring, or can be used in queries against the Information Schema to find data that pertains to specific use cases.
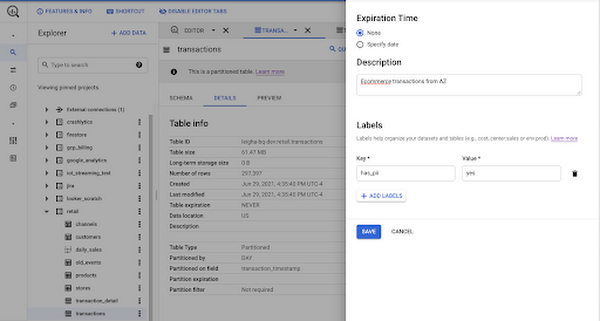{kind=link}
Although labels provide logical segregation and management of different business purposes in the Cloud ecosystem, they are not meant to be used in the context of data governance. Labels cannot specify a schema, and you can’t apply them to specific fields in your table. Labels cannot be used to establish access policies or track resource hierarchy.
It’s pretty clear that our transactions table may contain personally identifiable information (PII). Specifically, we may want to mark the email address column as “Has_PII” : True. Instead of using labels on our new table, we’ll leverage Data Catalog to establish a robust data governance policy, incorporating metadata tags on BigQuery resources and individual fields.
Using data catalog tags
Data Catalog is Google Cloud’s data discovery and metadata management service. As soon as you create a new table in BigQuery, it is automatically discoverable in Data Catalog. Data Catalog tracks all technical metadata related to a table, such as name, description, time of creation, column names and datatypes, and others.
In addition to the metadata that is captured through the BigQuery integration, you can create schematized tagsto track additional business information. For example, you may want to create a tag that tracks information about the source of the data, the analytics use case related to the data, or column-level information related to security and sharing. Going back to that email column we mentioned earlier, we can simply attach a column-level governance tag to the field and fill out the information by specifying that email_address is not encrypted, it does contain PII, and more specifically it contains an email address.
While this may seem like a fairly manual process, Data Catalog has a fully equipped API which allows for tags to be created, attached and updated programmatically. With tags and technical metadata captured in a single location, data consumers can come to Data Catalog and search for what they need.
Ingesting & staging data
With metadata for the production table in place, we need to focus on how to push data into this new table. As you probably know, there are lots of different ways to pre-process and ingest data into BigQuery. Often customers choose to stage data in Google Cloud Services to kick off transformation, classification or de-identification workflows. There are two pretty common paths for staging data for batch loading:
Stage data in a Google Cloud storage bucket: Pushing data into a Google Cloud storage bucket before directly ingesting it into BigQuery offers flexibility in terms of data structure and may be less expensive for storing large amounts of information. Additionally, you can easily kick off workflows when new data lands in a bucket by using PubSub to trigger transformation jobs. However, since transformations will happen outside of the BigQuery service, data engineers will need familiarity with other tools or languages. Blob storage also makes it difficult to track column-level metadata.Stage data in a BigQuery staging container: Pushing data into BigQuery gives you the opportunity to track metadata for specific fields earlier in the funnel, through BigQuery’s integration with Data Catalog. When running scan jobs with Data Loss Prevention (we’ll cover this in the next section), you can leave out specific columns and store the results directly in the staging table’s metadata inside of Data Catalog. Additionally, transformations to prepare data for production can be done using SQL statements, which may make them easier to develop and manage.
Identifying (and de-identifying) sensitive information
One of the hardest problems related to data governance is identifying any sensitive information in new data. Earlier we talked through tracking known metadata in Data Catalog, but what happens if we don’t know if data contains any sensitive information? This might be especially useful for free-form text fields, like the comments field in our transactions. With the data staged in Google Cloud, there’s an opportunity to programmatically identify any PII, or even remove sensitive information from the data, using Data Loss Prevention (DLP).
DLP can be used to scan data for different types of sensitive information such as names, email addresses, locations, credit card numbers and others. You can kick off a scan job directly from BigQuery, Data Catalog, or the DLP service or API. DLP can be used to scan data that is staged in BigQuery or in Google Cloud. Additionally, for data stored in BigQuery, you can have DLP push the results of the scan directly into Data Catalog.
You can also use the DLP API to de-identify data. For example, we may want to replace any instances of names, email addresses and locations with an asterisk (“*”). In our case, we can leverage DLP specifically to scan the comments column from our staging table in BigQuery, save the results in Data Catalog, and, if there are instances of sensitive data, run a de-identification workflow before pushing the sanitized data into the production table. Note that building a pipeline like the one we’re describing does require the use of some other tools.
We could use a Cloud Function to make the API call, and an orchestration tool like Cloud Composer to run each step in the workflow (trying to decide on the right orchestration tool? check out this post). You can walk through an example of running a de-identification workflow using DLP and composer in this post.
Data sharing
BigQuery Identity Access Management
Google Cloud as a whole leverages Identity Access Management (IAM) to manage permissions across cloud resources. With IAM, you manage access control by defining who (identity) has what access (role) for which resource. BigQuery, like other Google Cloud resources, has several predefined roles. Or you can create custom roles based on more granular permissions.
When it comes to granting access to BigQuery data, many administrators chose to grant Google Groups, representing your company’s different departments, access to specific datasets or projects – so policies are simple to manage. You can see some examples of different business scenarios and the recommended access policies here.
In our retail use case, we have one project for each team. Each team’s Google Group would be granted the BigQuery Data Viewer role to access information stored in their team’s project. However, there may be cases where someone from the ecommerce team needs data from a different project – like the product development team project. One way to grant limited access to data is through the use of authorized views.
Protecting data with authorized views
Giving a view access to a dataset is also known as creating an authorized view in BigQuery. An authorized view allows you to share query results with particular users and groups without giving them access to the underlying source data. So in our case, we can simply write a query to grab the pieces of information the ecommerce team needs to effectively analyze the data and save that view into the existing ecommerce project that they already have access to.
Column-level access policies
Aside from controlling access to data using standard IAM roles, or granting access to query results through authorized views, you also can leverage BigQuery’s column-level access policies. For example, remember that email address column we marked as containing PII earlier in this post? We may want to ensure that only members with high-security level clearance have access to query those columns. We can do this by:
First defining a taxonomy in Data Catalog, including a “High” policy tag for fields with high-security level clearanceNext, add our group of users who need access to highly sensitive data as Fine Grained Access Readers to the High resourceFinally, we can set a policy tag on the email column
Row-level access policies
Aside from restricting access to certain fields in our new table, we may want to only grant users access to rows that are relevant to them. One example may be if analysts from different business units only get access to rows that represent transactions for that business unit. In this case, the Google Group that represents the Activewear Team should only have access to orders that were placed on items categorized as “Active”. In BigQuery, we can accomplish this by creating a row-level access policy on the transactions table.
You can find some tips on creating row-level access policies in our documentation on best practices.
When to use what for data sharing
At the end of the day, you can achieve your goal of securing data using one or more of the concepts we discussed earlier. Authorized Views add a layer of abstraction to sharing data by providing the necessary information to certain users without giving them direct access to the underlying dataset. For cases where you want to transform (e.g. pre-aggregate before sharing) – authorized views are ideal. While authorized views can be used for managing column-level access, it may be preferable to leverage Data Catalog as you can easily centralize access knowledge in a single table’s metadata and control access through hierarchical taxonomies. Similarly, leveraging row level access policies, instead of authorized views to filter out rows, may be preferable in cases where it is easier to manage a single table with multiple access policies instead of multiple authorized views in different places.
Monitoring data quality
One last element of data governance that we’ll discuss here is monitoring data quality. The quality of your BigQuery data can drop for many different reasons – maybe there was a problem in the data source, or an error in your transformation pipeline. Either way, you’ll want to know if something is amiss and have a way to inform data consumers at your organization. Just like we described earlier, you can leverage an orchestration tool like Cloud Composer to create pipelines for running different SQL validation tests.
Validation tests can be created in a few different ways:
One option is to leverage open source frameworks, like this one that our professional services team put together. Using frameworks like these, you can declare rules for when validation tests pass or failSimilarly, you can use a tool like Dataform – which offers the ability to leverage YAML files to declare validation rules. Dataform recently came under the Google Cloud umbrella and will be open to new customers soon, join the waitlist here!Alternatively, you could always roll your own solution by programmatically running queries using built in BigQuery functionality like ASSERT, if the assertion is not valid then BigQuery will return an error that can inform the next step in your pipeline
Based on the outcome of the validation test, you can have Composer send you a notification using Slack or other built-in-notifiers. Finally, you can use Data Catalog’s API to update a tag that tracks the data quality for the given table. Check out some example code here! With this information added to Data Catalog, it becomes searchable by data consumers at your organization so that they can stay informed on the quality of information they use in their analysis.
What’s next?
One thing that we didn’t mention in this post, but is certainly relevant to data governance, is ongoing monitoring around usage auditing and access policies. We’ll be going into more details on this in a few weeks when we cover BigQuery monitoring as a whole. Be sure to keep an eye out for more in this series by following me on LinkedIn and Twitter!
Cloud BlogRead More