

{kind=link}
Today marks the one-year anniversary of the launch of Amazon MemoryDB for Redis. On 8/19/2021, AWS announced the general availability of Amazon MemoryDB for Redis, a fully managed, Redis-compatible database, that delivers both in-memory performance and Multi-AZ durability.
Over the past year, thousands of customers have adopted MemoryDB as their primary database for critical workloads that need extreme performance. Customers across industries like Fin-Tech, Smart Home, and Internet Services are using MemoryDB as an ultra-fast, primary database powering use cases like user session data, financial tokens, message streaming between microservices, gaming state, and leaderboards, and IoT. Since launching the service, we’ve delivered a number of capabilities including a 2-month free trial, native JSON (JavaScript Object Notation) support, a dev preview of AWS Controllers for Kubernetes (ACK) for Amazon MemoryDB, and Redis 6.2.6 support. Hot off the press, we recently announced PCI DSS and HIPAA compliances for MemoryDB.
MemoryDB is purpose-built for cloud-native applications, delivering ultra-fast performance using in-memory storage and a Multi-AZ transactional log for data durability. In this post, I want to share an example of how customers can use MemoryDB to provide an ultra-fast shared state in their serverless applications running on AWS Lambda.
Solution overview
Lambda is a serverless, event-driven compute service that lets you run code without provisioning or managing servers. Lambda runs your code on a high-availability compute infrastructure and performs all of the administration of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, code monitoring, and logging. With Lambda, you can run code for virtually any type of application or backend service. All you need to do is supply your code in one of the languages that Lambda supports.
Lambda functions often need a database to store data like user sessions or function states across invocations. MemoryDB is a database purpose-built for applications that need ultra-fast performance, and is a great choice for persistent shared state for Lambda functions. You can create a MemoryDB endpoint in your VPC. A Lambda function always runs inside a VPC owned by Lambda. Lambda applies network access and security rules to this VPC and maintains and monitors the VPC automatically. To enable access to your MemoryDB cluster, you will need to configure your Lambda function’s VPC and security settings.
In this post, I explain how you can set up a Lambda function using a Redis client to access MemoryDB, and configure your Lambda function to access your MemoryDB database.
Create a MemoryDB database
First, you create a new MemoryDB database in a few simple steps. Complete the following steps:
On the MemoryDB console, choose Clusters in the navigation pane.
Choose Create cluster.
For Name, enter the name of your cluster.
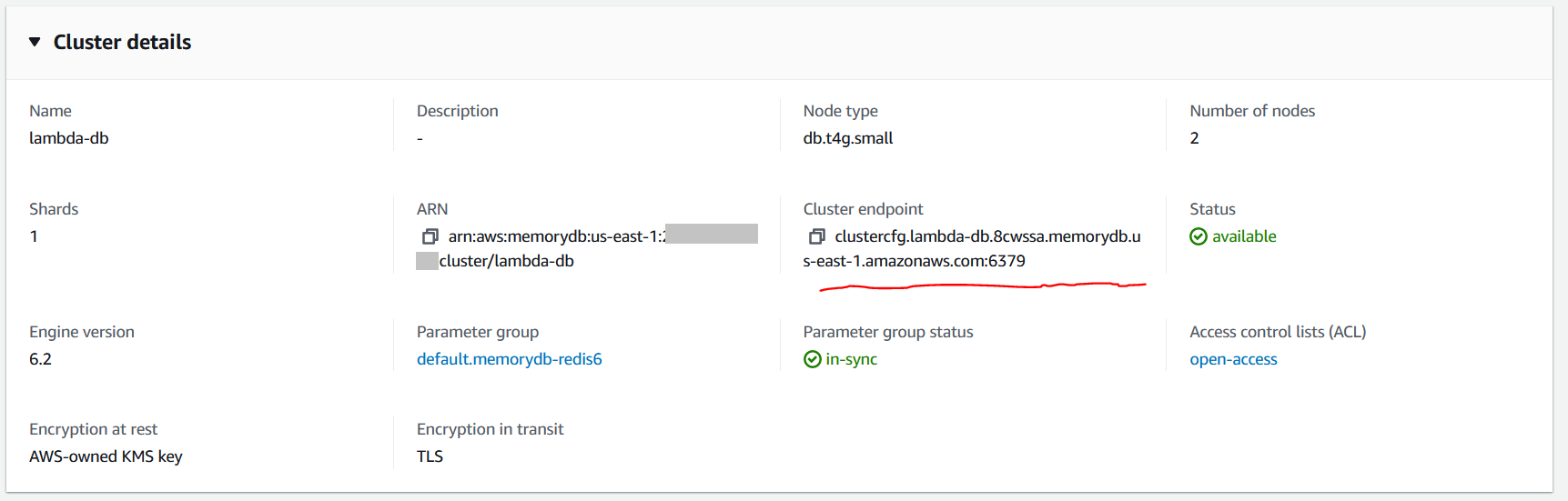
For Subnet groups, select Choose existing subnet group and choose a subnet group for your MemoryDB database.The subnet group you choose specifies which VPC your MemoryDB cluster will be accessible from. It also decides the Availability Zones where MemoryDB instances are placed. In this example, I use a previously created subnet group with three Availability Zones with VPC ID vpc-9a4237e7. Note this VPC ID. You create your Lambda function in the same VPC in a later step.
In the Cluster settings section, choose your cluster settings, including the node type, number of shards, and number of replicas per shard. For this example, I am using the db.t4g.small node type because it is right sized for a test database. For production workloads, I recommend choosing the right node type based on your expected database size. Read replicas help you scale your read throughput without overburdening the primary node in the shard. You should choose the right number of replicas depending on your read throughput. Learn more about selecting the right nodes and number of replicas for your cluster here. For this test, I have chosen a single shard, and 1 replica per shard.
Choose Next.
Under Inbound rules, choose your security settings.
If you don’t already have one, create a new security group. Clients connect to MemoryDB using the TCP protocol on port 6379 by default. Make sure your security group allows clients to connect on this port. You can enable this by adding a new inbound rule with the settings shown in the following screenshot. This allows any client in the same security group to connect to port 6379 using TCP.
Choose Save rules.
In the Advanced settings section, choose your security group and specify its encryption settings.
Choose your settings for maintenance windows and backup, and choose Create cluster. This creates a new MemoryDB database in a few minutes.
After the MemoryDB database has been created, note the cluster endpoint in the cluster settings. You will configure this endpoint in the next step.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Create a node project with a Redis client
In this step, you create a new Node project using ioredis, a Redis client for Node.js. I walk through all the steps to install Node.js, the Redis client, and a sample code to connect to MemoryDB.
Install node version manager (nvm) by entering the following at the command line:
Activate nvm:
Use nvm to install the latest version of Node.js:
Test that Node.js is installed and running correctly:
This displays the following message that shows the version of Node.js that is running:
Install the latest node package manager (npm):
Create a new folder for your project and inside your folder, create a node project:
Install the Redis client:
Now, you can create the index.js file. Replace the MemoryDB endpoint URL in the following code:
This sample code connects to your MemoryDB cluster and sets new a key-value pair of foo and bar. The code also returns the value of the key foo as a response to be printed by your Lambda function.
Package up your code, including the Redis client dependency, so that it can be uploaded into Lambda. In your project folder, create a .zip file with the following command:
Create a new Lambda function
In this step, you create a new Lambda function. Because MemoryDB operates in a VPC, we must configure the Lambda function to be able to access resources in a VPC.
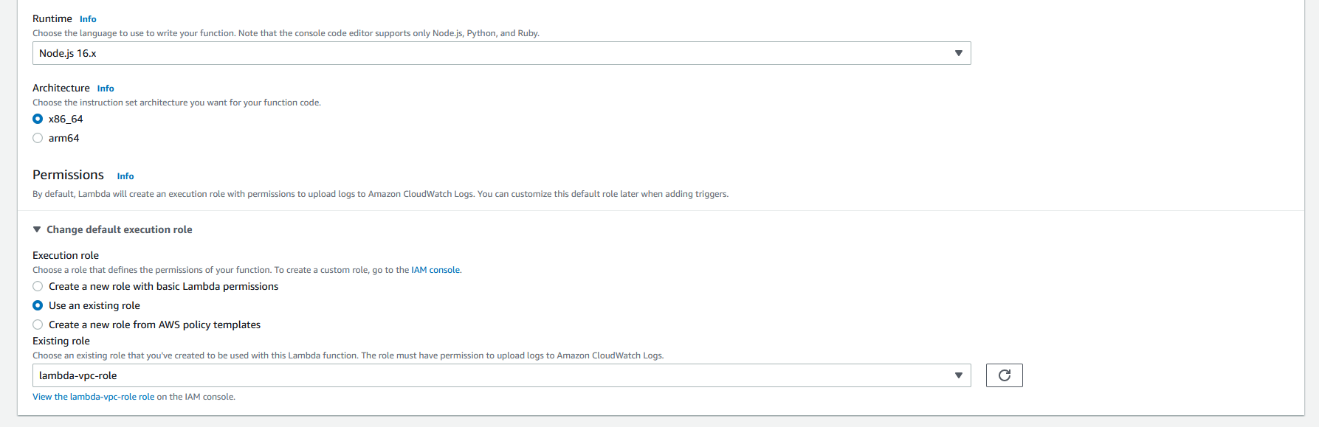
Create the execution role
To create an AWS Identity and Access Management role for Lambda, complete the following steps:
On the IAM console, choose Roles in the navigation pane.
Choose Create role.
For Trusted entity type, choose AWS Service.
For Use case¸ choose Lambda.
Choose Next.
Search for the permissions policy AWSLambdaVPCAccessExecutionRole and choose it.
Choose Next.
Provide a role name like lambda-vpc-role.
Choose Create role.
Create a new Lambda function
Now you’re ready to create your Lambda function.
On the Lambda console, choose Functions in the navigation pane.
Choose Create function.
For Function name, enter a name for your function.
For Execution role, select Use an existing role and choose the role you just created.
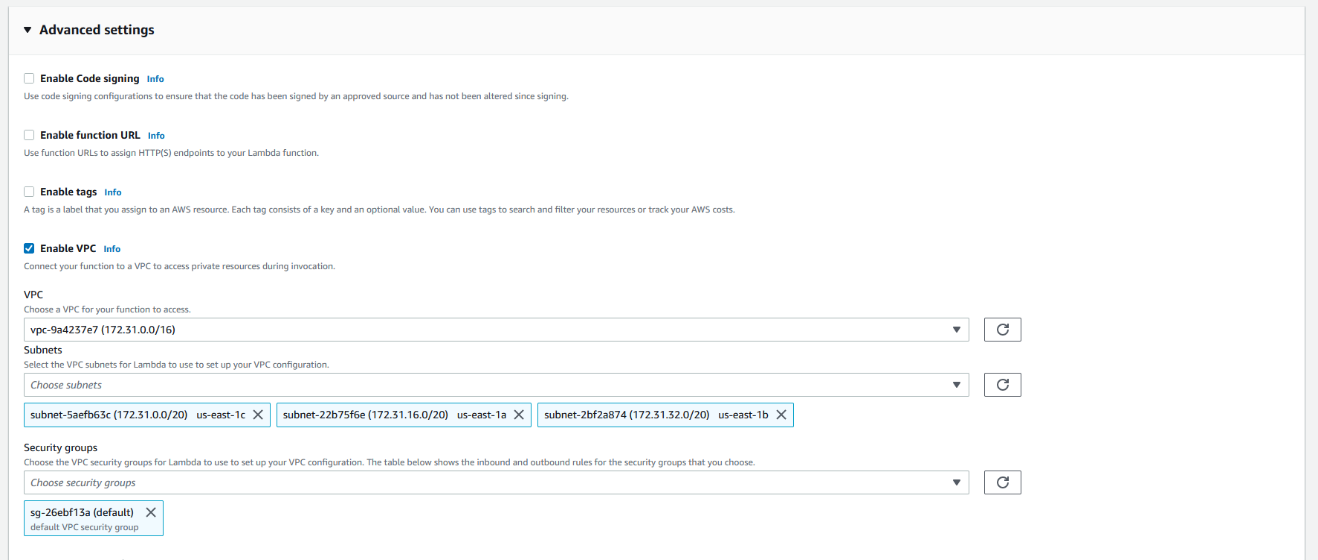
Expand Advanced Settings. Here you connect your Lambda function to a VPC so that it can access your MemoryDB cluster.
Select Enable VPC.
Choose the VPC that you created (the same VPC that you chose when creating your MemoryDB cluster).
Choose the VPC subnets for your Lambda to use.
Choose the security group for your Lambda (the same security group you selected when creating your MemoryDB cluster).
Choose Create function.
{kind=link}
{kind=link}
{kind=link}
This creates a blank function for you.
Deploy your function
Next, you deploy your code to your Lambda function by uploading the .zip file you created earlier.
There are two ways to do this. You can directly upload the .zip file if you have it stored locally on your machine. Alternatively, you can upload the file to Amazon Simple Storage Service (Amazon S3) and import it into Lambda.
{kind=link}
Next, you’re ready to test your code. On the Test tab of your function, choose Test.
{kind=link}
Your Lambda function should successfully connect to MemoryDB. Your code will have written the key-value pair foo and bar to MemoryDB, and returned the value to be printed as output in your Lambda function.
{kind=link}
Congratulations! Your Lambda function can now insert and read data from your MemoryDB database.
Clean up
Now that we have seen an example in action, let’s clean up our work. Complete the following steps to clean up your Lambda function and MemoryDB database:
On the Lambda console, choose Functions in the navigation pane.
Select the function you created.
On the Actions menu, choose Delete.
On the MemoryDB console, choose Clusters in the navigation pane.
Select the cluster you created.
On the Actions menu, choose Delete.
Conclusion
In this post, I showed how you can create and configure your Lambda function to access your MemoryDB cluster. Your Lambda functions can now store data durably across function invocations in a database that is Redis-compatible, and offers ultra-fast read and write performance. I manually set up the MemoryDB cluster from the AWS Management Console, but you can also set up your MemoryDB cluster programmatically using the MemoryDB API. You can also define and manage MemoryDB resources directly from your Kubernetes cluster using the AWS Controller for Kubernetes for MemoryDB.
I’m excited to see how you will use MemoryDB to store data from your Lambda functions. You can get started with MemoryDB with a free 2-month trial. If you have questions or feature requests, email us at [email protected].
About the author
Abhay Saxena is a Product Manager for Amazon MemoryDB for Redis in the In-Memory Databases team at Amazon Web Services. He works with AWS customers to identify needs where customers might benefit from ultra-fast performance from In-memory databases. Prior to joining the MemoryDB team, Abhay has been at Amazon as a Product Manager for over 13 years.
Read MoreAWS Database Blog