

{kind=link}
In this series of posts (Part 1, Part 2, Part 3 and Part 4), we compare and contrast the disaster recovery (DR) solutions available for Microsoft SQL Server on Amazon Elastic Compute Cloud (Amazon EC2) and help you understand the nature of these trade-offs, and the cost and complexity of implementing DR for SQL Server workloads on AWS. This post introduces additional methods for implementing DR for SQL Server on AWS: SQL Server Always on Failover Cluster Instances (FCIs); Always On availability groups; distributed availability groups; and common combinations of some technologies.
SQL Server Always On failover cluster instance
A SQL Server Always On failover cluster instance (FCI) is a single instance of SQL Server that is installed across Windows Server failover clustering (WSFC) nodes and, possibly, across multiple subnets. On the network, an FCI appears to be an instance of SQL Server running on a single computer, but the FCI provides failover from one WSFC node to another if the current node becomes unavailable. A typical installation of a SQL Always On failover cluster consists of two nodes in the same data center with a shared storage for user and system databases. In such a setup, the solution is designed to provide high availability (HA) to the SQL instance.
In AWS, the recommended architecture is to use multiple Availability Zones for greater high availability for all workloads. These Availability Zones have high bandwidth and low latency links between each other. This means that you can run the equivalent two-node SQL failover cluster that you had running in the single primary corporate data center, but with one node in one Availability Zone, and the other in a different Availability Zone in the same Region. The high-performance inter-Availability Zone links mean that you can also run your cluster in across Availability Zones without performance suffering, and therefore you can achieve HA and DR at the same time for your SQL setup.
In a multi-subnet SQL failover cluster, you need storage that can span across multiple data centers. This can be achieved by using Amazon FSx for Windows File Server. FSx for Windows File Server provides fully managed, highly reliable, and scalable file storage that is accessible over Service Message Block (SMB) protocol. Amazon FSx shares can be deployed across Availability Zones with the Multi-AZ option and optimized to provide shared storage for SQL Server databases by supporting continuously available (CA) file shares. This solution not only provides redundancy for SQL instances, it also increases SQL storage durability by storing your database file in multiple Availability Zones.
RPO and RTO
Recovery Time Objective (RTO) for a SQL failover cluster setup on Amazon EC2 is the time that it takes you to fail over to the other node. Typically, this an automatic failover, and the duration of the failover greatly depends on the amount of data modified by active transactions at the time of the failover.
A SQL failover cluster requires that all databases be placed on shared storage. So Recovery Point Objective (RPO) in a SQL failover cluster setup depends on the storage solution and is theoretically zero.
Best practices
You can deploy SQL Server with an SMB file share as the storage option for active data files. Amazon FSx is optimized to provide shared storage for SQL Server databases by supporting CA file shares. These file shares are designed for applications like SQL Server that require uninterrupted access to shared file data. Although you can create CA shares on Single-AZ 2 file systems, you must use CA shares on Multi-AZ file systems for all SQL Server deployments.
Windows Server failover cluster deployments commonly deploy an SMB file share witness to maintain quorum of the cluster’s resources. Witness file shares require only a small amount of storage for quorum information. You can also use Amazon FSx file systems as an SMB file share witness for Windows Server failover cluster deployments.
Solution overview
The following diagram illustrates the architecture for SQL Server Always On failover cluster instances on AWS.
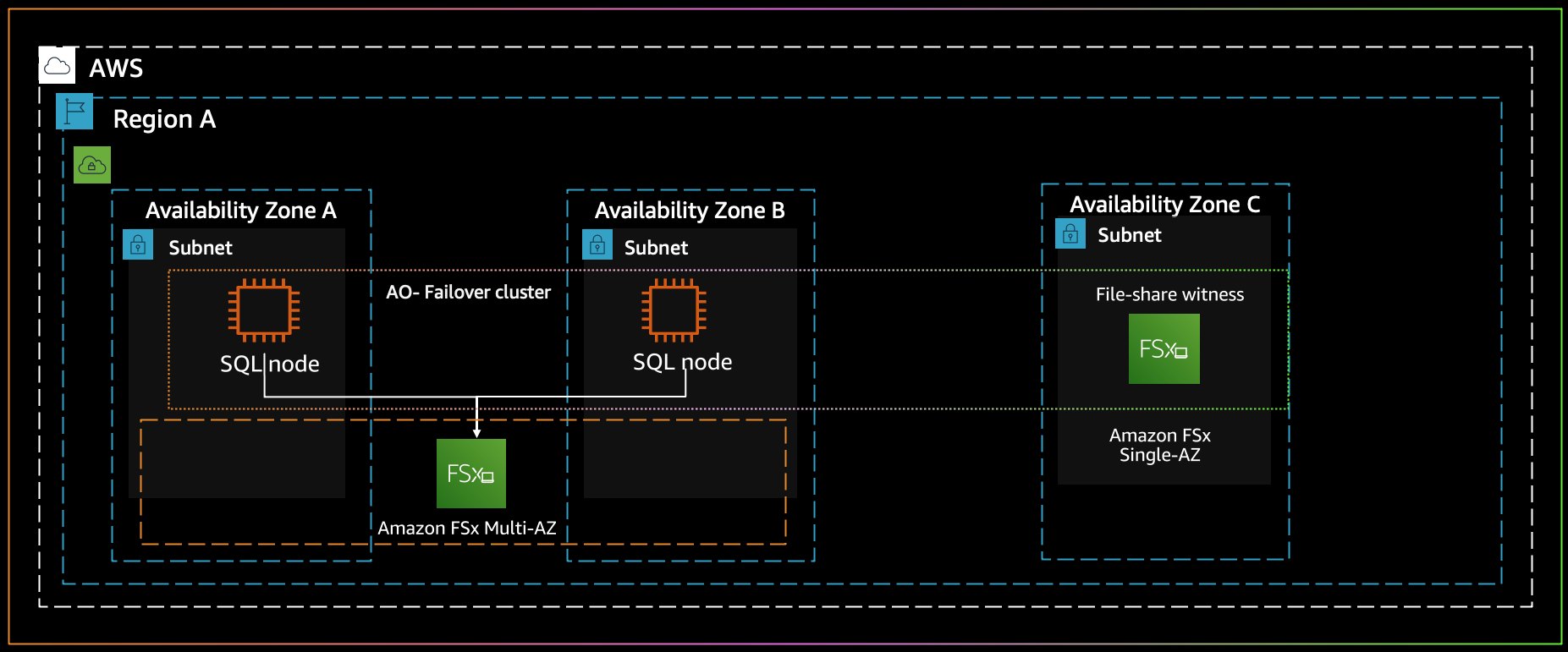{kind=link}
In this scenario, if you’re already using a SQL Server failover cluster on AWS, SQL Server FCI relies on shared storage being accessible from all nodes participating in FCI. FSx for Windows File Server is a fully managed service providing shared storage that automatically replicates the data synchronously across two Availability Zones; provides high availability with automatic failure detection, failover, and failback; and fully supports the SMB CA feature. This enables you to simplify your SQL Server Always On deployments and use Amazon FSx as storage tier for MSSQL FCI. For information, see Simplify your Microsoft SQL Server high availability deployments using Amazon FSx for Windows File Server.
If you’re running a combination of FCI and Always On Availability Groups (AG) on premises to achieve both high availability and disaster recovery, you have the option to move your deployment to a SQL FCI deployment on AWS. This eliminates separate HA and DR solutions, further reducing costs as well as simplifying deployment complexities.
Failover and failback
A SQL failover cluster supports automatic failover of the SQL instance in case of disaster. It also supports automatic failback of the SQL instance after recovery from the disruption.
Benefits
This solution has the following benefits:
Supported in SQL Server Standard edition and Enterprise edition.
Protection at the SQL Server instance level for all user and system databases.
With Amazon FSx as shared storage, you can use fully managed and fully replicated Multi-AZ storage.
Failover and failback operations are automatic and simple.
Relative cost
The SQL failover cluster solution requires SQL Server Standard edition or Enterprise edition to run. The technology also depends on Microsoft Active Directory to set up and operate. Compared to other HA and DR technologies, SQL failover clustering also requires a shared storage for system and user databases, which also increases complexity and TCO of the solution.
SQL Always On availability groups
SQL Always On availability groups (AGs) work by sending a stream of log records from primary to secondary servers. All data modification on a database in an AG is done on the primary replica. Clients can access and read data from the secondary replicas when it’s enabled in the AG configuration. This technology can work in either synchronous or asynchronous modes. The synchronous commit mode guarantees no data loss for committed transactions, but in this mode network latency in unacceptable. You can avoid this by using an asynchronous commit. In this mode, the primary server sends log records to the secondary server and doesn’t wait for the acknowledgement before committing the transactions. Although it’s possible to use synchronous commit mode in a DR setup, it’s not practical due to the bandwidth limitations. That is why the recommended approach for DR is using asynchronous commit mode.
SQL Server Always On availability groups is an advanced, enterprise-level feature to provide high availability and disaster recovery solutions. This feature is available in SQL Server 2012 and later versions. You can also use an Always On availability group to migrate your on-premises SQL Server databases to Amazon EC2 on AWS. This approach enables you to migrate your databases either with no downtime or with minimal downtime.
If you have an existing on-premises deployment of SQL Server Always On availability groups, your primary replica and secondary replica are synchronously replicating data within the availability group. To migrate your database to AWS Cloud, you can extend your Windows Server Failover Clustering (WSFC) cluster to the cloud. This can be temporary and just for migration purposes. You then create a secondary replica in the AWS Cloud and use asynchronous replication. After the secondary replica is synchronized with the primary on-premises database, you can perform a manual failover whenever you’re ready for cutover.
RPO and RTO
In an on-premises data center to AWS failover scenario, RTO is to time to fail over to the AG secondary replica running on Amazon EC2. With asynchronous commit mode, you have to force the failover, thereby accepting the risk of data loss. RTO is generally considered as minutes. In this mode, the primary replica sends the transaction log records to the secondary replica, but it doesn’t wait for the acknowledgement for transaction commit. This process is faster but RPO value can go up to minutes.
Best practices
Consider the following best practices:
For a given availability group, all the availability replicas should run on the same EC2 instance family and size that can handle identical workloads.
Make sure you have a transaction log backup strategy in place and actively monitor these backup jobs for all databases participating in the AG to prevent transaction log growth.
For best performance, use a dedicated network adapter (network interface card) for AG members.
Redundant connectivity between AG replicas is crucial. AGs rely on transaction logs. If the secondary replica is unreachable, the truncation of transaction logs on the primary replica is deferred. This increases the transaction log size on the primary replica until the secondary replica is available.
Solution overview
The following diagram illustrates the architecture of using SQL Always On availability groups.
{kind=link}
In this scenario, if you’re already using SQL Server Always On AGs on premises and your connectivity level is sufficient to move your data across, you may extend your on-premises availability group to AWS to transfer data and keep your on-premises and cloud databases in sync until the moment you cut over to the cloud.
Failover and failback
Typical AG replicas are configured for asynchronous commit mode for DR. In the case of a disaster, the failover is manually initiated and referred to as forced failover.
Forcing failover of an availability group (with possible data loss) is a disaster recovery method that allows you to use a secondary replica as a warm standby server. Because forcing failover risks possible data loss, it should be used cautiously and sparingly. We recommend forcing failover only if you must restore service to your availability databases immediately and are willing to risk losing data.
The failback operation is the same as failover operation, with one exception. After recovering the primary site, you can plan and implement the failback without data loss. To gracefully fail back the AG replicas, change the mode to synchronous commit, then you can manually start a failover from the DR site to primary site (failback). After a successful failback, you can switch the AG replicas to asynchronous commit for DR.
Benefits
This solution has the following benefits:
A single endpoint for applications to connect through AG listener, which simplifies failover and failback.
Secondary replicas can be used for read scaling.
No shared storage is required.
Relatively easy failover and failback.
Basic availability groups supported in Standard edition. A basic availability group supports a failover environment for a single database.
Relative cost
Fully featured AG requires SQL Enterprise edition. Setup, configuration, and operation of failover clustering and AGs increase the TCO and complexity. In many cases, to use the benefits of SQL passive node failover, additional vendor software costs incur.
Distributed Always On AG
Distributed availability groups are an extension of availability groups that allow for data to be synchronized between two separate availability groups. Distributed AGs can allow data synchronization between Windows-based and Linux-based AGs, and allows the number of readable secondary replicas to be extended beyond single AG limits. In a distributed AG setup, each individual AG is a separate Windows failover cluster. This technology also allows cross-site replication without the complexity of configuring and operating a stretched cluster.
RPO and RTO
The relation between two AGs in a distributed AG setup is typically asynchronous, and the failover is always manually initiated. Therefore, the RPO and RTO values are considered the same as you would expect from a single asynchronous AG setup.
Solution overview
The following diagram illustrates the architecture of a hybrid distributed AG solution.
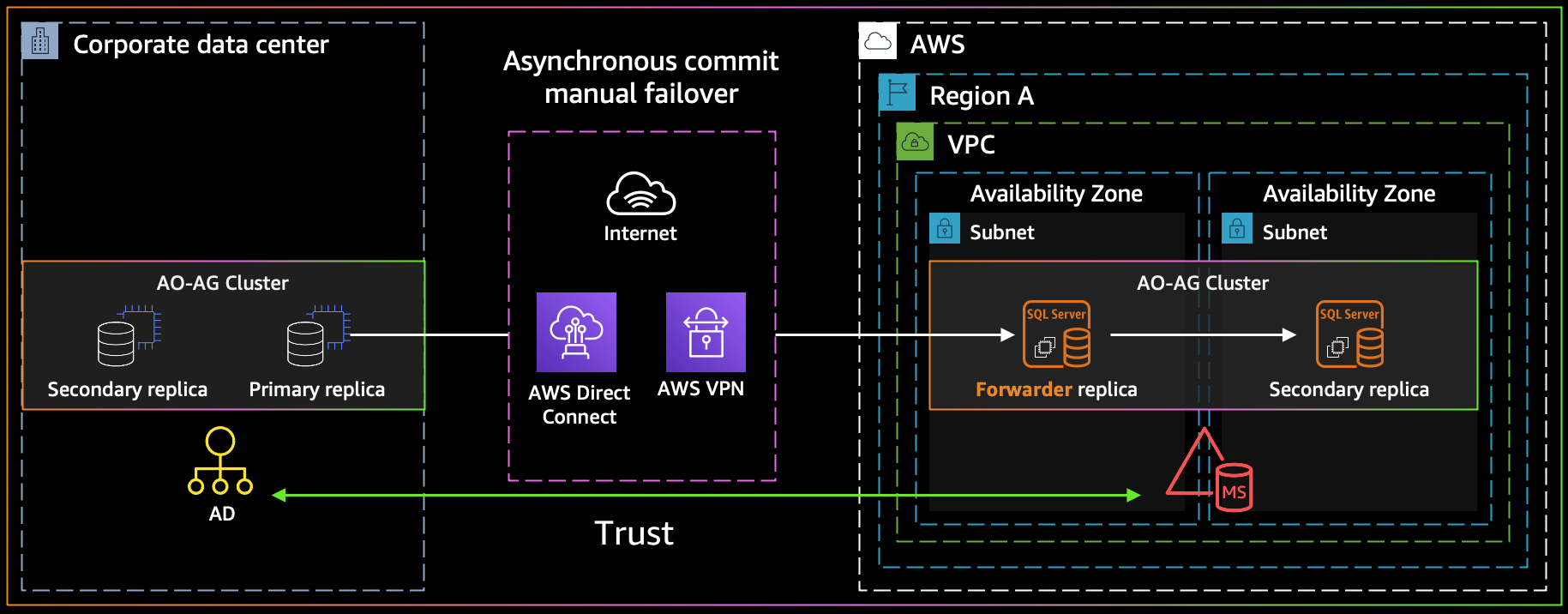{kind=link}
In this scenario, you have a SQL Server AG cluster in your primary site. For DR implementation on AWS, you may set up a separate AG on AWS and establish a distributed AG with asynchronous commit relation between these two AGs. If an Active Directory domain is required, this can be either an extension of current AD domain on premises or can be another AD domain.
Benefits
This solution has the following benefits:
Each AG in the distributed AG can be part of a separate Active Directory domain or no Active Directory at all
Each AG in the distributed AG is a separate Windows Server failover cluster, so you don’t require geographical stretched failover clusters for a multi-site DR scenario
You can use different versions of SQL Server instances in the distributed AG
Relative cost
The distributed AG feature is available for SQL Server versions starting from 2016 and up. This feature is offered in Enterprise edition. You can’t configure a listener for the distributed availability group. Therefore, your application can’t redirect connections to another cluster automatically. It requires an explicit configuration in the application connection string, which increases the administrative overhead.
Combining technologies: SQL failover cluster combined with log shipping
You can also run SQL Server workloads in a hybrid environment that includes AWS. For example, you might already be running SQL Server in your on-premises or co-located data center but want to use the AWS Cloud to enhance your architecture to provide a high availability or disaster recovery solution. You can also use hybrid solutions to store long-term SQL Server backups on AWS, roll back your migration in case of issues, or run a secondary replica using SQL Server Always On availability groups in the AWS Cloud. SQL Server has several replication technologies that offer high availability and disaster recovery solutions.
To meet your business objectives and requirements, you may need to combine multiple DR and HA technologies to create a reliable and flexible solution. A classic example is combining SQL Failover Cluster instances (FCIs) with log shipping. It’s a common practice to first use an FCI to achieve high availability at the primary site and then use log shipping to perform DR and offload reporting for the SQL Server database. The reason for combining these technologies includes the following possibilities:
You are unable to maintain the WSFC configurations between different sites.
You are unable to use the target server in the DR site in the WSFC configuration because it’s already part of another WSFC configuration.
In log shipping, we can have a definite delay on the secondary database. You get the flexibility to pick a specific point in time during the recovery with logshipping.
RPO and RTO
The default RPO is 15 minutes, dictated by default log shipping interval. You can raise it up to a minute, if inter-node network link has enough bandwidth. RTO depends on exactly when the database is recovered.
Solution overview
In this scenario, the SQL failover cluster at an on-premises data center. The transaction logs of the database are then shipped to a standby SQL Server running in the DR site on AWS. The following diagram illustrates this architecture.
{kind=link}
Failover and failback
The failover process is similar to that in the classic log shipping setup. Manual intervention is required to bring the database in the AWS site. Applications have to be directed after failover.
To fail back, you need to reconfigure the log shipping between the DR site and primary site. Redirection of the application that uses this database after failback also needs to be configured manually.
Benefits
This solution has the following benefits:
Flexibility to pick a previous point in time during recovery.
Primary and secondary databases can be part of different WSFC configurations. Disruptions in secondary infrastructure does not impact primary.
Relative cost
Log shipping requires SQL Server Web edition and up. From a costs perspective, the same statements apply as with standard log shipping.
Summary
In this post, we discussed SQL failover clustering, SQL Always On availability groups, distributed availability groups, and combining multiple DR technologies topics to implement DR on AWS. In our next post, we talk through using AWS Database Migration Service (AWS DMS) and CloudEndure Disaster Recovery for DR use cases on AWS. We also wrap up all the SQL Server DR technologies we discussed in this series.
About the Author
Ganapathi Varma Chekuri is a Database Specialist Solutions Architect at AWS. Ganapathi works with AWS customers providing technical assistance and designing customer solutions on database projects, helping them to migrate and modernize their existing databases to AWS cloud.
{kind=link}
Baris Furtinalar is a Senior Solutions Architect who is part of specialists in Microsoft architectures team at AWS. He is passionate about cloud computing and he believes this shift to the cloud helps companies transform their businesses, gain agility, and improve operational responsiveness. He comes from a diverse background including SQL database administration, virtualization and system security. He designed, implemented and supported Windows/SQL server deployments since 2000.
{kind=link}
Read MoreAWS Database Blog