

{kind=link}
Database object validation plays a key role in the database migration process. It’s the process of determining whether all the source database objects have been successfully migrated to the target database by comparing their types and counts. If you miss the validation phase, you may encounter run time errors due to missing database objects which can be a blocker for unit testing and code deployments.
For database migration, you can use the AWS Schema Conversion Tool (AWS SCT) to convert your existing database schema from one database engine to another. AWS Database Migration Service (AWS DMS) then migrates the data from source to target after converting the schema. These migrated database objects should be validated to ensure a successful migration.
AWS SCT generates assessment reports that show the complexity of the code and the effort required to migrate to the target database. This report identifies the percentage of code that can be converted automatically and the code that needs manual effort. Because schema migration with AWS SCT isn’t a fully automated process, validation plays a crucial role in delivering a successful migration.
Although AWS DMS has integrated data validation, best practice dictates that we should validate the schema objects converted by AWS SCT prior to migrating any data. In this post, we explain how to validate the database schema objects migrated from Microsoft SQL Server to Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition.
Database object validation
The following list contains the various types of database objects that we validate using their counts and detail-level information, which helps us identify missing or partially migrated database objects. We ignore the system schemas in the source and target databases.
Schemas
Tables
Views
Stored Procedures
Functions
Indexes
Triggers
Constraints
Sequences
Let’s dive deep into each object type and its validation process. We can use SQL Server Management Studio to connect Microsoft SQL Server database and pgAdmin to connect Amazon RDS for PostgreSQL or Aurora PostgreSQL database and run the following queries to validate each object.
Schemas
Schemas are used to represent a collection of database objects that serve a related functionality in an application or a micro service. You can validate the schemas at the source and target databases using SQL queries.
For SQL Server, use the following query:
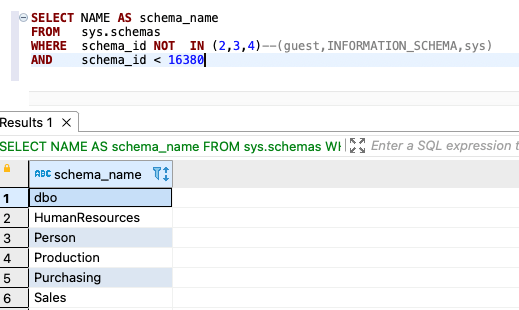{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, you have two query options. The following code is the first option:
The following screenshot shows our output:
{kind=link}
The following code is the second option:
The following screenshot shows our output:
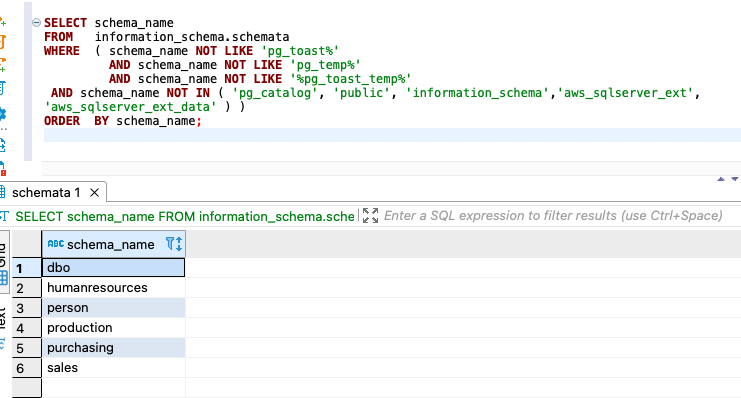{kind=link}
When you convert your database or data warehouse schema, AWS SCT adds an additional schema to your target database. This schema implements SQL system functions of the source database that are required when writing your converted schema to your target database. This additional schema is called the extension pack schema. You can directly deploy these schemas to the target database after verifying the native equivalent options in both the source and target databases.
When migrating database from Microsoft SQL Server to Amazon RDS for PostgreSQL or Aurora PostgreSQL, AWS SCT creates these extension packs – aws_sqlServer_ext and aws_sqlServer_ext_data.
Tables
AWS SCT converts source SQL Server tables to the equivalent target (PostgreSQL) tables with appropriate data types and relative table definitions using the default or custom mapping rules applied. The following scripts return the counts and detail-level information for all the tables, assuming the source database doesn’t have any partitioned tables.
For SQL Server, use the following code:
The following screenshot shows our output:
{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following query for counts:
The following screenshot shows our output:
{kind=link}
Views
You can validate the views count converted by AWS SCT by using the following queries on the source and target databases.
For SQL Server, use the following code:
The following screenshot shows our output:
{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, you have two options. The following code is the first option:
The following screenshot shows our output:
{kind=link}
The following code is the second option:
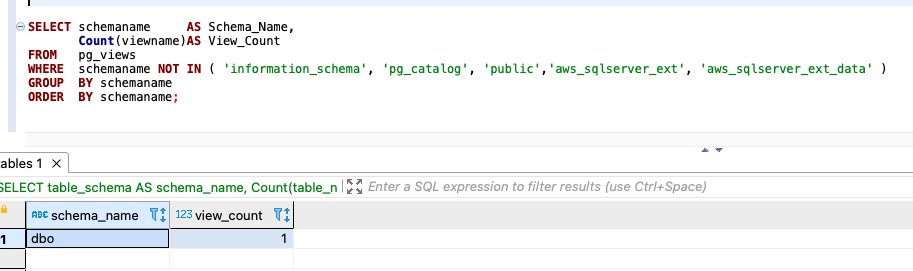{kind=link}
Stored procedures
In SQL Server, we use stored procedures to perform operations like Data Definition Language (DDL) such as CREATE, ALTER, and DROP, and Data Manipulation Language (DML) such as INSERT, UPDATE, DELETE, and the functions to retrieve the data.
While in PostgreSQL, we use functions to perform DDL and, DML operations, and to retrieve data.
For SQL Server, use the following code for counts:
The following screenshot shows our output:
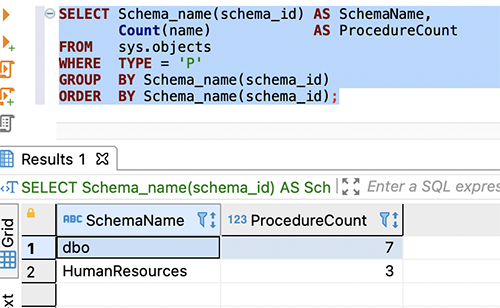{kind=link}
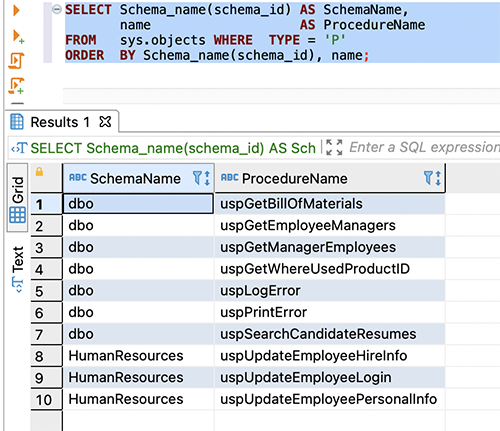
Use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following query for detail-level information:
The following screenshot shows our output:
{kind=link}
The preceding screenshot shows, there are no procedures created at the target database. They are converted as functions in PostgreSQL.
AWS SCT provides an option to convert the source stored procedures to functions or stored procedures in the PostgreSQL database. You should convert stored procedures to functions on PostgreSQL because PostgreSQL stored procedures have limitations.
Functions
Given the limitations of stored procedures and functions in PostgreSQL, we convert some of the stored procedures to functions. This count gets added to the already existing functions count in the source database. In both the source and target databases, the following queries provide counts and detail-level information about the functions.
For SQL Server, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
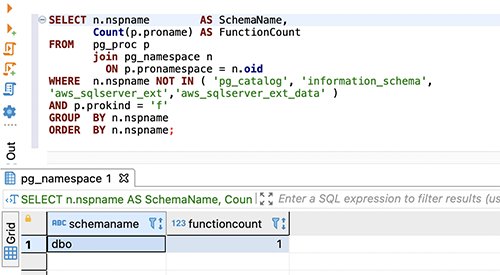
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following code for counts:
The following screenshot shows our output:
{kind=link}
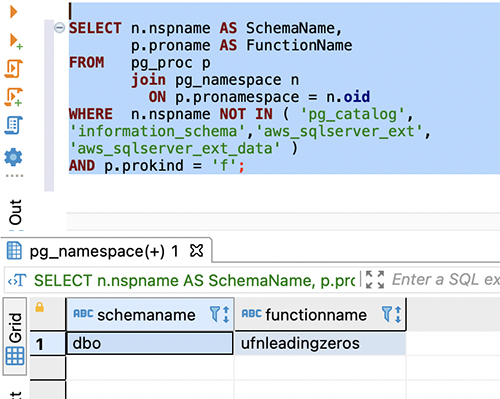
Use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
Indexes
Indexes play a key role in improving query (performance). Because tuning methodologies differ from database to database, the number of indexes and their types vary with SQL Server and PostgreSQL databases based on different use cases, so index counts also may differ.
With the following scripts, you can get the counts of indexes and their types in both SQL Server and PostgreSQL databases.
For SQL Server, use the following code:
The following screenshot shows our output:
{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
Triggers
Triggers help you audit the DMLs or DDL changes in the database. They can also impact performance based on the usage in appropriate areas. The following queries give you the count and details of triggers, for both the source and target databases.
For SQL Server, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
These keys should be turned off, before performing AWS DMS migration.
Constraints (primary key, foreign key, unique key, check & default)
Along with database object’s validation, you need to ensure the data is consistent and bound to integrity. Different types of constraints provide you with the flexibility to control and check the data during insertion to avoid run time data integrity issues.
Primary keys
Primary keys allow you to have unique values for columns, which prevents information from being duplicated, following the normalization process.
This key helps improve the search based on the key values, and avoid table scans.
The following queries help you extract the counts and details of primary keys in source and target databases.
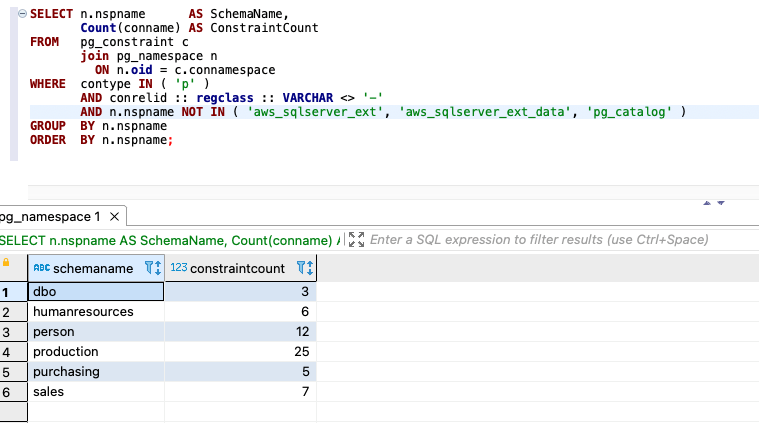
For SQL Server, use the following code for counts:
The following screenshot shows our output:
{kind=link}
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following code for counts:
Use the following code for detail-level information:
{kind=link}
Foreign keys
Foreign keys help you identify the relations between the tables, which you can use to form database normalized forms that store relevant data in appropriate tables. These keys should be turned off, before performing the AWS DMS migration.
With the following queries, you get the counts and detail-level information about the foreign keys in both the source and target databases.
For SQL Server, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
{kind=link}
Unique keys
Using unique keys restricts the uniqueness of data in the column and prevents duplicate values. You can use this key can be used to avoid data redundancy, which indirectly helps with appropriate data storage and retrieval. With the following queries, you get the counts and detail level information about the unique keys in both the source and target databases.
For SQL Server, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
The following screenshot shows our output:
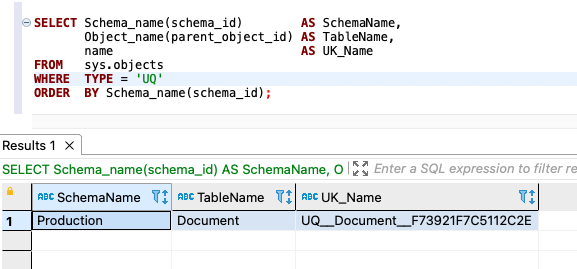{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following code for counts:
The following screenshot shows our output:
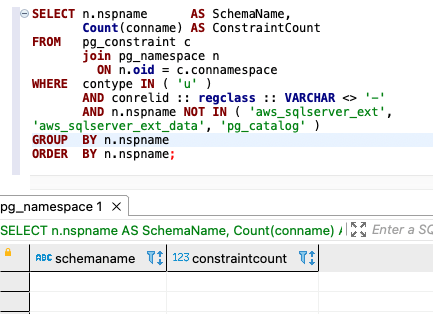{kind=link}
Use the following code for detail-level information:
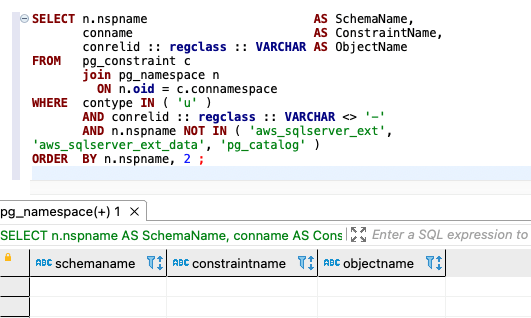{kind=link}
Check constraints
The check constraint assists you in validating the inserted or updated data in accordance with the business rules specified in the column. You can add these to a new or existing table with the appropriate data.
The following queries return counts and detail-level information about check constraints in source and target databases.
For SQL Server, you have options for both queries. Firstly, you can use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
The following screenshot shows our output:
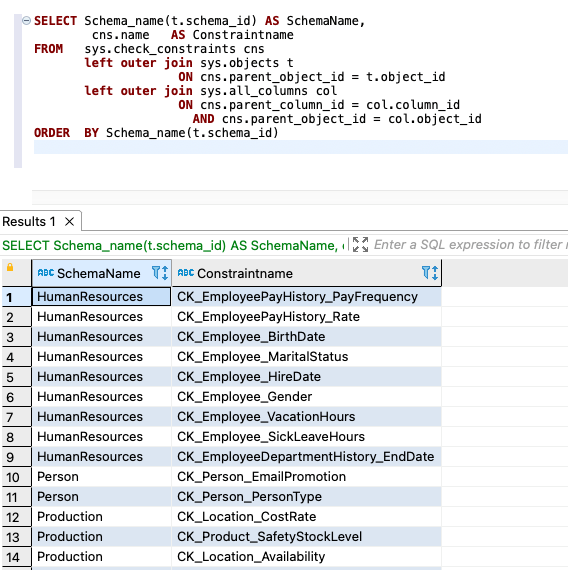{kind=link}
Alternatively, use the following code for counts:
The following screenshot shows our output:
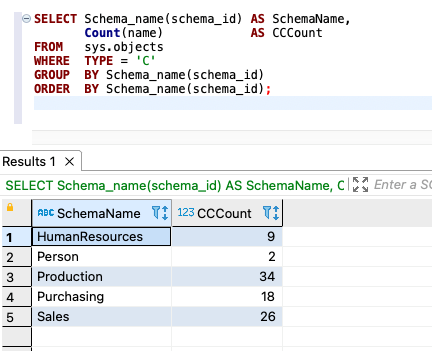{kind=link}
You can also use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
{kind=link}
Default constraints
Default constraints help you insert or update default values into the relative columns, based on the business requirements. The following queries help find the counts and detail-level information of default constraints in the source and target databases.
For SQL Server, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
{kind=link}
Sequences
Sequences help you create and increment integer values for columns based on given ranges and order. Unlike identity columns, sequences aren’t associated with specific tables. Applications refer to a sequence object to retrieve its next value. The relationship between sequences and tables is controlled by the application. User applications can reference a sequence object and coordinate the values across multiple rows and tables.
The following queries help you get the counts and detail-level information of sequences available in the source and target databases.
For SQL Server, use the following code for counts:
The following screenshot shows our output:
{kind=link}
Use the following code for detail-level information:
The following screenshot shows our output:
{kind=link}
For Amazon RDS for PostgreSQL or Aurora PostgreSQL, use the following code for counts:
The following screenshot shows our output:
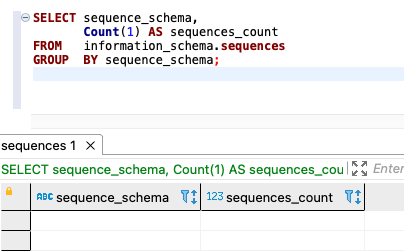{kind=link}
Use the following code for detail-level information:
{kind=link}
Useful PostgreSQL catalog tables
The following table summarizes a few of the SQL Server and PostgreSQL system or catalog tables and views that are useful for database object validation. These tables and views hold the metadata about various database objects and their details, which you can use for the validation.
SQL Server
PostgreSQL
Sys.tables/sys.objects/Information_Schema
pg_tables
information_schema.tables
Sys.views/ sys.objects/ Information_Schema
pg_views
information_schema.views
Sys.sequences/ Information_Schema
information_schema.sequences
Sys.triggers/ sys.objects
information_schema.triggers
Sys.indexes
pg_indexes
information_schema.table_constraints/sys.objects
pg_constraint join to pg_namespace
Sys.objects/sys.procedures
information_schema.routines
Identify and fix the missing objects
The queries in this post can help you identify missing database objects during migration from the source to the target database. You can use the query results to perform a comparison to identify the gaps in database objects. This narrows down the focus on the missing objects of the migration. You can use the queries iteratively after you fix the missing objects until you achieve a desired state.
Conclusion
Validating database objects is essential to providing database migration accuracy and confirming that all objects have been migrated correctly. Validating all the database objects helps you ensure target database integrity, thereby allowing your application to function as seamlessly as it did on the source database.
In this post, we discussed post-migration validation of database objects. Following the database migration from SQL Server to Amazon RDS for PostgreSQL or Aurora PostgreSQL, we clarified the significance of the validation process and types of database objects validated, boosting the confidence level of the migrated databases. In case of errors, this solution also helps you identify, it also assists you in identifying the missing or unmatched objects post-migration.
If you have questions or suggestions, leave a comment.
About the Authors
Sai Krishna Namburu is a Database Consultant with AWS Professional Services based out of Hyderabad, India. With good knowledge on relational databases adding hands-on in homogenous and heterogenous database migrations, he helps the customers in migrating to AWS cloud and their optimizations. Enthusiastic about new technologies around the databases and process automation areas. Interested in open source technologies, data analytics and ML which enhances the customer outcome.
{kind=link}
Shyam Sunder Rakhecha is a Database Consultant with the Professional Services team at AWS based out of Hyderabad, India and specializes in database migrations. He is helping customers in migration and optimization in AWS cloud. He is curious to explore emerging technology in terms of Databases. He is fascinated with RDBMS and Big Data. He also love to organize team building events and regalement in team.
{kind=link}
Tirumala Rama Chandra Murty Dasari is a Database Consultant with AWS Professional Services (Hyderabad, India). With extensive knowledge on relational and non-relational databases, helps the customer migrations to AWS cloud. Curious to learn and implement new technologies which reflects the customer success. Automates the manual process and enhances the existing using relevant technologies.
{kind=link}
Read MoreAWS Database Blog