

{kind=link}
Today, we’re incredibly excited to announce the general availability of Vertex Pipelines.
One of the best ways to scale your machine learning (ML) workflows is to run them as a pipeline, where each pipeline step is a distinct piece of your ML process. Pipelines are a great tool for productionizing, sharing, and reliably reproducing ML workflows across your organization. They are also the key to MLOps – with Pipelines you can build systems to automatically retrain and deploy models. In this post, we’ll show what you can do with Vertex Pipelines, and we’ll end by sharing a sample pipeline to help you get started.
Vertex Pipelines in a nutshell
Let’s briefly discuss what an ML pipeline does. A machine learning pipeline is an ML workflow encapsulated as a series of steps, also called components. Each step in a pipeline is a container, and the output of each step can be an input to the next step. This presents two challenges:
For this to work, you need a way to convert individual pipeline steps to containers
This will require setting up infrastructure to run your pipeline at scale
To address the first challenge, there are some great open source libraries that handle converting pipeline steps to containers and managing the flow of input and output artifacts throughout your pipeline, allowing you to focus on building out the functionality of each pipeline step. Vertex Pipelines supports two popular open source libraries – Kubeflow Pipelines (KFP) and TensorFlow Extended (TFX). This means you can define your pipeline using one of these libraries and run it on Vertex Pipelines.
Second, Vertex Pipelines is entirely serverless. When you upload and run your KFP or TFX pipelines, Vertex AI will handle provisioning and scaling the infrastructure to run your pipeline. This means you’ll only pay for the resources used while your pipeline runs; and your data scientists get to focus on ML without worrying about infrastructure.
Vertex Pipelines integrates with other tools in Vertex AI and Google Cloud: you can import data from BigQuery, train models with Vertex AI, store pipeline artifacts in Cloud Storage, get model evaluation metrics, and deploy models to Vertex AI endpoints, all within your Vertex Pipeline steps.
To make this easy, we’ve created a library of pre-built components for Vertex Pipelines. These pre-built components help simplify the process of using other parts of Vertex AI in your pipeline steps, like creating a dataset or training an AutoML model. To use them, import the pre-built component library and use components from the library directly in your pipeline definition.
As an example, below is a pipeline that creates a Vertex AI dataset pointing to data in BigQuery, trains an AutoML model, and deploys the trained model to an endpoint if its accuracy is above a certain threshold:
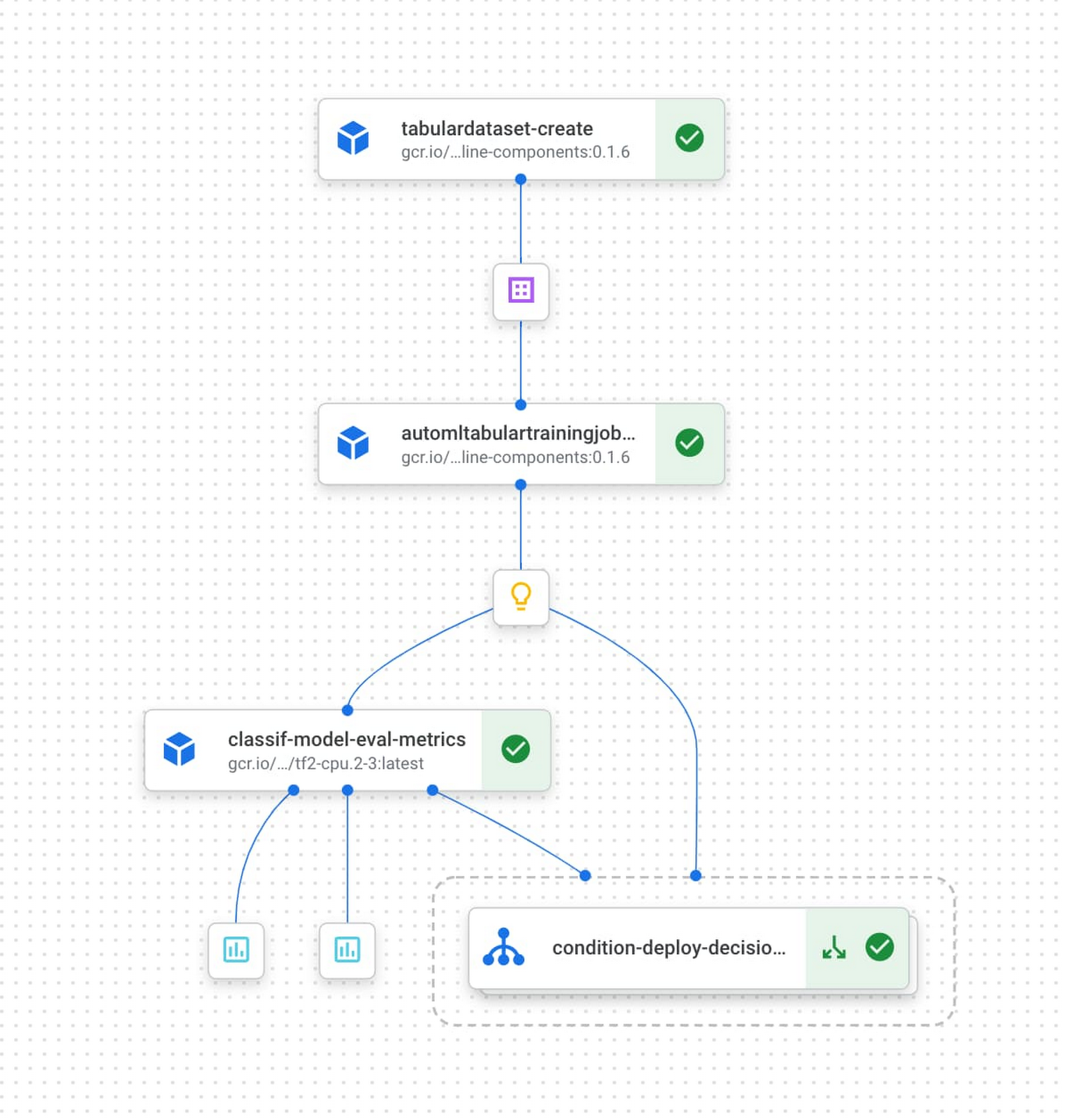{kind=link}
ML Metadata & Vertex Pipelines
With output generated from each step of a pipeline execution, it’s important to have a mechanism for tracking the artifacts and metrics created across pipeline runs. This becomes especially useful when you have multiple people on your team involved in developing and running a pipeline, or are managing multiple pipelines for different ML tasks. To help with this, Vertex Pipelines integrates directly with Vertex ML Metadata for automatic artifact, lineage, and metric tracking.
You can inspect pipeline metadata in the Vertex AI console, and through the Vertex AI SDK. To see metadata and artifacts in the console, start by clicking on the “Expand artifacts” slider when looking at your pipeline graph. You can then click on individual artifacts to view details and see where each artifact is stored:
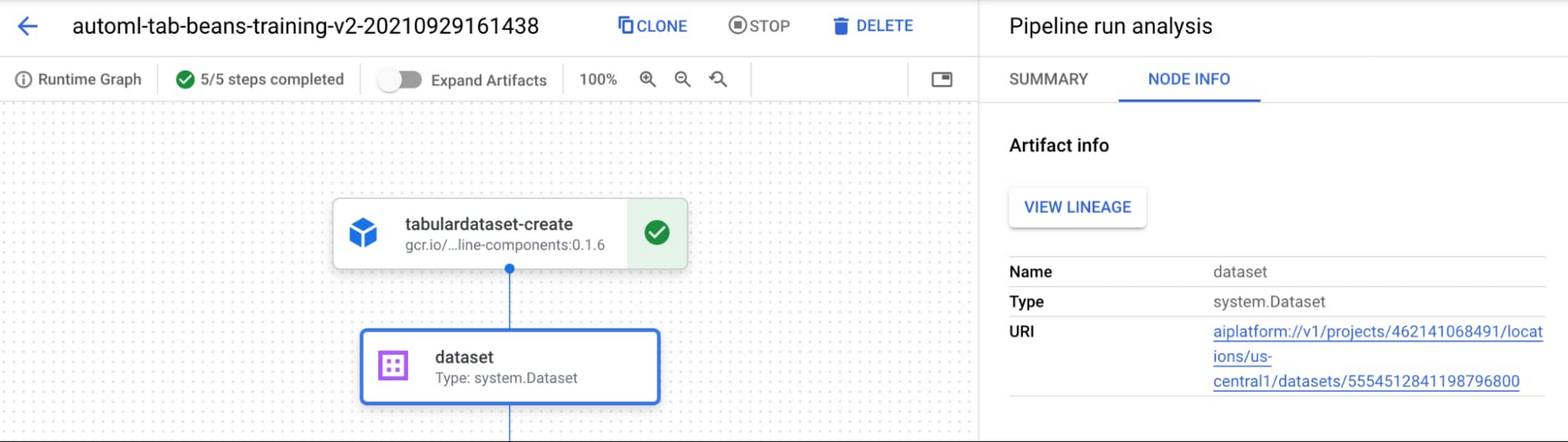{kind=link}
When looking at output artifacts, it’s also helpful to understand an individual artifact in the larger context of your pipeline. To do this, Vertex Pipelines offers lineage tracking. When looking at an artifact in the console, click on the “View lineage” button. As an example, for the endpoint below, we can see the model that is deployed to the endpoint, and the dataset used to train that model. We can also see the pipeline steps that generated each artifact in this graph:
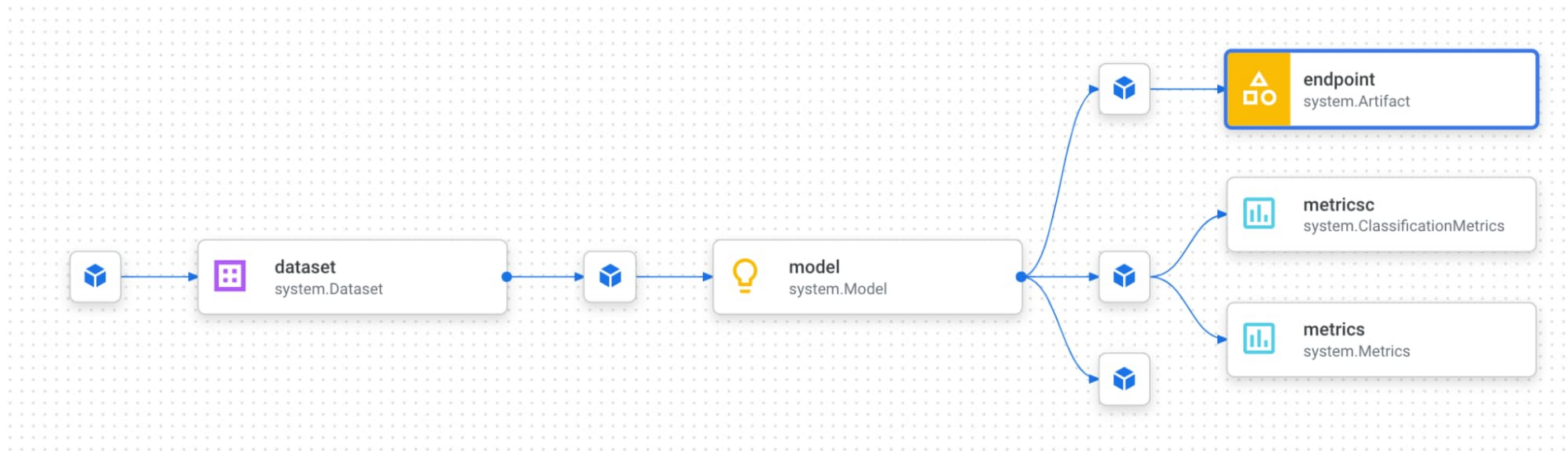{kind=link}
There are several ways to interact with pipeline metadata programmatically. Using the Vertex ML Metadata API, you can query for any artifacts or executions in your metadata store by their properties or lineage. You can also use the get_pipeline_df method from the Vertex AI SDK to create a Pandas DataFrame with metrics from each of your pipeline runs. There are also SDK methods for getting artifact lineage and filtering artifacts, which you can use to create custom dashboards to track your pipelines.
Building a sample pipeline
To see Vertex Pipelines in action, let’s look at an example built with the Kubeflow Pipelines SDK. You can find the full pipeline code for this example in this codelab, and here we’ll show a few highlights. Our sample pipeline will make use of Google Cloud’s pre-built components, and will do the following:
Create a dataset in Vertex AI
Train a custom model on that dataset
Run a batch prediction on the trained model
To build and run this pipeline, we’ll first import a few Python packages:
We’re using three libraries to build and run this pipeline on Vertex AI:
The Kubeflow Pipelines SDK to build our components and connect them together into a pipeline
The Vertex AI SDK to run our pipeline on Vertex Pipelines
The Google Cloud components library to make use of pre-built components for interacting with various Google Cloud services
Because we’re making use of first party pre-built components, we don’t need to write boilerplate code to perform each of these tasks. Instead, we can pass configuration variables to the components directly in our pipeline definition. You can see the full definition in the codelab, and we’ve shown some highlights below:
This pipeline first creates a dataset in Vertex AI using the TabularDatasetCreateOp component, passing in the BigQuery source table of the dataset. The dataset created will then be passed to our CustomContainerTrainingJobRunOp component and used in our scikit-learn model training job. We’ve passed configuration parameters that point to a container in Container Registry where we’ve deployed our scikit-learn training code. The output of this component is a model in Vertex AI. In the last component of this pipeline, we run a batch prediction job on this model by providing a CSV file with examples we’d like to get predictions on.
When we compile and run this pipeline on Vertex AI, we can inspect the pipeline graph in the console as it runs:
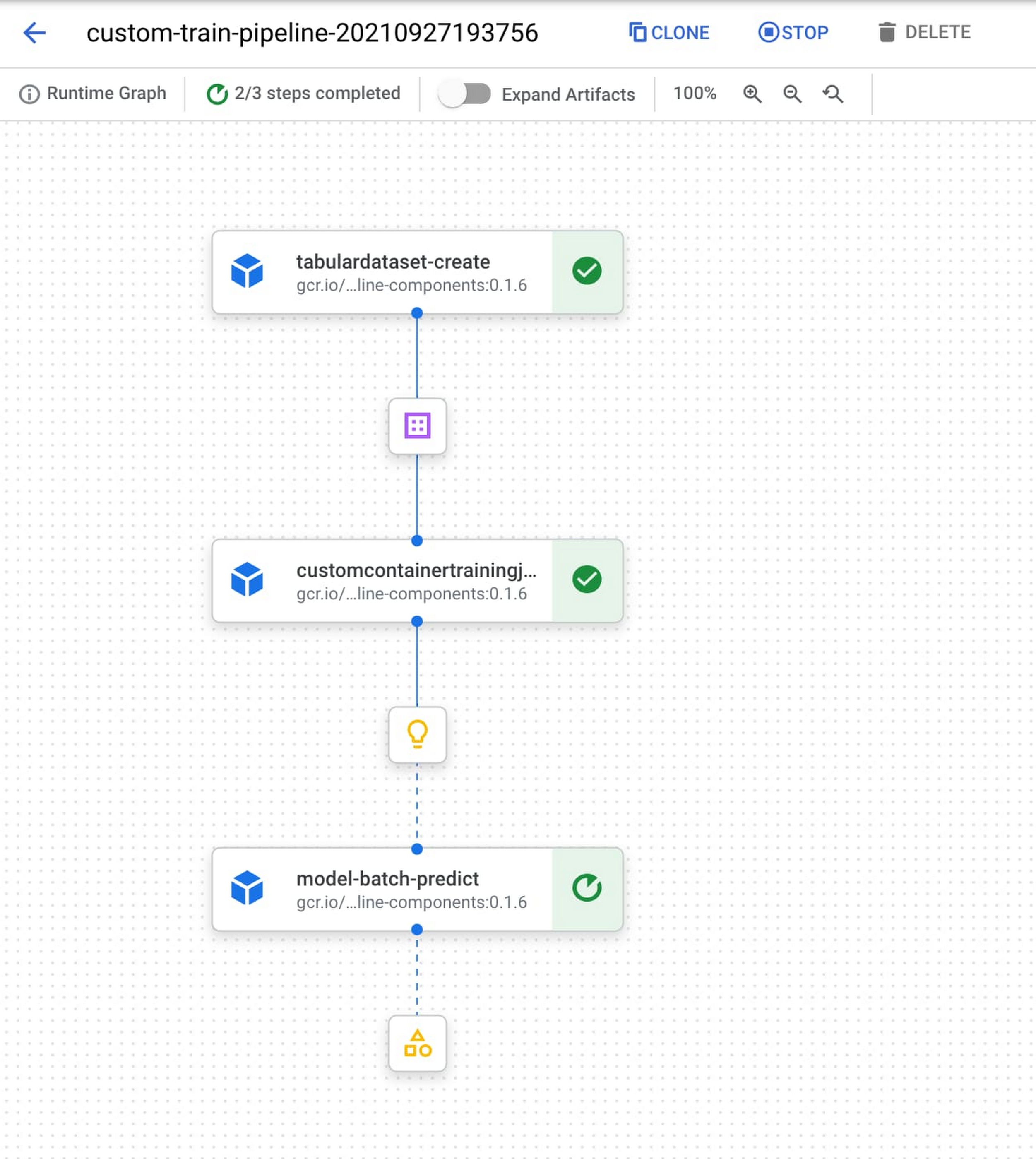{kind=link}
Start building with Vertex Pipelines
Ready to run your own scalable ML pipelines on Vertex AI? Check out the following resources to get started:
Vertex Pipelines documentation
Official sample pipelines on GitHub
Check out this codelab for an introduction to Vertex Pipelines, and this one to understand how Vertex Pipelines works with Vertex ML Metadata.
Cloud BlogRead More