

{kind=link}
This blog post was co-authored, and includes an introduction, by Aaron Brunko, Senior Vice President, Claims Product at Xactware.
Property insurance claims involving the valuation and replacement of personal belongings can be a painful process for everyone involved after a loss. From catastrophic events such as hurricanes, tornados, and wildfires, to theft and vandalism, claim handlers and policyholders can quickly become overwhelmed. When a loss occurs, the claim representative asks for a list of involved belongings to be included in the overall claim submission. The list (inventory) also includes specific information such as a detailed item description (including brand and model number when available), where the item was purchased, when it was purchased, how much was paid, and a general condition and usage of the item.
Take a moment and reflect on your own personal belongings. If you were asked at a moment’s notice to provide a detailed inventory, you may (like many people) have difficulty remembering how many button-down dress shirts you had in the closet, the number of knives that came in the set you purchased five years ago, or the number of sockets from the toolbox—let alone the specifics needed to properly value and adjust your claim. Hopefully, you have a digital record through photographs, videos, and online shopping orders that can help you piece the puzzle together.
Once your inventory is complete, you submit it to the assigned claim representative, who methodically determines coverage based on the terms of your insurance policy and begins evaluating the inventory. In most cases, the inventory is in a digital format, which can be imported directly into an estimating application where the claims representative will match each item with an item of like-kind, quality, and depreciation based on department, life expectancy, age, and condition.
When the claim representative completes the evaluation, they draft payment letters and provide you with payment of the actual cash value (most common) less your deductible and any amounts over your policy limits. If your policy allows for recoverable depreciation, you need to supply proof of purchase to collect the difference between the replacement cost and actual cash value.
In short, this laborious process can take months or even years until the last item is replaced and final payment is issued.
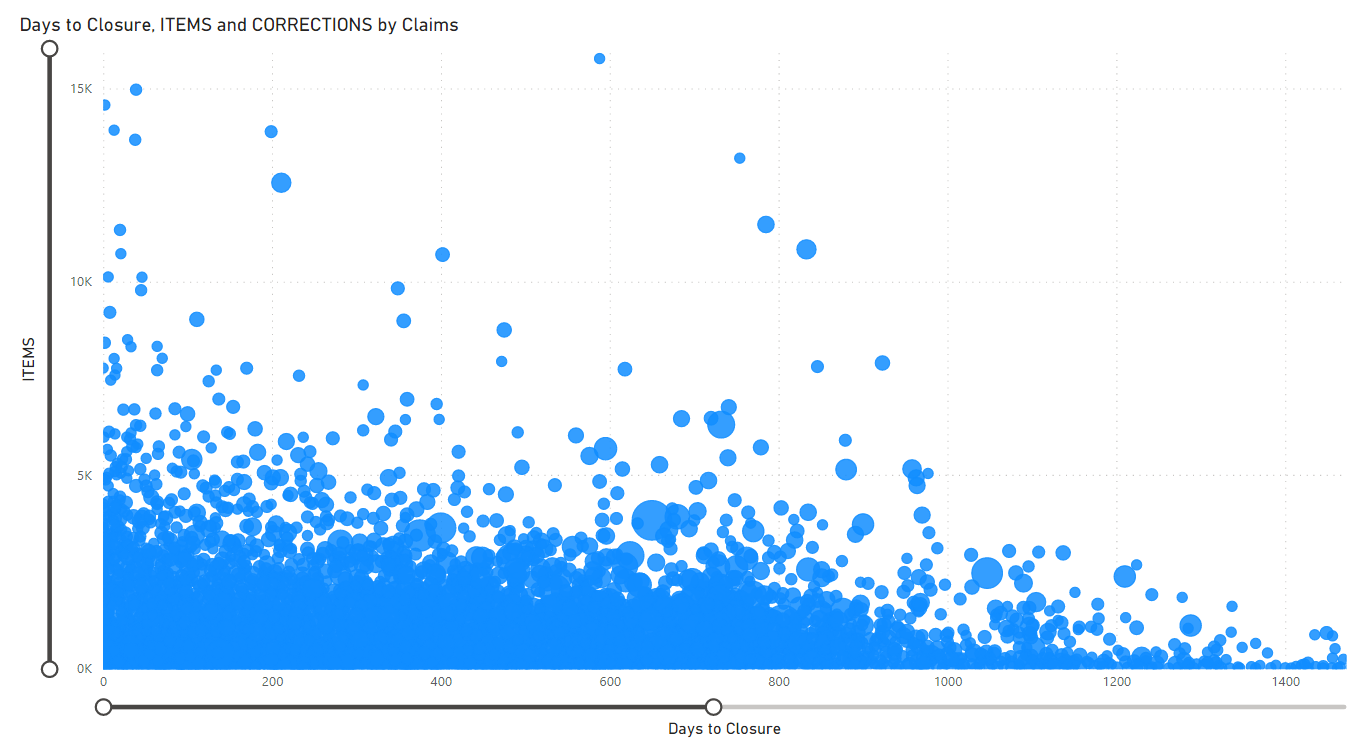
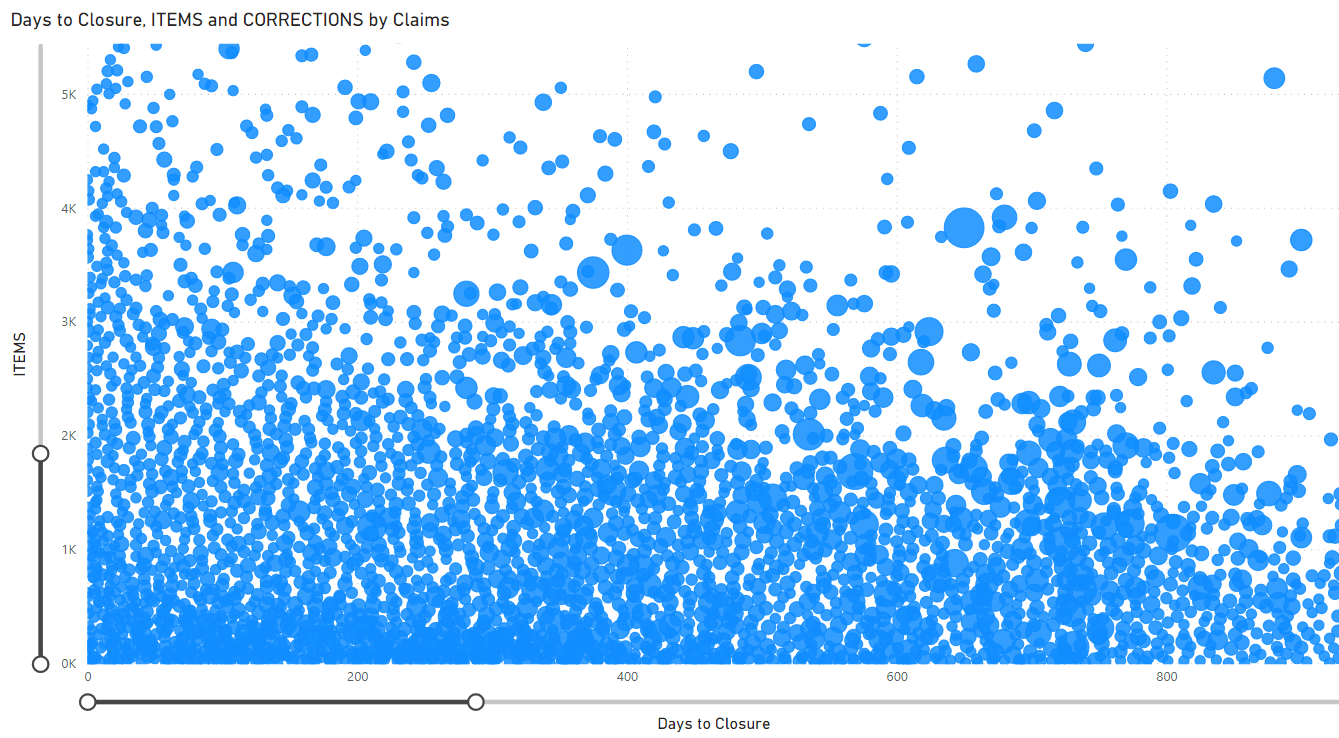
To further illustrate this point, Xactware Solutions helped process more than one million personal property claims between 2019 and 2020, totaling over 17 billion dollars of replacement cost value. During this time, more than 4.5 million items were recorded in the claims system, which took 37.76 days on average from when a claim was created until the last known change. In 2020 alone, the average days were 44.56 and the average number of corrections to the file were 1.01 (meaning on average each estimate had to be corrected at least one time).
As a senior executive of a large US-based insurer once put it, “We are all receiving a failing grade in the industry when it comes to personal property settlement. There is much improvement that can be made to streamline claims of all shapes and sizes, to better improve the policyholder experience, and at the same time reduce overhead costs for industry.”
The relationship displayed in the following graphs between the number of items, days to closure (last estimate upload), and number of corrections highlight clusters offer excellent starting points for us to move the needle in the right direction.
{kind=link}
{kind=link}
– Aaron Brunko
Automated claims processing
With advancements in analytics technology such as seamless shopping enabled by online retail and supply chain efficiencies, many consumers seek a similarly seamless experience when dealing with property insurance claims.
To address this growing opportunity, Xactware has made it a top organizational priority to improve the claims journey for the policyholder, with the concurrent aim of reducing the costs of claim servicing for insurance carriers.
To deliver on these priorities, Xactware has laid out a holistic vision of automating the claims lifecycle from start to finish across the claims workflow. Machine learning (ML) is a key technology to meet this end, and enables:
Streamlining the First Notice of Loss (FNOL) process
Automating the collection of loss details
Automating the decision-making and estimation of replacement items
Processing digital payments to claim filers.
To this end, Xactware engaged the Amazon ML Solutions Lab to help jumpstart the ML journey. Together they identified two high value business use cases that were selected to build two solutions demonstrating the use of ML to meet these objectives.
Both use cases focused on automating the categorization and line item matching of items that get submitted by a claim filer or policyholder as part of a loss claim, such as submitting a list of items that were stolen in a theft—a labor-intensive step in the workflow that a claims adjustor typically completes by manually querying and selecting items from a candidate items database spanning thousands of items. This automation is expected to further enable the automation of item lookups of a similar kind and quality and their associated depreciation schedules, which are two critical aspects that insurers need in order to derive the replacement cost value and depreciated amount to be factored for payment to the policyholder.
Specifically, these two use cases included:
Item classification – Using ML to correctly classify items based on the text descriptions entered by the policyholder into the correct categories and selectors (subcategories), which together span nearly 4,000 combined classes
Item matching – Using ML to match items to improve search results based on the text descriptions entered by the policyholder to identify and retrieve the correct candidate items from Xactware’s item database
Item classification
The first step to building an automated claims processing pipeline is to correctly identify the high-level class to which the item belongs. For example, an adjustor may query with the description “2015 kindle 4gb” as the item description and receive a list of candidate items. To narrow down this list, we begin by building a model that transforms the query into a precise group of products; in this case, the group is e-readers.
Over the years with deep experience in the insurance industry, Xactware has built a database of products including everything from Amazon Kindles to satin sheets. These items are classified according to their category and subcategory, known as the selector. By identifying the generic CatSel (category-selector pairs), we can refine the product match according to brand and model as described in the next section in this post. An example CatSel pair would be ELC-CPHN for the “cell phone” selector belonging to the “electronics” category class.
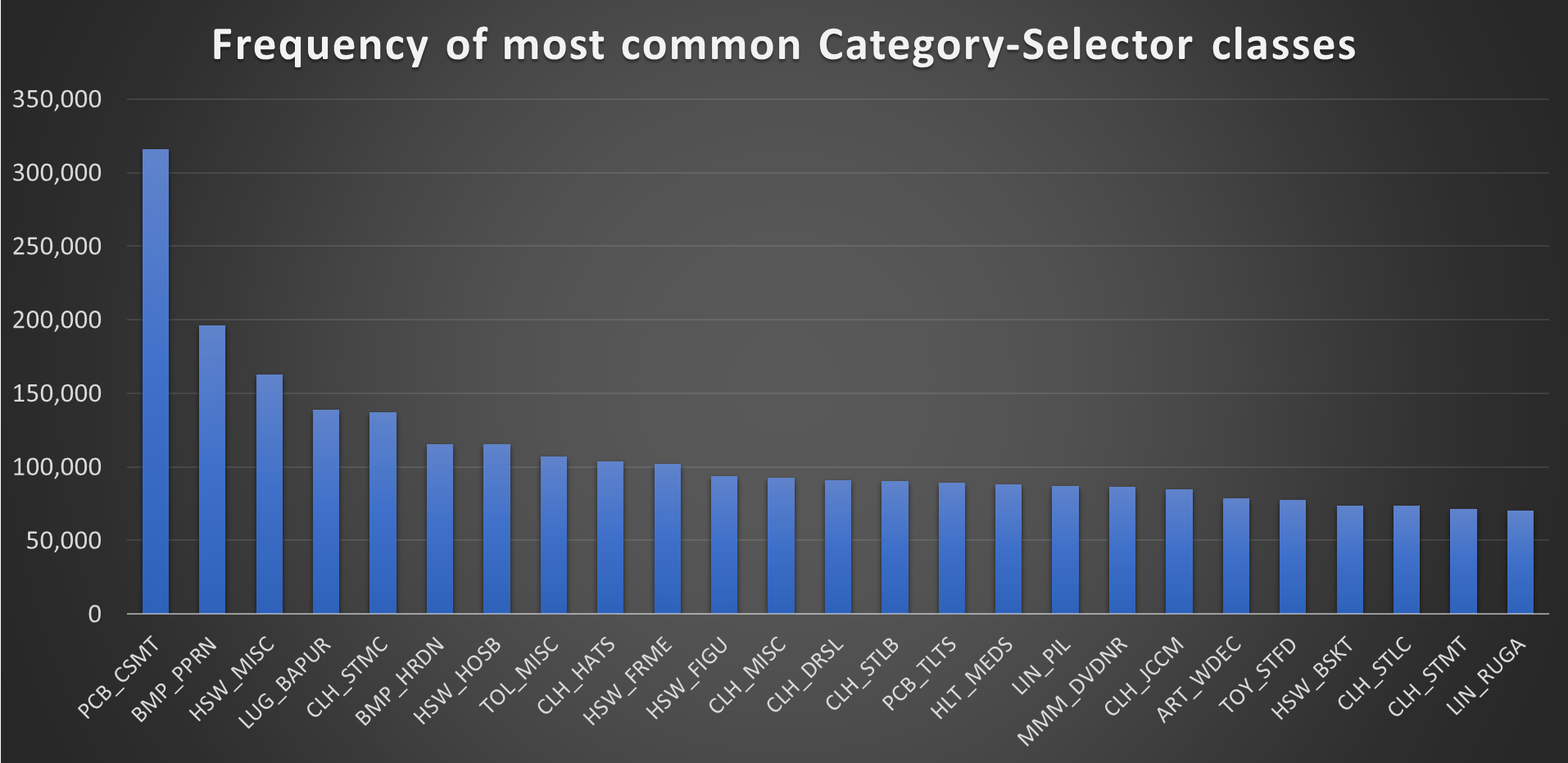
There are nearly 4,000 unique CatSel pairs, necessitating a large dataset to supply a sufficient number of samples so that the models have plenty of opportunity to correctly learn how to classify input data. In an ideal world, we would have data samples that are uniformly distributed across all labels, though that is unrealistic here. For examples, jewelry and clothing are much more likely to appear on a claims form than a musical instrument or an antique armoire. Although we can make efforts to rebalance the dataset, the underlying characteristics of the data are such that we expect model performance to vary by label. To get a sense of this uneven distribution, we plot the incidence counts for the 25 most common CatSels.
{kind=link}
Now that we understand the macroscopic properties of the data, we consider the specific contents of each sample. In addition to the user-input text description of an item, we also have user-input text descriptions of the room in which the item was lost—and how it was lost (such as flooding, theft, or fire). Therefore, our training data is text, for which predictive analytics are suitable to be built on natural language processing (NLP) ML algorithms. Rather than build a model from scratch, which would require significant data preparation (stemming, tokenizing), pretraining (language corpus, vectorizing) and infrastructure management (setting up training and inference instances), we can use Amazon Comprehend, which handles the undifferentiated heavy lifting of the ML cycle and is trained by a team of specialized NLP experts.
To produce optimal results balanced with an efficient use of hardware resources, Amazon Comprehend limits custom classification models to 1,000 unique labels. Given our nearly 4,000 labels, we built four separate classification models that, in aggregate, provide us with the predicted class of a line item. Experimenting with the number of training samples, feature preparation, feature selection, label distribution, and rebalancing methods, we ultimately generated a model that delivers a top five accuracy of 97.5% for categories and 73% for CatSel pairs. Top five accuracy refers to the percentage of inference instances in which one of the top five predicted labels is the true label. Not all labels, however, are given equal weights due to the skewed distribution of label instances.
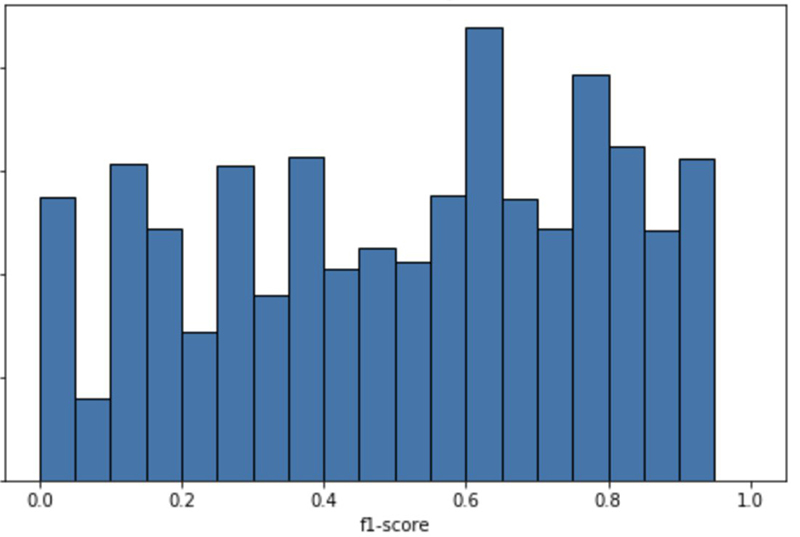
For each CatSel, we can check how the model performs. That is, we pass all instances of the true label through the models for inference and record the prediction. After looping through all CatSel labels, we end up with a set of F1 scores that we can then bin and plot as a histogram to visualize model performance across CatSels.
{kind=link}
Given the performance distribution across CatSels, we now have a sense of confidence around how precise a given prediction is. When the model predicts a label on which the models perform well, we can automate the rest of the insurance claim pipeline with low expectations of error. For other labels, we can continue the manual process of review while collecting additional data to feed back into the model for training and ultimately improve predictions across the board.
Item matching
Following the successful identification of the correct category or class to which the described item belongs (based on the category code and the selector code, CatSel), the attention of the claim processing pipeline shifts to identification of the actual item (its make, its model, and so on) that the policyholder has filed a claim for. Generally, the submitted item description may match with many similar items. The overall goal is to correctly identify the item that the policyholder had in mind while filing the claim. To achieve this goal, we built and trained an item-matching deep neural network (DNN) model using Amazon SageMaker, a comprehensive ML service with a broad set of capabilities purpose-built to help data scientists and developers quickly prepare, build, train, and deploy high-quality machine learning (ML) models.
The item-matching DNN model was built using PyTorch. We made use of FastText (and BERT) embeddings for handling text. The final version uses FastText embedding alone because using BERT embeddings didn’t produce any significant improvement over the FastText embedding for this use case, and generating FastText embeddings is less computationally intensive, therefore faster. The overall architecture of the item-matching DNN model is summarized in the following figure.
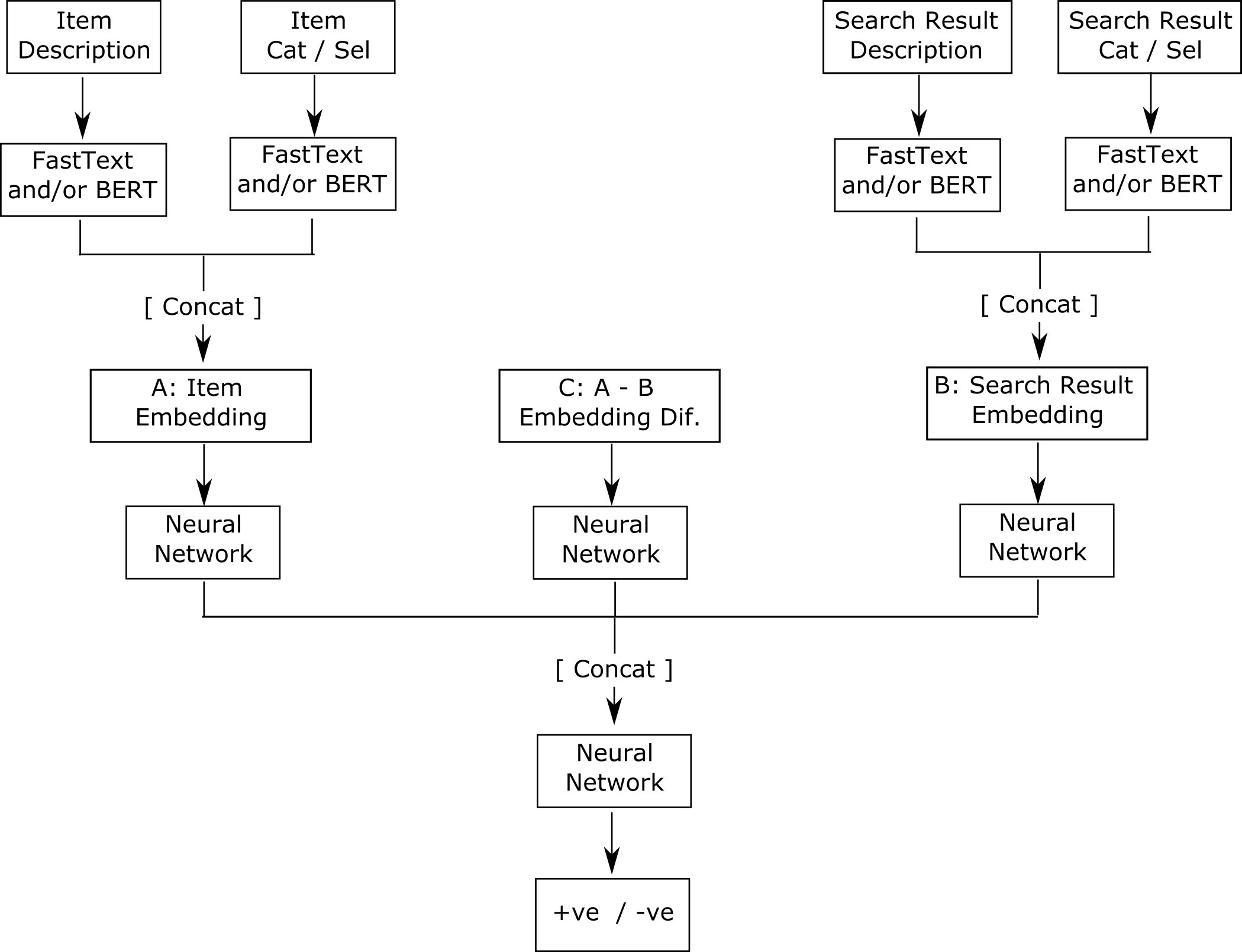{kind=link}
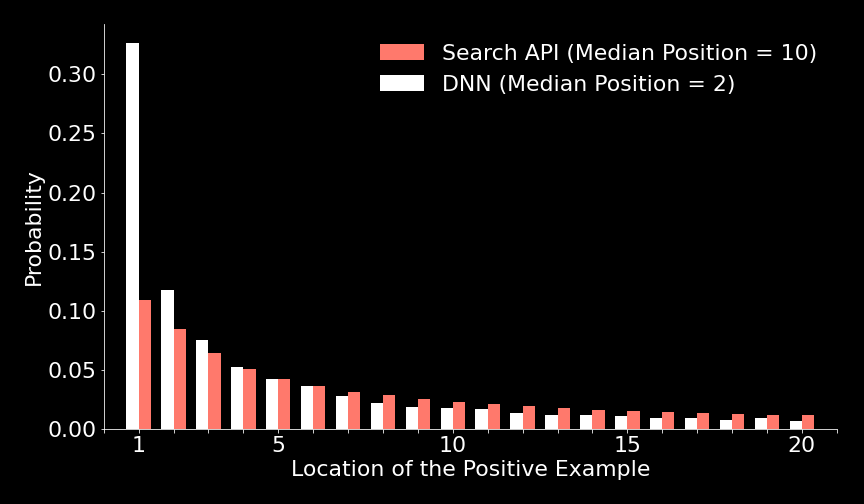
Essentially, the DNN model takes in the information of the item in the claim and the information of the items from the database that could potentially be the correct match. The potential correct matches are fetched from the database of items and presorted to a reasonable degree by an existing search API. After the model is fed this information, it outputs a number between 0 and 1 for each of the items returned by the search API. This number is an estimated probability that the item from the search API is the correct item for the filed claim. Because the estimated probability measures the level of confidence that a given item is the correct match, all the potential matches can be sorted in descending order using the estimated probabilities. If the estimated probabilities (and therefore the sorted list of matched items) are perfect, you can expect that the correct item ranks first and appears in the first location of the sorted list. We show the distribution of the location for the correct item in the search results and in the DNN results later in this section.
Generally, you can assess the relative improvement in the sorting of two lists by computing the normalized discounted cumulative gain (NDCG). However, in the current case, only the location of the correct item (positive matched item) is important, and the relative locations of all the negative items (that should not be selected, and which make up 99 of 100 shortlisted items) is of little interest. As an alternative to NDCG, you could also compare two lists of the items, obtained from two independent sorting methods, by looking at the median location of the correct item (the median location of the item of interest) in the sorted lists. Given its simplicity and intuitiveness to the readers and users, the median approach is very insightful, and we use it here.
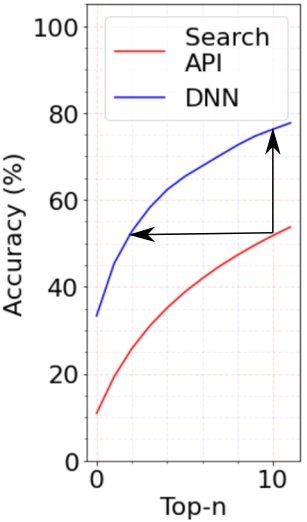
Overall, the DNN model performed well and reduced the median position of the correct result from 10 (in the Search API) down to 2, as shown in the following graphs. By making it easy to locate the correct item, this item-matching model and pipeline has the potential to reduce the time required for claims processing by a factor of 5 or by 500%.
{kind=link}
{kind=link}
Customer and business impact
With the technical exposition of our ML solution in hand, we’re now fully understand the benefits that our tool will provide to Xactware’s customers. After implementing the models for use in real-time inference, we simulate the policyholder’s journey of filling out a digital insurance claim when assisted with instantaneous predictions. The outcome of indicates that the models trained by the ML Solutions Lab can automatically match 75% of items entered into the form, whereas the existing system matches at 25%. And in 90% of cases, the ML model provided the correct match in its top three predictions.
With the current solution, it took 4 minutes to manually find the correct CatSel for 20 items. With the ML models developed by the ML Solutions Lab, the Verisk team anticipates this taking no more than 1 minute to spot check and fix six items, since all six had the correct description in at least the top three results. With auto-approval of high-confidence items from the model, along with spot-checking less confident predictions, they expect an increase in the accuracy and speed of categorizing items by 300%.
The benefit to users of Xactware software is that they experience a faster, simpler, and more accurate platform when carrying out their work. Furthermore, customers experience shorter wait times between their claims filing and item replacement or reimbursement.
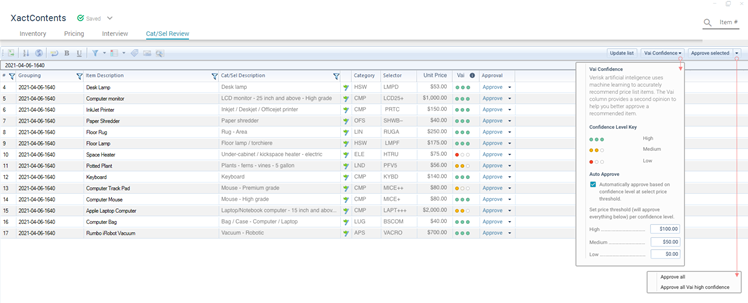
In the following figure, we present an early rendition of the software UX that can be presented to insurance adjustors. As the user enters the item description, the category, selector, and price fields are automatically filled using of the models described earlier. Along with the predictions is a confidence rating to aid in a rapid manual review.
{kind=link}
Summary
In a constant effort to improve workflows throughout the insurance industry, Xactware is excited to integrate additional ML models throughout their organization in a way that improves efficiency, reduces cost, and saves time. End users benefit the most. In this post, we discussed such an endeavor that incorporates NLP through a multi-class classifier built on text features and a multimodal branched deep neural network acting as a ranker for refining item matches. We expect a 75% reduction in claims processing time through this ML-assisted claims processing compared to manual item matching.
As Xactware continues to invest in ML and explores additional opportunities for efficiency gains, we can look with certainty for future innovations in the insurance space.
Xactware Solutions, a Verisk Analytics company (NASDAQ:VRSK), provides computer software solutions for professionals for the management of personal property. Xactware supports nearly every facet of claims management for the property insurance and restoration industries, including structural and personal property estimation, claims collaboration, analytics and reporting tools for underwriting and claims, contents replacement, and weather analytics. Today, 22 of the top 25 property insurance companies in the US and all of the top 10 Canadian insurers use Xactware property insurance claims tools.
If you would like help accelerating your use of ML in your products and processes, contact the Amazon ML Solutions Lab program.
About the Authors
Aaron Brunko is Xactware’s Senior Vice President of Claims Product at Xactware. Aaron joined Xactware in 2001 and since has held many leadership roles in both service and product development/delivery. Aaron holds a bachelor’s degree in business management from Western Governors University and an MBA from the University of Utah.
{kind=link}
Hussain Karimi is a data scientist at the Machine Learning Solutions Lab where he works with customers across various verticals to initiate and build automated, algorithmic models that generate business value.
{kind=link}
Emmanuel Salawu is a Senior Applied Scientist with the Amazon Machine Learning Solutions Lab. He works with AWS’s customers building AI/ML solutions for their high-priority business needs.
{kind=link}
Daniel Horowitz is an Applied AI Science Manager. He leads a team of scientists on the Amazon ML Solutions Lab working to solve customer problems and drive cloud adoption with ML.
{kind=link}
Shane Rai is a Sr. ML Strategist at the Amazon Machine Learning Solutions Lab. He works with customers across a diverse spectrum of industries to solve their most pressing and innovative business needs using AWS’s breadth of cloud-based AI/ML services.
{kind=link}
Read MoreAWS Machine Learning Blog