

{kind=link}
Graph databases are uniquely designed to address query patterns focused on relationships within a given dataset. From a relational database perspective, graph traversals can be represented as a series of table joins, or recursive common table expressions (CTEs). Not only are these types of SQL query patterns computationally expensive and complex to write (especially for highly connected datasets that involve multiple joins), but they can be difficult to tune for performance.
Amazon Neptune provides a means to address these gaps. Neptune is a fully managed graph database with a purpose-built, high-performance graph database engine that is optimized for storing billions of relationships and running transactional graph queries with millisecond latency.
However, there are situations where we can achieve even better performance through the use of various caching techniques. Caching, or the ability to temporarily store data in memory for fast retrieval when read more than once, is a technique as old as computing itself and used broadly across many database platforms.
In this three-part series, we discuss how to improve your graph query performance using a variety of caching techniques with Neptune. Part one sets the scene by discussing the Neptune query process and how the buffer pool cache works. In part two, we discuss the additional Neptune caches (query results cache and lookup cache) and how they can improve performance for use cases with repeat queries, pagination, and queries that materialize large quantities of literals. In part three, we show how to implement Neptune cluster-wide caching architectures with Amazon ElastiCache, which benefits use cases where the results cache should be at the cluster level, use cases that require dynamic sorting of large result sets, or use cases that want to cache the query results of any graph query language.
We first review the workflow of running a Neptune query. This background will provide further insight into when to use different caching capabilities. It will also be useful later when we discuss other methods for caching outside of Neptune’s native caching features.
Data storage design
Neptune is built on a decoupled compute and storage architecture that is designed to run within the context of a cluster. When you create a Neptune graph database, you do so by creating a Neptune cluster comprised of managed Amazon Elastic Compute Cloud (Amazon EC2) instances and an underlying shared storage volume. These EC2 instances make up the compute layer, which receives and processes graph queries. The shared storage volume makes up the storage layer, which stores the graph data. To the user, this shared storage volume appears as nothing more than usable storage capacity, which is initially allocated with 10 GB of storage capacity and dynamically grows up to 128 TiB as a user writes data into their cluster. The following diagram illustrates this setup.
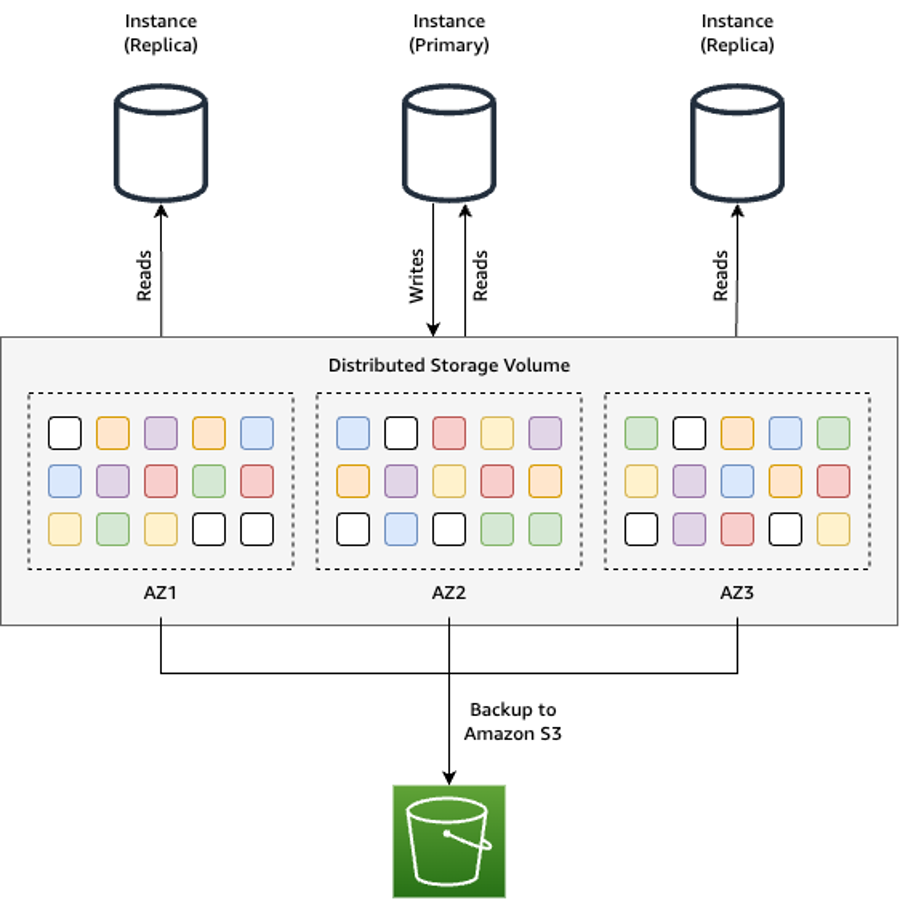{kind=link}
Within the underlying shared storage volume, data is stored as a set of indexes and a separate dictionary index, or property store. Each component within the graph—such as a vertex, edge, property, or RDF triple—is automatically indexed as part of the Neptune graph data storage model. Literal values (strings) associated with these objects are stored in a separate property store. When a query is run, Neptune’s query engine uses the indexes to optimally compute the result of the graph query. The result set is then materialized by fetching in requested values from the property store. In the majority of cases, query computation within the index store makes up most of the query runtime.
Query run I/O path and the buffer pool cache
The managed EC2 instances within the cluster sit atop the storage volume and send both read and write requests to the storage layer for fetching and persisting data, respectively. The instances are used solely for running the requests sent to the cluster. Data is not persisted on these instances, only within the shared storage volume. These instances do, however, keep a copy of the most recently used parts of the graph in their memory space, called the buffer pool cache. Like other databases, this allows Neptune to take advantage of the principle of temporal locality.
When Neptune is looking for the graph components (graph nodes, edges, and properties) required to answer your query, it first looks for those objects in the instance’s buffer pool cache. If those objects are found in the buffer pool cache, it fetches those objects from memory and computes the results of the query. We refer to this event as a buffer pool cache hit. If the data is not in the buffer pool cache, the instance requests this data from the underlying shared storage volume. We call this a buffer pool cache miss. Once fetched, it computes the results of the query and saves a copy of the fetched objects in the buffer pool cache for use by later queries. The buffer pool cache hit ratio can be tracked via the Amazon CloudWatch metric BufferCacheHitRatio, which measures the percentage of requests that are able to be served by the buffer pool cache.
The buffer pool cache is a feature that is always on a Neptune instance. It stores as much of the graph as possible within the cache, which is approximately two-thirds of an instance’s available memory. Graph components are only cached if they are used—a newly added instance will have an empty buffer pool cache until the first graph query is run. If the buffer pool cache begins to reach capacity, the Neptune instance uses a least recently used (LRU) eviction policy to clear least recently used objects for more recently fetched objects to be stored in the cache.
The following diagram illustrates this process.
Summary
The Neptune buffer pool cache is a feature that is always on, and helps optimize query performance by caching the most recently used graph components. The buffer pool cache provides the most benefit for workloads that are able to keep their working set in memory, such as workloads whose queries are frequently accessing the same portions of the graph.
Although the buffer pool cache accelerates the majority of transactional query patterns that we see being used within Neptune, there are situations where the buffer pool cache has little effect on improving performance—namely, when you have queries where the majority of the runtime is spent computing the query result rather than fetching the graph data needed to answer the query.
In part two of this series, we discuss how you can use two additional Neptune caching features, the query result cache and the lookup cache, to accelerate performance for those types of queries.
About the Authors
Taylor Riggan is a Sr. Graph Architect focused on Amazon Neptune. He works with customers of all sizes to help them learn and use purpose-built, NoSQL databases. You can reach out to Taylor via various social media outlets such as Twitter and LinkedIn.
Abhishek Mishra is a Sr. Neptune Specialist Solutions Architect at AWS. He helps AWS customers build innovative solutions using graph databases. In his spare time, he loves making the earth a greener place.
Kelvin Lawrence is a Sr. Principal Graph Architect focused on Amazon Neptune and many other related services. He has been working with graph databases for many years, is the author of the book Practical Gremlin, and is a committer on the Apache TinkerPop project.
Melissa Kwok is a Neptune Specialist Solutions Architect at AWS, where she helps customers of all sizes and verticals build cloud solutions with graph databases according to best practices. When she’s not at her desk, you can find her in the kitchen experimenting with new recipes or reading a cookbook.
Read MoreAWS Database Blog