

{kind=link}
Multi-object tracking (MOT) in video analysis is increasingly in demand in many industries, such as live sports, manufacturing, surveillance, and traffic monitoring. For example, in live sports, MOT can track soccer players in real time to analyze physical performance such as real-time speed and moving distance.
Previously, most methods were designed to separate MOT into two tasks: object detection and association. The object detection task detects objects first. The association task extracts re-identification (re-ID) features from image regions for each detected object, and links each detected object through re-ID features to existing tracks or creates a new track. It’s challenging to do real-time inference in an environment with a large number of objects. This is because two tasks extract features respectively and the association task needs to run re-ID feature extraction for each object. Some proposed one-shot MOT methods add a re-ID branch to the object detection network to conduct object detection and association simultaneously. This reduces the inference time, but sacrifices the tracking performance.
FairMOT is a one-shot tracking method with two homogeneous branches for detecting objects and extracting re-ID features. FairMOT has higher performance than the two-step methods—it reaches a speed of about 30 FPS on the MOT challenge datasets. This improvement helps MOT find its way in many industrial scenarios.
Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to prepare, build, train, and deploy machine learning (ML) models quickly. SageMaker provides several built-in algorithms and container images that you can use to accelerate training and deployment of ML models. Additionally, custom algorithms such as FairMOT can also be supported via custom-built Docker container images.
This post demonstrates how to train and deploy a FairMOT model with SageMaker, optimize it using hyperparameter tuning, and make predictions in real time as well as batch mode.
Overview of the solution
Our solution consists of the following high-level steps:
Set up your resources.
Use SageMaker to train a FairMOT model and tune hyperparameters on the MOT challenge dataset.
Run real-time inference.
Run batch inference.
Prerequisites
Before getting started, complete the following prerequisites:
Create an AWS account or use an existing AWS account.
Make sure that you have a minimum of one ml.p3.16xlarge instance for the training job.
Make sure that you have a minimum of one ml.p3.2xlarge instance for inference endpoint.
Make sure that you have a minimum of one ml.p3.2xlarge instance for processing jobs.
If this is your first time training a model, deploying a model, or running a processing job on the previously mentioned instance sizes, you must request a service quota increase for SageMaker training job.
Set up your resources
After you complete all the prerequisites, you’re ready to deploy the necessary resources.
Create a SageMaker notebook instance. For this task, we recommend the ml.t3.medium instance type. The default volume size is 5 GB; you must increase the volume size to 100 GB. For your AWS Identity and Access Management (IAM) role, choose an existing role or create a new role, and attach the AmazonSageMakerFullAccess and AmazonElasticContainerRegistryPublicFullAccess policies to the role.
Clone the GitHub repo to the notebook you created.
Create a new Amazon Simple Storage Service (Amazon S3) bucket or use an existing bucket.
Train a FairMOT model
To train your FairMOT model, we use the fairmot-training.ipynb notebook. The following diagram outlines the logical flow implemented in this code.
{kind=link}
In the Initialize SageMaker section, we define the S3 bucket location and dataset name, and choose either to train on the entire dataset (by setting the half_val parameter to 0) or split it into training and validation (half_val is set to 1). We use the latter mode for hyperparameter tuning.
Next, the prepare-s3-bucket.sh script downloads the dataset from MOT challenge, converts it, and uploads it to the S3 bucket. We tested training the model using the MOT17 and MOT20 datasets, but you can try training with other MOT datasets as well.
In the Build and push SageMaker training image section, we create a custom container image with the FairMOT training algorithm. You can find the definition of the Docker image in the container-dp folder. Because this container image consumes about 13.5 GB volume, the prepare-docker.sh script changes the default directory of the local temporary Docker image in order to avoid the “no space” error. The build_and_push.sh command does just that—it builds and pushes the container to Amazon Elastic Container Registry (Amazon ECR). You should be able to validate the result on the Amazon ECR console.
Finally, the Define a training job section initiates the model training. You can observe the model training on the SageMaker console on the Training Jobs page. The model shows an In progress status first and changes to Completed in about 3 hours (if you’re running the notebook as is). You can access corresponding training metrics on the training job details page, as shown in the following screenshot.
{kind=link}
Training metrics
The FairMOT model is based on a backbone network with object detection and re-ID branches on top. The object detection branch has three parallel heads to estimate heatmaps, object center offsets, and bounding box sizes. During the training phase, each head has a corresponding loss value: hm_loss for heatmap, offset_loss for center offsets, and wh_loss for bounding box sizes. The re-ID branch has an id_loss for the re-ID feature learning. Based on these four loss values, a total loss named loss is calculated for the entire network. We monitor all loss values on both the training and validation datasets. During hyperparameter tuning, we rely on ObjectiveMetric to select the best-performing model.
When the training job is complete, note the URI of your model in the Output section of the job details page.
Finally, the last section of the notebook demonstrates SageMaker hyperparameter optimization (HPO). The right combination of hyperparameters can improve performance of ML models; however, finding one manually is time-consuming. SageMaker hyperparameter tuning helps automate the process. We simply define the range for each tuning hyperparameter and the objective metric, while HPO does the rest.
To accelerate the process, SageMaker HPO can run multiple training jobs in parallel. In the end, the best training job provides the most optimal hyperparameters for the model, which you can then use for training on the entire dataset.
{kind=link}
Perform real-time inference
In this section, we use the fairmot-inference.ipynb notebook. Similar to the training notebook, we begin by initializing SageMaker parameters and building a custom container image. The inference container is then deployed with the model we built earlier. The model is referenced via the s3_model_uri variable—you should double-check to make sure it links to the correct URI (adjust manually if necessary).
The following diagram illustrates the inference flow.
{kind=link}
After our custom container is deployed on a SageMaker inference endpoint, we’re ready to test. First, we download a test video from MOT16-03. Next, in our inference loop, we use OpenCV to split the video into individual frames, convert them to base64, and make predictions by calling the deployed inference endpoint.
The following code demonstrates this logic implemented with the SageMaker SDK:
The resulting video is stored in {root_directory}/datasets/test.mp4. The following is a sample frame. The same person in consecutive frames is wrapped by a bounding box with a unique ID.
{kind=link}
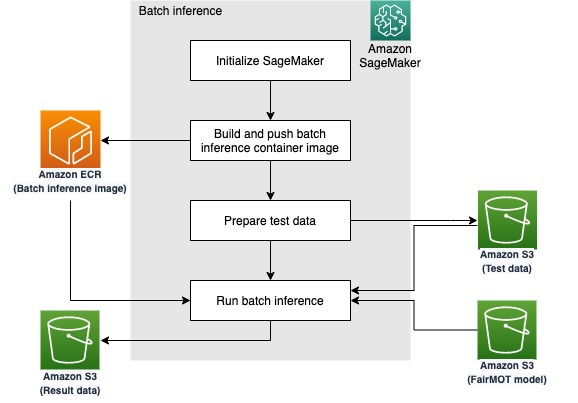
Perform batch inference
Now that we implemented and validated the FairMOT model using a frame-by-frame inference endpoint, we build a container that can process the entire video as a whole. This allows us to use FairMOT as a step in more complex video processing pipelines. We use a SageMaker processing job to achieve this goal, as demonstrated in the fairmot-batch-inference.ipynb notebook.
Once again, we begin with SageMaker initialization and building a custom container image. This time we encapsulate the frame-by-frame inference loop into the container itself (the predict.py script). Our test data is MOT16-03, pre-staged in the S3 bucket. As in the previous steps, make sure that the s3_model_uri variable refers to the correct model URI.
SageMaker processing jobs rely on Amazon S3 for input and output data placement. The following diagram demonstrates our workflow.
{kind=link}
In the Run batch inference section, we create an instance of ScriptProcessor and define the path for input and output data, as well as the target model. We then run the processor, and the resulting video is placed into the location defined in the s3_output variable. It looks the same as the resulting video generated in the previous section.
Clean up
To avoid unnecessary costs, delete the resources you created as part of this solution, including the inference endpoint.
Conclusion
This post demonstrated how to use SageMaker to train and deploy an object tracking model based on FairMOT. You can use a similar approach to implement other custom algorithms. Although we used public datasets in this example, you can certainly accomplish the same with your own dataset. Amazon SageMaker Ground Truth can help you with the labeling, and SageMaker custom containers simplify implementation.
About the Author
Gordon Wang is a Data Scientist on the Professional Services team at Amazon Web Services. He supports customers in many industries, including media, manufacturing, energy, and healthcare. He is passionate about computer vision, deep learning, and MLOps. In his spare time, he loves running and hiking.
{kind=link}
Read MoreAWS Machine Learning Blog