

{kind=link}
Google Cloud is excited to announce the general availability of time to live (TTL) for Cloud Spanner. As a part of a broader suite of enterprise management capabilities, TTL allows database administrators to set policies to periodically delete ephemeral, temporary, or unneeded data from Spanner tables. Purging unnecessary data helps:
Decrease storage and backup costs
Reduce the number of rows the database has to scan for some queries, potentially improving query performance
Adhere to regulations or industry guidelines that limit the retention time on certain types of data
TTL is ideal for regular clean-up activities and is designed to replace one-off clean-up scripts, reducing operational overhead and opportunities for manual errors. It runs continuously in the background, periodically deleting expired data in batches at a consistent timestamp. It is generally available to all Spanner customers today at no additional cost.
Example: Real-time route planning
To better understand how TTL helps reduce cost and complexity, let’s look at an example of a fictional delivery scheduling application. When a user requests a delivery, the app calculates multiple routing options and then selects the best one based on its optimization algorithm, for example, grouping packages together along the same route.
A simplified Spanner schema for this aspect of the application might look something like the following:
CalculatedRoutes holds the possible options for a given delivery. The RouteSteps table captures the related turn-by-turn routing for a given option. Each calculated route has many steps. The RouteSteps table is interleaved in its related CalculatedRoutes. Table interleaving is a helpful performance optimization for one-to-many related data that is frequently accessed together, for example, to display turn-by-turn directions or calculate the total score of a route in the optimization algorithm.
The quality and speed of the matching algorithm are key to the overall user experience. It’s critical that this data is highly available and consistent during the real-time optimization process. Spanner provides scale for these types of read-write, interactive workloads, with up to 99.999% availability and global consistency. Once a route is confirmed, the alternatives are no longer needed, though. For the high volume of deliveries that our fictitious app handles, this short-lived data is unwieldy. Spanner provides the ability for applications to set row-level deletion policies via TTL to better manage data.
Fully Managed Background Clean-up with TTL
Spanner supports deleting data today using DELETE in SQL or partitioned deletes. These are useful for removing data where you need precise control over the transaction boundaries or if you want to minimize the processing time by devoting high-priority resources. TTL complements this with a fully managed background process that minimizes the overall system impact—no need to deal with manual partitioning, batching, or retrying. With TTL you can just set it and forget it.
This new approach in Spanner has several important benefits:
Simplicity: Row deletion policies are declarative. You tell Spanner when rows are eligible to be deleted, not how to delete them. TTL logic is centrally defined in your schema, making it easy to manage along with the tables it governs and straightforward to reason over—no more digging through complex application code or external scripts to understand critical clean-up logic.
Scalability: TTL scales with your databases. Spanner seamlessly distributes the scanning for expired rows and their deletion across all nodes in your instance. As your database grows, TTL dynamically adjusts without additional intervention.
Predictability: TTL is designed to minimize the impact on other database workloads. The TTL sweeper process works in the background at system low priority. It spreads work over time and available instance resources more efficiently than what’s possible in custom queries for minimal overhead.
Observability: TTL is integrated into Cloud Monitoring for end-to-end insight into progress and warnings alongside the rest of your stack without additional plumbing for your developers to build and maintain.
Configuring a Row Deletion Policy
To see it in action, let’s configure Spanner to automatically remove the ephemeral calculated routes in our example after nine days.
The first step is to add a row deletion policy to the CalculatedRoutes table in the schema definition. As with other schema changes, setting or changing a row deletion policy is a privileged action.
A row deletion policy tells Spanner when rows in a table are eligible to be automatically deleted. It is based on a timestamp and an interval, for example, for a given row, “creation time plus nine days”. A row deletion policy’s timestamp column can use Spanner’s built-in commit timestamp for precise tracking using TrueTime.
Because we specified ON DELETE CASCADE on the interleaved child RouteSteps table above, those related rows will automatically be deleted in the same transaction as the parent route. This ensures referential integrity for a given route and its steps, even as routes are deleted in batches over multiple transactions.
Once you update the schema, TTL will automatically adjust its background scanning to accommodate all available policies, picking up any changes on it next cycle.
Time to Live Lifecycle
When a row becomes eligible to be removed under a row deletion policy it is not immediately unavailable for query. A background system process, or “sweeper”, checks daily for eligible rows and performs the actual deletes in batches, close to where the data is stored internally for efficiency. The sweeper automatically adjusts the batch size and retries on transient errors. It reduces the batch size, for example, if related indexes or interleaved children would cause a transaction to exceed the mutation limit. Even with retries, rows are typically removed, and thus rendered unavailable for query, within three days.
{kind=link}
A separate process reclaims storage from the deleted rows, typically within seven days.
More Sophisticated Expiration Logic
A simple timestamp plus an interval covers many common scenarios, but what about more sophisticated logic? For example, what if our fictitious delivery logistics planning app had an additional requirement to not delete data that was subject to a legal hold?
To implement this, we can use a generated column to capture the business logic and then attach the row deletion policy to that. This combination of generated columns and row deletion policies provides a flexible way to enable more advanced logic without creating overly complex or potentially conflicting rules.
Above, we’ve replaced the row deletion policy with a new one that’s attached to the generated ExpiredDate column. As before, the generated column must be a TIMESTAMP. The expired date uses a SQL statement to calculate the greater of the legal hold date or the creation date plus nine days, the original policy. Spanner ensures that the generated column will always be consistent with the columns it depends on.
The INTERVAL 0 DAY in the row deletion policy indicates that rows are immediately eligible for deletion at the specified timestamp. Our calculated policy moves the conditional interval logic into the generated column definition.
Monitoring Progress
Now that we have configured automatic cleanup of old routes, we can use Cloud Monitoring and built-in system tables to observe progress of the row clean-up in order to ensure we’re meeting our data disposal requirements and to identify any problems.
The metric, deleted_rows_count tracks the throughput of rows cleaned up by TTL. This throughput will fluctuate naturally as rows expire at different times throughout the day and as the sweeper parallelizes deletes across splits, or individual slices of data, distributed across nodes in a Spanner instance.
{kind=link}
The sweeper runs at different times on each split to minimize the overall load on the Spanner instance.
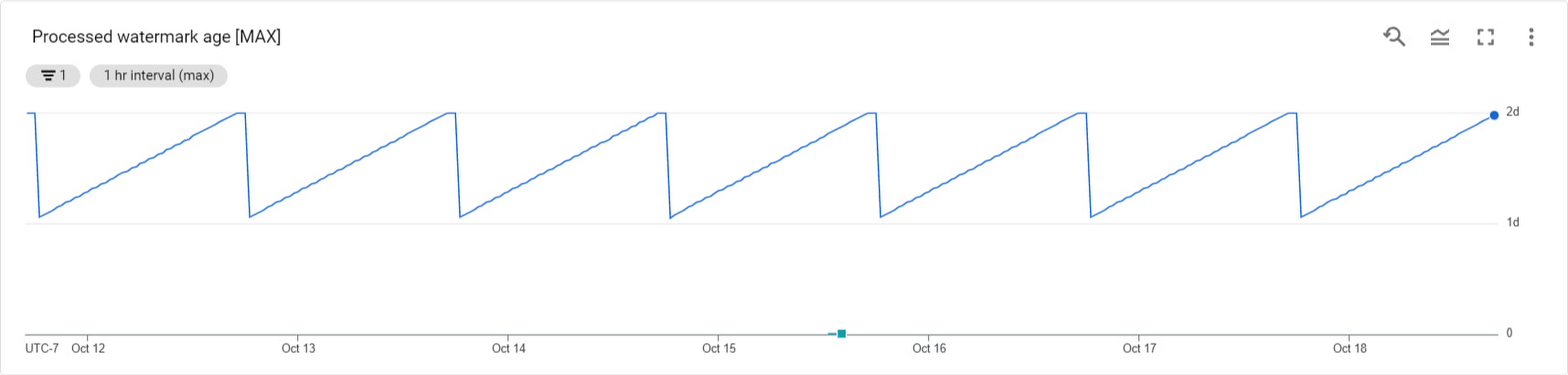
The processed_watermark_age metric tracks the time since the last successful sweep for eligible rows. If the TTL background sweeper has the resources it needs to scan the eligible data, you’ll see a regular sawtooth pattern over one to two days, as below. Eligible rows are typically deleted within three days in a properly resourced instance.
{kind=link}
You can configure notification if the TTL process takes longer than expected or if it encounters non-retryable errors. For our ride scheduling application, we’ll set an alert if processed_watermark_age exceeds three days.
An administrator can also query the built-in system tables to better understand the status of the TTL cleanup. For example, you can enumerate all tables where the clean-up was unsuccessful and check the timestamp of the oldest row that wasn’t able to be automatically deleted, such as due to a transaction constraint.
Get Started Today
Time to live (TTL) provides an automated way to periodically remove old, unneeded data in a Spanner database. This background clean-up reduces storage and backup costs and can improve performance for queries that need to scan lots of data. It also helps automate data retention policies.
Administrators attach row deletion policies to tables using a timestamp column and a time interval, for example, last updated plus 90 days. In the background, Spanner checks periodically for eligible rows and removes them in batches, including interleaved children. Unlike custom application code or scripts that administrators have to write manually, TTL automatically handles parallelization and retries, ensuring progress and minimal impact to other workloads without complex partitioning or error handling logic. TTL is available today for all Spanner databases at no additional cost. Learn more in the product documentation.
Cloud BlogRead More