

{kind=link}
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines enterprise search for your websites and applications so your employees and customers can easily find the content they’re looking for, even when it’s scattered across multiple locations and content repositories within your organization.
Amazon Kendra FAQs allow users to upload frequently asked questions with their corresponding answers. This helps to consistently answer common queries among end-users. As of this writing, when you want to update FAQs, you must delete the FAQ and create it again. In this post, we present a simpler, faster approach for updating your Amazon Kendra FAQs (with versioning enabled). Our method eliminates the manual steps of creating and deleting FAQs when you update their contents.
Overview of solution
We use a fully deployable AWS CloudFormation template to create an Amazon Simple Storage Service (Amazon S3) bucket, which becomes the source to store your Amazon Kendra FAQs. Each index-based FAQ is maintained in the folder with a prefix relating to the Amazon Kendra index.
This solution uses an AWS Lambda function that gets triggered by an Amazon S3 event notification. When you upload an FAQ to the S3 folder mapped to a specific Amazon Kendra index, it creates a new version of the FAQ for your index. Older versions of FAQs are deleted only after the new FAQ index version is created, achieving near-zero downtime of index searching.
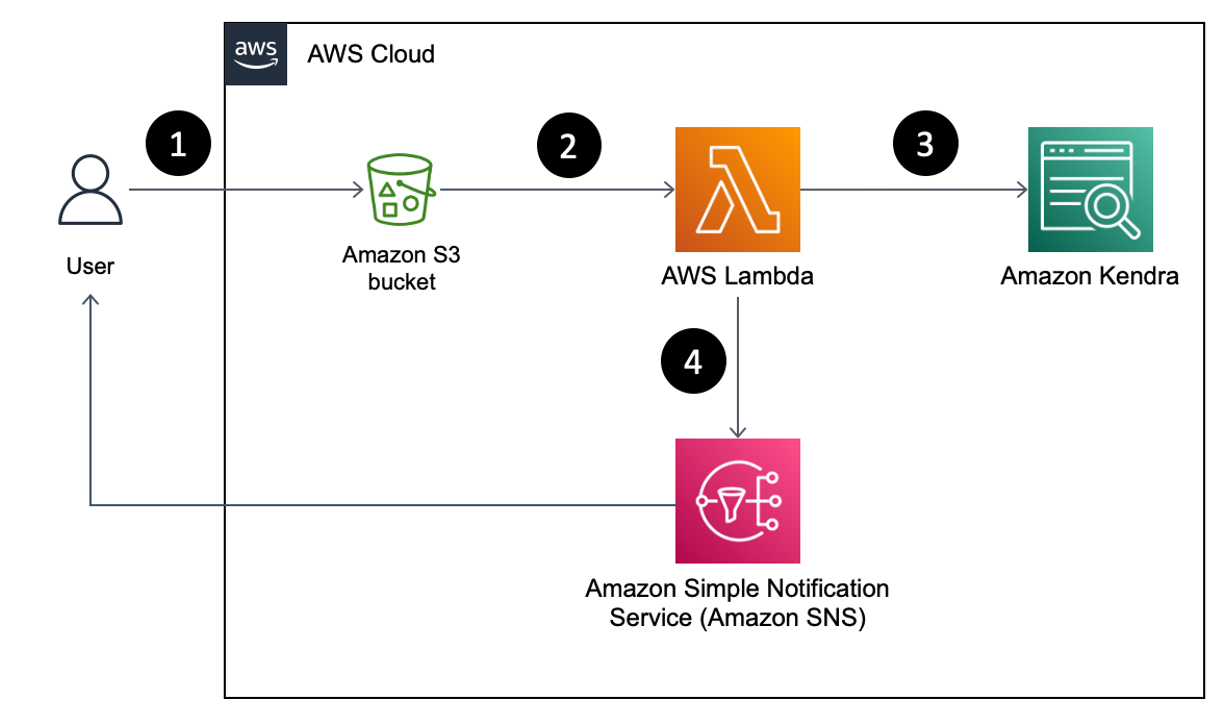
The following figure shows the workflow of how our method creates and deletes a new version of an Amazon Kendra FAQ.
{kind=link}
The workflow steps are as follows:
The user uploads the Amazon Kendra FAQ document to the S3 bucket mapped to the Amazon Kendra index.
The Amazon S3 PutObject event triggers the Lambda function, which reads the event details.
The Lambda function creates a new version of the FAQ for the target index for each uploaded document and deletes the older versions of the FAQ.
The Lambda function then publishes a message to Amazon Simple Notification Service (Amazon SNS), which sends an email to the user notifying them that the FAQ has been successfully updated.
Prerequisites
Before you begin the walkthrough, you need an AWS account (if you don’t have one, you can sign up for one). You also need to create the files containing the sample FAQs:
basic.csv – The following code is the sample FAQ CSV template:
demo.json – The following code is the sample FAQ JSON template:
header_demo.csv – The following code is the sample FAQ CSV template with header:
Deploy the solution
The CloudFormation templates that create the resources used by this solution can found in the GitHub repository. Follow the instructions in the repository to deploy the solution. AWS CloudFormation creates the following resources in your account:
An S3 bucket that will be the source for the Amazon Kendra FAQ.
An Amazon Kendra index.
An AWS Identity and Access Management (IAM) role for the Amazon Kendra FAQ to read (GetObject) from the S3 bucket.
A Lambda function that is configured to get triggered by an Amazon S3 event. The function is created outside of an Amazon VPC.
Note that resource creation can take approximately 30 minutes.
After you run the deployment, you’ll receive an email prompting you to confirm the subscription at the approver email address. Choose Confirm subscription.
{kind=link}
You’re redirected to a page confirming your subscription.
{kind=link}
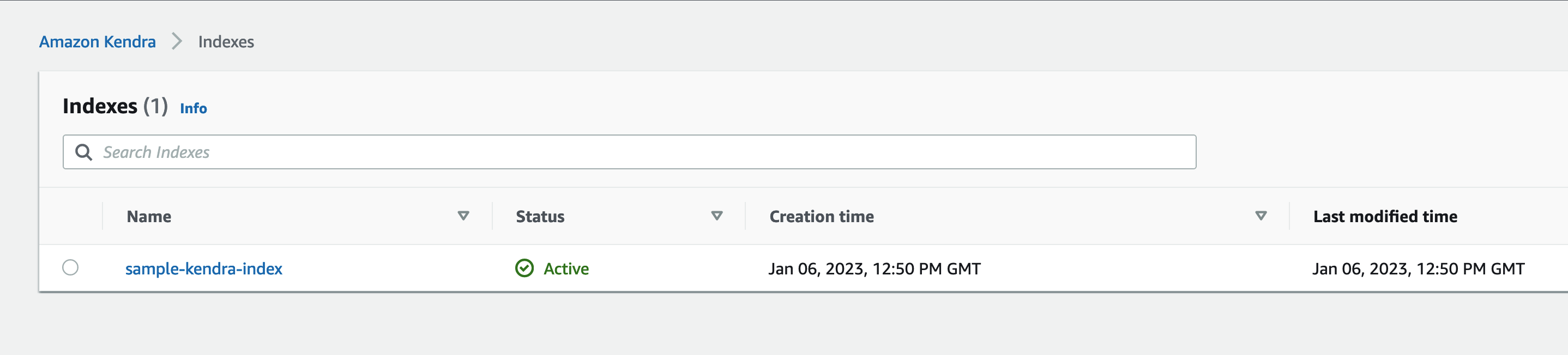
Verify that the Amazon Kendra index is listed on the Amazon Kendra console. In this post, we named the Amazon Kendra index sample-kendra-index.
{kind=link}
Upload a sample FAQ document to Amazon S3
In the previous step, you successfully deployed the CloudFormation stack. We use the output of the stack in the following steps:
On the Outputs tab of the CloudFormation stack, note the values for S3Bucket (kendra-faq-<random-stack-id>) and KendraIndex.
On the Amazon S3 console, navigate to the S3 bucket created from the CloudFormation stack.
Choose Create folder and create a folder called faq-<index-id>. For index-id, use the value you noted for the CloudFormation parameter KendraIndex. After the folder is created, this becomes the prefix for the sample-kendra-index FAQ.
Upload the demo.json FAQ document to that folder.
{kind=link}
{kind=link}
{kind=link}
Verify that the index FAQ is created
To confirm that the index FAQ is created, complete the following steps:
On the Amazon Kendra console, navigate to the index sample_kendra_index, which was created as part of the deployment.
Navigate to the FAQs page for this index to check if an FAQ is listed.
The index has the naming convention <file-name>-faq-<Date-Time>.
{kind=link}
When the FAQ is successfully created, you will receive another email informing you about it. You may upload new versions of the FAQ after you have received this email.
{kind=link}
Note that the automation identifies the file format that it must use while creating the FAQ by reading the uploaded file extension and as an exception case by the prefix of header_ for the CSV document with a header. The target Amazon Kendra index is identified by the S3 bucket folder name, which has the index ID as the suffix; for example, faq-1f01abb8-341c-4921-ad16-139ee517a845.
Upload additional FAQ documents
Amazon Kendra FAQ supports three types of file format: CSV, CSV_WITH_HEADER, and JSON. Make sure that when you upload a CSV file with the header, the file name should have a prefix with header_ (this is only when using the CSV file format with a header in its contents). To upload your FAQ documents, complete the following steps:
Upload the header_demo.csv file to the same folder.
Verify that the FAQ is created on the Amazon Kendra console.
{kind=link}
{kind=link}
FAQ creation is case-sensitive to the file format of the FAQ document that you upload. For example, if you upload demo.json and demo.JSON, both are treated as unique objects in Amazon S3. Therefore, this action creates two FAQs, such as demo-json-faq-22-09-2022-20-09-11 and demo-JSON-faq-22-09-2022-20-09-11.
Upload demo.JSON.
Verify that the FAQ for demo.JSON is created on the Amazon Kendra console.
{kind=link}
{kind=link}
Create a new version of the index FAQ
Now the solution is self-sufficient and able to work independently whenever you upload a new version of the FAQ document in Amazon S3.
To test this, upload a new updated version of your demo.json FAQ document to the faq-<index-id> folder. When you navigate to the FAQ for the index, there will be an FAQ named <file-name>-faq-<Date-Time>.
This solution creates a new version of the FAQ for the new version of the FAQ document that was uploaded in Amazon S3. When the FAQ is active, it deletes the older version of the FAQ for the same document.
{kind=link}
Create an FAQ with a description
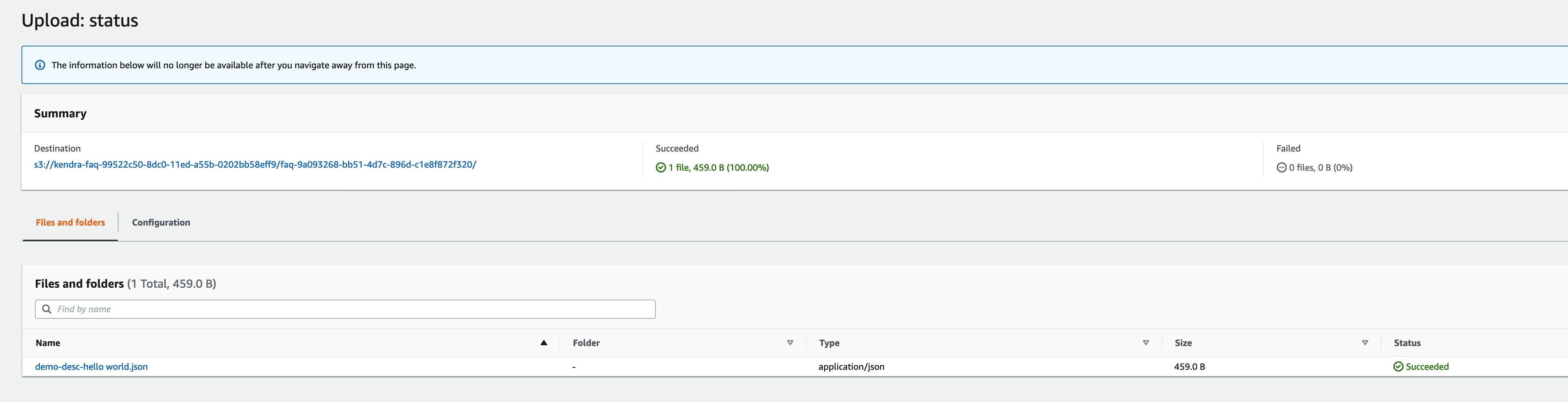
This solution also supports creating an FAQ with a description when files are named in a specific manner: <document_name>-desc-<your faq description>.fileformat[json|csv]. For example, demo-desc-hello world.json. Upload this FAQ document to the faq-<index-id> folder.
{kind=link}
After you upload the document, the FAQ will be created and it will have the description as mentioned in the file name.
{kind=link}
You should only use -desc- when you must add a description to an FAQ. If you upload a file with the same document_name prefix, it will delete the old FAQ created from the document_name.fileformat FAQ document and create a new FAQ with the description.
Clean up
To clean up, perform the following actions:
Empty the S3 bucket that was created by the CloudFormation stack to store the FAQ documents. For instructions, refer to Emptying a bucket.
Delete the CloudFormation stack. For instructions, refer to Deleting a stack on the AWS CloudFormation console.
Conclusion
In this post, we introduced an automated way to manage your Amazon Kendra FAQs. After implementing this solution, you should be able to create and delete FAQs just by uploading them to an S3 bucket. This way, you save time by avoiding repetitive manual changes and troubleshooting inconsistent issues that are caused by unexpected operational incidents. You can also audit Amazon Kendra FAQs across your organization with confidence.
Do you have feedback about this post? Submit your comments in the comments section. You can also post questions on the AWS re:Post forum.
About the Author
Debojit is a DevOps consultant who specializes in helping customers deliver secure and reliable solutions using AWS services. He concentrates on infrastructure development and building serverless solutions with AWS and DevOps. Apart from work, Debojit enjoys watching movies and spending time with his family.
{kind=link}
Glenn is a Cloud Architect at AWS. He utilizes technology to help customers deliver on their desired outcomes in their cloud adoption journey. His current focus is DevOps and developing open-source software.
{kind=link}
Shalabh is a Senior Consultant based in London. His main focus is helping companies deliver secure, reliable, and fast solutions using AWS services. He gets very excited about customers innovating with AWS and DevOps. Outside of work, Shalabh is a cricket fan and a passionate singer.
{kind=link}
Read MoreAWS Machine Learning Blog