

{kind=link}
Today, we announced that openCypher for Amazon Neptune is available in lab mode. Developers can now use openCypher and Apache TinkerPop Gremlin to build or migrate property graph applications. Neptune’s purpose-built graph engine now supports three open graph query languages: Apache TinkerPop Gremlin, openCypher, and the World Wide Web Consortium’s (W3C) SPARQL 1.1, giving developers the most choice for building graph applications.
We built Neptune because we heard from customers that you needed a way to get value from the relationships in your data. Since launch, we’ve seen customers like Netflix, NBC Universal, Cox Automotive, and the Yahoo Knowledge Graph use the relationships in their data to expand their businesses by building knowledge graphs to link and discover data, identity graphs to better understand customers and devices, fraud graphs to use relationships to detect fraudulent activities, and many other applications.
We worked backwards from customers who asked us for a declarative graph query language for property graphs. With the launch of openCypher in lab mode, Neptune now provides a REST endpoint (link) to run openCypher queries and supports openCypher property graph bulk load formats (link). You can use both the openCypher and Gremlin query languages on the same property graph. Neptune customers who are unfamiliar with graph databases, but who are familiar the declarative style of SQL, have a new choice to compose queries for graph applications. Customers who know openCypher or who have applications that use the Bolt protocol now have a new, fully managed graph database option that supports enterprise features like high availability, low-latency read replicas, and encryption at rest without purchasing expensive commercial licenses.
The concepts of graph databases are not new. “In fact, network databases predate relational ones,” as Werner Vogels points out in his blog post about relationships in data. Yet, today there are far more customers who can benefit from using a graph than who are familiar with graph databases, query languages, or data models. When we talk to customers, we hear that you often don’t care, and, in fact, are impeded by the decisions that you need to make regarding the details of graph implementation, such as graph data models, query languages, and APIs. To give customers the confidence to choose the best option to create their graph applications, we made an explicit decision in Neptune to support both of the two primary graph models that are widely used today: property graphs and the W3C Resource Description Framework (RDF). The addition of openCypher for property graphs in Amazon Neptune gives you even more confidence to choose the language that best fits your application’s requirements.
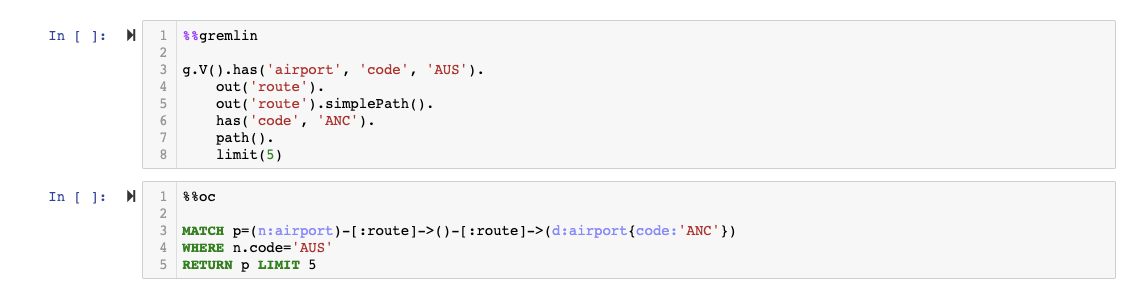
In the following code example, we find up to five routes consisting of two flights from Austin to Anchorage in openCypher, declaratively, and Gremlin, imperatively.
{kind=link}
It’s Day One for graphs, and it’s the beginning of openCypher’s journey with Neptune. We chose to release it in lab mode as soon as we had a core set of features in order to get feedback from customers on how the language can help them to build graphs. We learned from customers that most openCypher graph applications not only use the query language, but also need other functionalities like stored procedures or libraries. For Neptune, the ability to write Gremlin traversals over the same data helps to fill this role. Gremlin provides imperative traversal capabilities that are great when you need specific, programmatic graph operations. openCypher gives you a declarative model to quickly write queries in the style of SQL. Property graph applications can be better with both languages used together over the same data. The Neptune Lab mode is a way for you to try out openCypher support, but it’s by no means complete yet. The general availability of openCypher, planned for later this year, will make significant language coverage and performance improvements.
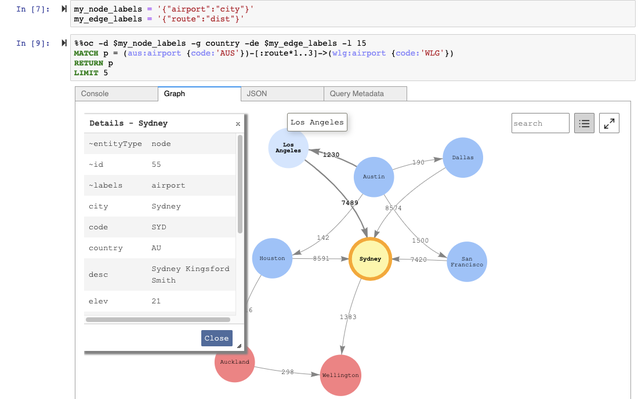
Along with this release, we’ve also added support for openCypher over the Bolt protocol within the AWS graph notebook, an open-source Jupyter notebook to help developers get started building graph applications. This allows you to issue openCypher queries and have a visual representation of the result (see the following screenshot).
{kind=link}
We have included sample notebooks and examples for all three query languages on GitHub. The graph notebook is included as part of the Neptune Workbench via the AWS Management Console. If you prefer to deploy the notebooks on your own machine, you can run pip install graph-notebook and begin issuing queries against Neptune or other graph databases that support Apache TinkerPop, openCypher, or SPARQL 1.1 to get started. If you’re already using the graph notebook, you can update it by running pip install graph-notebook —upgrade to get the latest capabilities.
Summary
If you’re curious about graph databases, want to learn how to get more value from the relationships in your data, or are an experienced graph database user, try out your graph with Neptune and openCypher. You can create a new Neptune cluster or upgrade an existing cluster to engine release 1.0.5.0 or greater. After you try it out, let us know how it works for you so we can learn and iterate quickly.
You want to use graphs to find insights into your relationships; let’s make it easy for application builders.
About the Author
Brad Bebee is the General Manager of Amazon Neptune at AWS. He believes that graphs are awesome and they help customers use the relationships in their data to gain insights. If you agree or want to find out, let him know @b2ebs (Twitter).
{kind=link}
Read MoreAWS Database Blog